始于 2021年12月17日,出发点是为了让更多国人可以直观的学习并使用 Proxmox VE 。本译文极小部分的内容并未完全按照英文原版的内容进行直接翻译,可能存在个人主观上的理解和认知,如有发现不合适甚至错误的地方,请以英文原版为主。

Proxmox VE 管理员指南
<support@proxmox.com>
版本 7.1, 2021月11月15日 欧洲中部时间 16:07:34
翻译说明
—— 陈国清
↩ 索引
目录
始于 2021年12月17日,出发点是为了让更多国人可以直观的学习并使用 Proxmox VE 。本译文极小部分的内容并未完全按照英文原版的内容进行直接翻译,可能存在个人主观上的理解和认知,如有发现不合适甚至错误的地方,请以英文原版为主。
Proxmox VE 是一个运行虚拟机和容器的平台,基于 Debian Linux,完全开源。为了获得最大的灵活性,我们实现了两种虚拟化技术-基于内核的虚拟机(KVM)和基于容器的虚拟化(LXC)。
一个主要的设计目标是使管理尽可能简单。您可以在单个节点上使用 Proxmox VE,或将多个节点组成集群。所有管理任务都可以通过我们基于 Web 的管理界面来完成,即使是新手用户也可以在几分钟内安装 Proxmox VE 。

虽然很多人从单个节点开始,但 Proxmox VE 可以扩展为大型的集群化节点。集群堆栈(Stack)完全集成,并在默认安装中附带。
集成的基于 Web 的管理界面为您提供了所有 KVM 来宾和 Linux 容器甚至整个集群的清晰概览。您可以轻松的从 GUI 界面管理您的虚拟机(VM)(以下简称 VM)和容器(CT)(以下简称 CT)、存储或集群。无需安装单独、复杂且昂贵的管理服务器。
Proxmox VE 使用独特的 Proxmox 集群文件系统(pmxcfs),一个数据库驱动的文件系统用于存储配置文件。这可以让您存储数千个虚拟机的配置。通过使用 corosync ,这些文件可以在所有集群节点上实时复制。文件系统将所有数据存储在磁盘的持久数据库中,尽管如此,还是为驻留在内存中的数据副本提供了最大 30MB 的存储大小 - 对于数千个 VM 来说已经足够了。
Proxmox VE 是唯一使用这种独特的集群文件系统的虚拟化平台。
Proxmox VE 易于使用。通过包含的基于 Web 的管理界面来完成管理任务 - 无需安装单独的管理工具或任何具有大型数据库的额外管理节点。多主工具允许您从集群的任何节点管理您的整个集群。基于 Web 的集中式管理 - 基于 JavaScript 框架(ExtJS)- 使您能够从每个节点的概要、任务历史和系统日志(Syslog)中控制所有功能。这包括正在运行的备份或恢复作业、实时迁移或 HA 触发的活动。
对于习惯使用 Unix shell 或 Windows Powershell 的高级用户,Proxmox VE 为您提供了一个命令行界面来管理虚拟环境的所有组件。该命令行界面具有 Tab 智能补全和 UNIX 手册页形式的完整文档。
Proxmox VE 使用 RESTful API 。我们选择 JSON 为主数据格式,并且整个 API 使用 JSON Schema 正式定义。这样可以快速轻松地集成第三方管理工具,例如自定义托管环境。
您可以通过使用基于角色的用户和权限管理,来定义所有对象( VM 、存储、节点等)的精细访问。这允许您定义权限并帮助您控制对象的访问。这个概念也称为访问控制列表(即 ACL):每个权限在特定路径上指定一个主题(用户或组)和一个角色(权限集合)。
Proxmox VE 支持多种认证源,诸如 Microsoft 活动目录(AD)、LDAP、Linux PAM 标准认证或 Proxmox VE 内置的认证服务器。
Proxmox VE 的存储模型非常灵活。虚拟机映像可以存储在一个或多个本地存储中,或存储在诸如 NFS 和在 SAN 上的共享存储中。没有任何限制,您可以配置更多您想要定义的存储。可以使用在 Debian Linux 中可用的所有存储技术。
将虚拟机 VM 存储在共享存储上的主要优势是能够在不停机的实时迁移正在运行的虚拟机,而且集群中的所有节点都可以直接访问虚拟机 VM 的磁盘映像。
我们当前支持以下网络存储类型:
LVM 卷组(通过 iSCSI 目标进行网络备份)
iSCSI 目标
NFS 共享
CIFS 共享(也称作 SMB)
Ceph RBD
直接使用 iSCSI LUN
GlusterFS(一种集群式文件系统)
支持的本地存储类型:
LVM 卷组(通过类似的块设备、FC 设备、DRBD 等进行本地备份)
目录 (存储在现有文件系统上)
ZFS
集成的备份工具(vzdump)为运行中的容器和 KVM 来宾创建一致的快照。从根本上说,它创建了一个包含有 VM / CT 配置文件的 VM 或 CT 的数据存档。
KVM 实时备份适用于所有存储类型,包括 NFS、CIFS、iSCSI LUN、Ceph RBD 上的 VM 映像。新的备份格式经过优化,可以快速有效地存储 VM 的备份(稀疏文件、无序数据、最小化 I/O)。
一个多节点的 Proxmox VE HA 集群支持定义高可用性的虚拟服务器。Proxmox VE 的 HA 集群基于成熟的 Linux HA 技术,提供稳定可靠的 HA 服务。
Proxmox VE 使用桥接网络模型。如果每个来宾的虚拟网络电缆都插入同一交换机,则所有 VM 都可以共享一个网桥。为了将 VM 连接到外部世界,网桥连接到物理网卡并分配了一个 TCP/IP 配置。
为了进一步提高灵活性,可以使用 VLAN(IEEE 802.1q)和网络绑定(bond)/ 聚合。通过这种方式,可以为 Proxmox VE 主机构建复杂、灵活的虚拟网络,充分利用 Linux 网络堆栈的强大能力。
集成的防火墙允许您筛选任何 VM 或容器接口上的网络数据包。常见的一组防火墙规则可以组合为“安全群组”。
Proxmox VE 是一个虚拟化平台,它紧密集成了计算、存储和网络资源,管理高可用性集群,备份/恢复以及灾难恢复。所有组件都是软件定义,并且彼此兼容。
因此,可以通过集中式的 Web 管理界面,像单个系统一样管理它们。这些功能使得 Proxmox VE 成为部署和管理开源 超融合架构 的理想选择。
超融合架构(HCI)对于高架构需求满足低管理预算的部署、远程和分支机构办公环境等分布式设置、或虚拟私有云和公共云特别有用。
超融合架构(HCI)具有以下优势:
可扩展性:计算、网络和存储设备的无缝扩展(即快速、独立地扩展服务器和存储)。
低成本:Proxmox VE 是开源的,并集成了您需要的所有组件,例如计算、存储、网络、备份和管理中心。它可以取代昂贵的计算/存储基础设施。
数据保护和效率:集成了备份和灾难恢复等服务。
简单:易于配置和集中管理。
开源:没有供应商锁定。
Proxmox VE 为部署超融合存储架构提供了紧密集成的支持。例如,您可以仅使用 Web 界面来部署和管理以下两种存储技术:
Ceph:一个兼具自我修复和自我管理的共享、可靠和高度可扩展的存储系统。查看 如何在 Proxmox VE 节点上管理 Ceph 服务 。
ZFS:结合了文件系统和逻辑卷(LVM)管理器,具有广泛的数据损坏保护、各种 RAID 模式、快速且实惠的快照 - 以及其他大量的功能。了解 如何在 Proxmox VE 节点上利用 ZFS 的强大能力 。
除此之外,Proxmox VE 支持集成各种附加存储技术。您可以在 存储管理章节 中找到有关它们的信息。
Proxmox VE 使用 Linux 内核并基于 Debian GNU/Linux 发行版。Proxmox VE 的源代码根据 GNU Affero 通用公共许可证,版本 3 发布的。这意味着您可以随时检查源代码或为项目作出贡献。
在 Proxmox ,我们致力于尽可能的使用开源软件。使用开源软件确保对所有功能的完全访问 - 以及高安全性和可靠性。我们认为每个人都应该有权访问软件的源代码来运行它,在它的基础上构建,或者将更改提交回项目。我们鼓励每个人都做出贡献,同时 Proxmox 确保产品始终符合专业质量标准。
开源软件还有助于保持低成本并使您的核心基础设施独立于单一供应商。
开源软件
无供应商锁定
Linux 内核
快速安装且易于使用
基于 Web 的管理界面
REST API
庞大的活跃社区
低管理成本且易于部署
Proxmox VE Wiki 是信息的主要来源,它结合了参考文档和用户贡献的内容。
我们始终鼓励我们的用户使用 Proxmox VE 社区论坛 讨论和分享他们的知识。该论坛由 Proxmox 支持团队主持。庞大的用户群遍布全球,因此不用多说,这样的大型论坛是获取信息的好地方。
这是通过电子邮件与 Proxmox VE 社区进行交流的一种快速方式。
用户邮件列表:PVE User List
Proxmox VE 是完全开源的,欢迎贡献!开发人员的主要沟通渠道是:
开发者邮件列表:PVE development discussion
Proxmox Server Solutions GmbH 以 Proxmox VE 订阅服务计划 的形式提供企业支持。所有订阅用户都可以访问 Proxmox VE 的 Enterprise Repository(企业存储库),并且拥有 Basic、Standard 或 Premium 订阅的还可以访问 Proxmox 客户门户(Portal)。该客户门户可以在 Proxmox VE 开发人员保证的响应时间内提供帮助和支持。
如需批量折扣或更多常规信息,请联系 office@proxmox.com 。
Proxmox 在 https://bugzilla.proxmox.com 上运行一个公共的 bug 追踪器。如果出现问题,请在此处提交报告。此问题可以是一个 bug ,也可以是一个新功能或增强功能的请求。Bug 追踪器有助于该问题的跟进,并在问题解决后发送通知。
本项目于 2007 年开始,随后在 2008 年发布了第一个稳定版本。当时,我们为容器使用 OpenVZ,而为虚拟机使用 KVM 。集群功能有限,并且用户界面也简单(由服务器生成的网页)。
但是,我们使用 Corosync 集群堆栈快速开发了新功能,而且新的 Proxmox 集群文件系统(pmxcfs)的引入也是向前迈出了一大步,因为它完全向用户隐藏了集群的复杂性。管理 16 个节点的集群就像管理单个节点一样简单。
我们还引入了一个新的 REST API ,它具有用 JSON 模式编写的完整声明性规范。这使其他人能够将 Proxmox VE 集成到他们的基础设施中,并使得它易于提供附加服务。
此外,新的 REST API 使用一个现代的、运用 JavasScript 的 HTML5 应用程序代替原始的用户界面。我们也使用 noVNC 替换了旧的基于 Java 的 VNC 控制台代码。因此,您仅需要一个 Web 浏览器来管理 VM 。
另一项大任务是对各种存储类型的支持。值得注意的是,Proxmox VE 是在 2014 年默认第一个在 Linux 上发布 ZFS 的发行版。另一个里程碑是能够在管理程序的节点上运行并管理 Ceph 存储,这样的设备极具成本效益。
当我们开始时,我们是第一批为 KVM 提供商业支持的公司之一。KVM 项目自身不断发展,现在是一个广泛使用的管理程序。每个版本都会提供新功能。我们开发了 KVM 实时备份功能,使其在任何类型的存储上创建快照备份成为可能。
Proxmox VE 4.0 版本最显著的变化是从 OpenVZ 迁移到 LXC 。容器现在已深度集成,它们可以使用与虚拟机相同的存储和网络功能。
始终欢迎对 Proxmox VE 文档的贡献和改进,这里有几种贡献方式。
如果您在本文档中发现错误或其他有待改进的地方,请在 Proxmox bug 追踪器 中提交 bug,以提出更改建议。
如果您想提出新内容,请选择以下选项之一:
Wiki:对于特定的设置、操作指南或教程,wiki 是正确的选择。
参考文档:对于所有用户都有帮助的常规内容,请提出您对参考文档的贡献。这包括如何安装、配置、使用和故障排除等相关的 Proxmox VE 功能的所有信息。参考文档以 asciidoc 格式 编写。要编辑文档,您需要在 git://git.proxmox.com/git/pve-docs.git 克隆 git 仓库;然后按照 README.adoc 文档进行操作。
 |
如果您对使用 Proxmox VE 代码库感兴趣,开发者文档 wiki 文章将告诉您从哪里开始。 |
Proxmox VE 用户界面默认为英文。但是,感谢社区的贡献,也有翻译成其他语言。我们欢迎在添加新语言、翻译最新功能以及改进不完整或不一致的翻译方面提供任何支持。
您可以通过执行以下操作来创建新的翻译(将 <LANG> 替换为语言 ID):
# git clone git://git.proxmox.com/git/proxmox-i18n.git # cd proxmox-i18n # make init-<LANG>.po
或者您可以使用您选择的编辑器编辑现有翻译:
# poedit <LANG>.po
为了在 Proxmox VE 中使用翻译,您必须首先将 .po 文件转换为 .js 文件。您可以通过调用位于同一个存储库中的以下脚本来执行操作:
# ./po2js.pl -t pve xx.po >pve-lang-xx.js
然后将生成的文件 pve-lang-xx.js 复制到 Proxmox 服务器的目录 /usr/share/pve-i18n 中,以便对其进行测试。
或者,您可以通过从存储库的根目录运行以下命令生成一个 deb 软件包:
# make deb
 |
要使这些方法中的任何一种起作用,您需要在系统上安装以下 perl 软件。对于 Debian/Ubuntu : |
# apt-get install perl liblocale-po-perl libjson-perl
您可以将完成的翻译(.po 文件)连同签署的贡献许可协议一起发送到 Proxmox 团队的地址 office(at)proxmox.com 。或者,如果您有一些开发经验,您可以将其作为补丁发送到 Proxmox VE 开发邮件列表。请参阅 开发者文档 。
Proxmox VE 基于 Debian,所以 Proxmox 提供的安装映像(ISO文件)包含了完整的 Debian 系统以及所有必要的 Proxmox VE 软件包。

|
查看 在 FAQ 中的支持表 了解 Proxmox VE 版本和 Debian 版本之间的关系。 |
安装程序将指导您完成安装过程,允许您对逻辑磁盘进行分区、应用基本的系统配置(例如:时区、语言、网络等)、并安装所需要的软件包。此过程只需要花费几分钟时间,推荐新手或现有用户通过提供的 ISO 进行安装操作。
或者,可以安装 Proxmox VE 在现有 Debian 系统上,此选项仅建议详细了解 Proxmox VE 的高级用户使用。
我们推荐在生产环境使用高质量服务器硬件运行 Proxmox VE 。为了进一步减少故障主机的影响,您可以在具有高可用性(HA)的集群中运行 Proxmox VE 的虚拟机和容器。
Proxmox VE 可以使用本地存储(DAS),SAN,NAS 和分布式存储(如 Ceph RBD)。有关详细信息,请参阅 存储章节。
这些最低需求仅用于评估目的,不应用于生产环境。
CPU:64位处理器 (Intel EMT64 或 AMD64)
主板:支持 Intel VT/AMD-V CPU和支持 KVM 完全虚拟化的主板
内存:1 GB 内存,需为“来宾”增加额外的内存
硬盘:至少 1 个硬盘
网卡:至少 1 个网卡
带有 Intel VT/AMD-V CPU 标志的 Intel EMT64 或 AMD64 的处理器
内存:操作系统和 Proxmox VE 服务最少需要 2 GB,外加为“来宾”指定的内存。对于 Ceph 和 ZFS,需要额外的内存 - 每 TB 的已用存储大约需要 1GB 内存(即 1TB 存储 ≈ 1GB 内存)。
快速冗余存储,SSD 可实现最佳效果。
系统存储:使用带电池保护的写缓存 (“BBU”)的硬件 RAID 或带 ZFS 的非 RAID(ZIL 可选 SSD)。
虚拟机存储:
对于本地存储,要么使用带电池备份写缓存(BBU)的硬件 RAID,要么使用 non-RAID 的 ZFS 和 Ceph 。ZFS 与 Ceph 均与硬件 RAID 控制器不兼容。
可用的共享和分布式存储。
冗余 (多个) 千兆网卡,附加的网卡取决于首选的存储技术和集群设置。
对于直通 PCI(e) ,CPU 需要支持 VT-d/AMD-d 标志。
通过运行附带的 pveperf 工具,可以获得安装了 Proxmox VE 系统的 CPU 和硬盘性能的概况。
|
|
这只是一个非常快速和通用的基准测试。建议进行更详细的测试,尤其是有关系统 I/O 性能的测试。 |
要访问基于 Web 的用户界面,推荐使用以下浏览器之一:
Firefox 火狐浏览器,当年发布的最新版本,或最新的 ESR 版本
Chrome 谷歌浏览器,当年发布的最新版本
Microsoft Edge 浏览器,微软当前支持的版本
Safari 浏览器,当年发布的最新版本
当从移动设备访问时,Proxmox VE 将显示一个轻量级的基于触摸的界面。
Proxmox VE 安装介质是一个混合 ISO 映像,它有两种工作方式:
准备刻录到 CD 或 DVD 的 ISO 映像文件。
准备复制到 USB 闪存驱动器的原始扇区(IMG) 映像文件。
推荐使用 USB 闪存驱动器安装 Proxmox VE(这是更快的选项)。
闪存驱动器需要至少 1 GB 的可用存储空间。
|
|
不要使用 UNetbootin,它不适用于 Proxmox VE 安装映像。 |
|
|
确保 USB 闪存驱动器未安装且不包含任何重要数据。 |
在类 Unix 操作系统上使用 dd 命令复制 ISO 映像到 USB 闪存驱动器。首先找到 USB 闪存驱动器的正确设备名称(见下文)。然后运行 dd 命令。
# dd bs=1M conv=fdatasync if=./proxmox-ve_*.iso of=/dev/XYZ
|
|
确保使用正确的设备名称替换 /dev/XYZ,并调整输入的文件名路径 (if 后面) 。 |
 |
请非常小心,不要覆盖错误的磁盘! |
有两种方法可以找到 USB 闪存驱动器名称。第一种是通过 dmesg 命令,比较插入闪存驱动器之前与之后输出的最后几行内容。第二种方法通过比较 lsblk 命令的输出。打开一个终端并运行:
# lsblk
然后插入您的 USB 闪存驱动器并再次运行此命令:
# lsblk
将出现一个新设备,这就是您要用的。为了更安全起见,请检查报告的大小是否与您的USB闪存驱动器匹配。
打开终端 Terminal(在 Spotlight 中查询终端 Terminal)。
例如,使用 hdiutil 的 Convert 选项,将 .iso 文件转换为 .img 文件。
# hdiutil convert -format UDRW -o proxmox-ve_*.dmg proxmox-ve_*.iso
|
|
macOS 倾向于自动添加 .dmg 到输出文件名中。 |
要获取设备的当前列表,请运行以下命令:
# diskutil list
现在插入USB闪存驱动器并再次运行此命令,以确定已为其分配了哪个设备节点。(比如 /dev/diskX)
# diskutil list # diskutil unmountDisk /dev/diskX
|
|
将 X 替换为上一个命令中的磁盘号。 |
# sudo dd if=proxmox-ve_*.dmg of=/dev/rdiskX bs=1m
|
|
最后的命令中使用 rdiskX 代替 diskX 可以提高写入速度。 |
Etcher 开箱即用,从 https://etcher.io下载 Etcher,它将引导您完成选择 ISO 和 USB 驱动器的过程。
Rufus 是更轻量级的替代品,但是您需要使用 DD 模式 使其起到作用。从 https://rufus.ie/ 下载 Rufus,可以安装它或选择使用便捷版本。选择目标驱动器和 Proxmox VE ISO 文件。
|
|
单击 开始 以后,当有对话框询问是否下载不同版本的 GRUB 时,您必须单击 不 ,并在下一个对话框中选择 DD 模式。 |
此 ISO 安装映像包括以下内容:
完整的操作系统 (Debian Linux,64位)
Proxmox VE 安装程序,它使用 ext4,XFS,BTRFS(技术预览)或 ZFS 对本地磁盘进行分区,并安装操作系统。
Proxmox VE Linux 内核(支持 KVM 和 LXC)
用于管理虚拟机、容器、主机系统、集群和所有必要资源的完整工具集。
基于 Web 的管理界面
|
|
安装过程中将删除安装中所选驱动器的所有数据。安装程序不会为其它操作系统添加启动菜单项。 |
请插入准备好的安装介质(比如 USB 闪存驱动器 或 CD-ROM)并从它引导启动。
|
|
确保在您的服务器固件中启用了从安装介质(比如 USB)引导的设置。 |

选择正确的项目(例如 从 USB 引导)后,Proxmox VE 将显示菜单,并可选择以下选项之一:
启动标准安装程序。
|
|
可以仅用键盘来使用安装向导。通过按 ALT 键并结合相应按钮中带下划线的字符,实现单击按钮的效果。比如,ALT + N 相当于单击 Next 按钮。 |
以调试模式开始安装。在相应的安装步骤中将打开控制台,如果出现错误,这有助于调试情况。按 CTRL-D退出调试终端。此选项可用于引导至一个带有基本工具的即时系统,比如,您可以使用它 修复降级的 ZFS rpool 或修复现有 Proxmox VE 设置的 bootloader 。
使用此选项,您可以引导到一个存在的系统。它会搜索所有连接的硬盘,如果找到已安装的系统,它会使用 ISO 中的 Linux 内核引导到该磁盘。如果出现引导块(GRUB)或 BIOS 无法从该磁盘读取引导块的问题时,这将十分有用。
运行 memtest86+ 。这有助于检查内存是否正常工作且没有错误。
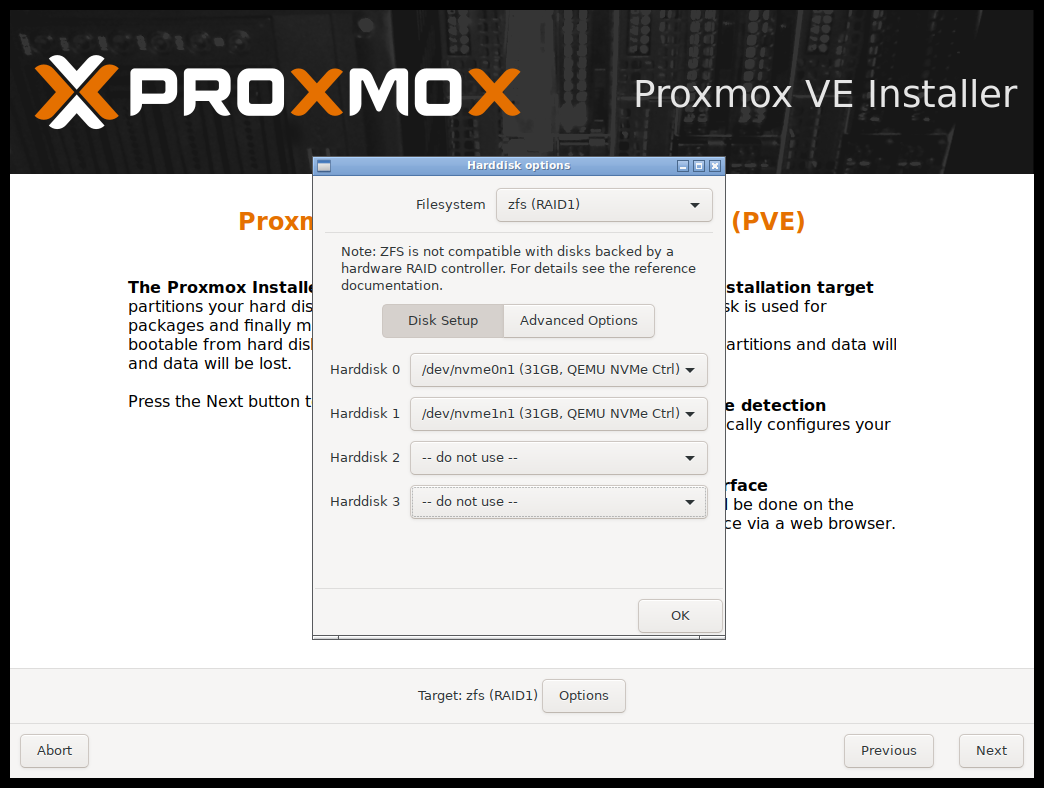
选择 Install Proxmox VE 并接受 EULA 之后,将出现选择目标硬盘的提示。Options(选项) 按钮可以打开选择目标文件系统的对话框。
默认的文件系统为 ext4。当选择 ext4 或 xfs 时使用逻辑卷管理器 (LVM)。还可以设置限制 LVM 空间的其它选项(详见 下文)。
Proxmox VE 可以安装在 ZFS 上,因此 ZFS 为没有硬件 RAID 控制器的系统提供了多种软 RAID 标准可供选择,必须在 Options(选项) 对话框中选择对应的目标磁盘(见右图)。可以在 Advanced Options(高级选项) 中找到更多 ZFS 相关的细节设置 (详见 下文)。
 |
ZFS 不支持任何硬件 RAID,且会导致数据丢失。 |
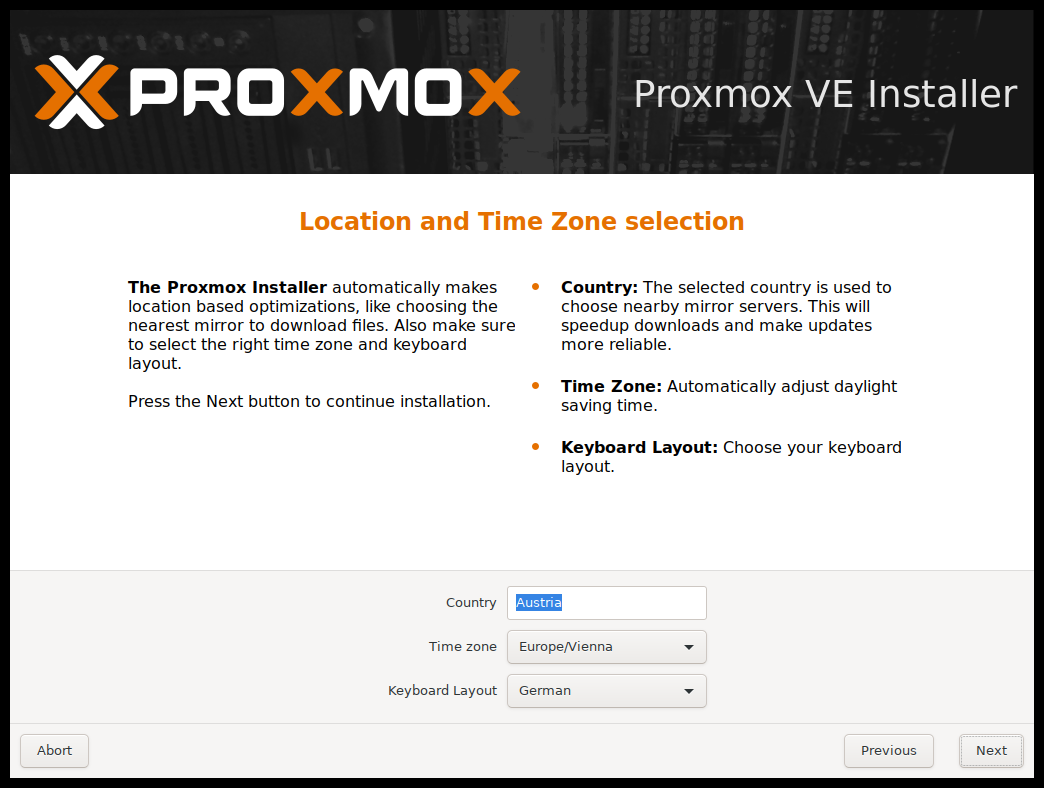
下一页要求提供基本配置选项,如位置、时区和键盘布局。位置是用于选择最近的下载服务器以加速更新。安装程序通常会自动检测这些设置,仅在自动检测失败或者应使用不同键盘布局的罕见情况下,才需要更改它们。
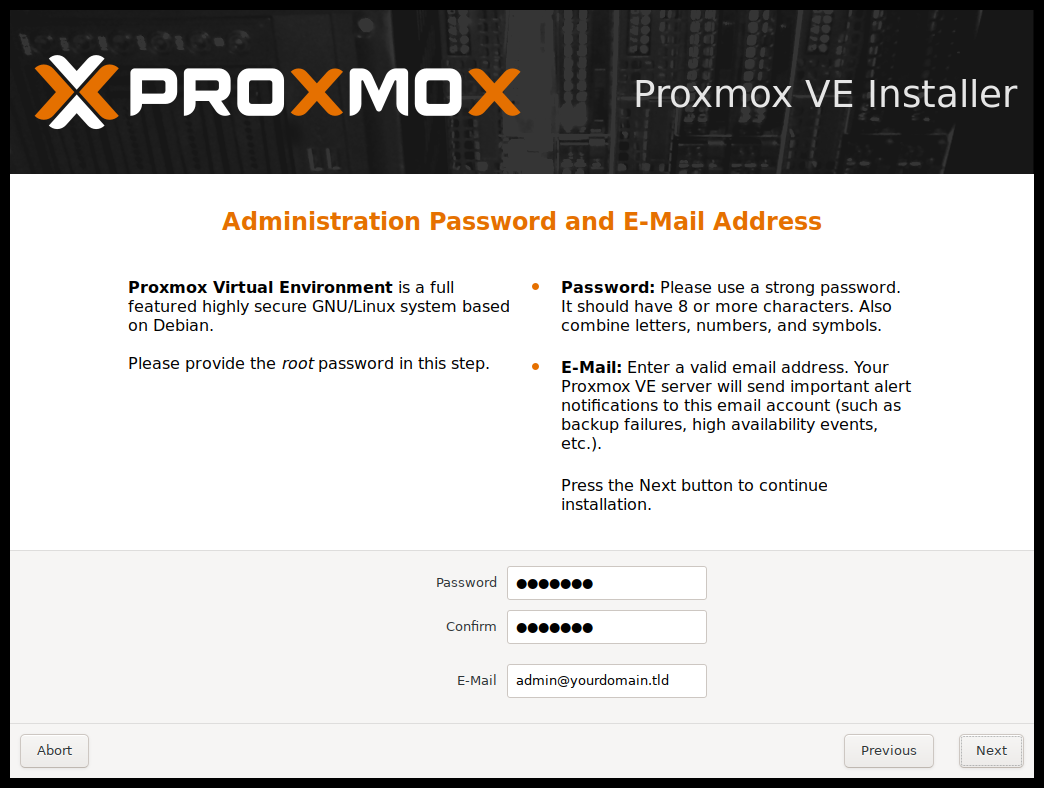
接下来,需要指定超级用户(root)的密码和邮件地址,密码必须至少包含5个字符,强烈建议使用更强的密码,一些准则是:
密码长度至少 12 到 14 字符。
包括小写和大写的字母字符、数字和符号。
避免字符重复、键盘范例、常用字典单词、字母或数字序列、用户名、亲戚或宠物名字、与浪漫相关联的(当前或过去)和个人信息(例如身份证号码、祖姓名或日期等)。
电子邮件地址用于向系统管理员发送通知。例如:
有关可用的软件包的更新信息。
来自定期的 CRON 任务的错误消息。
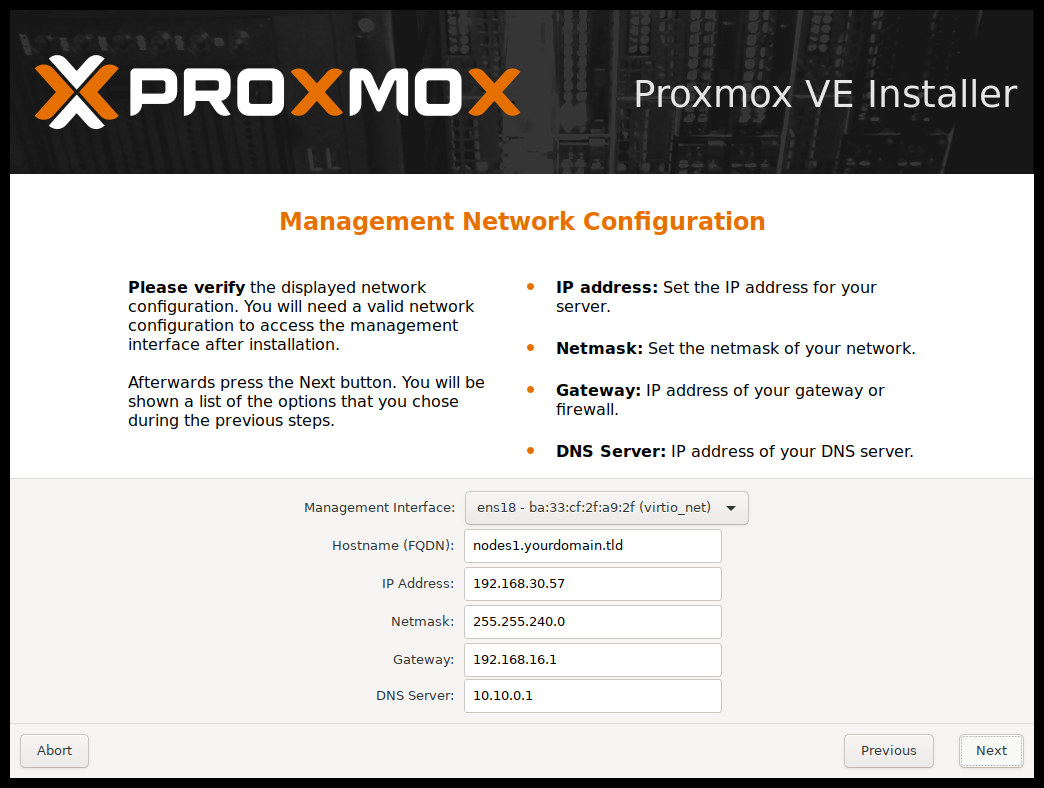
最后一步是网络配置。请注意,在安装过程中,您可以使用 IPv4 或 IPv6 地址,但不能同时使用。要配置双堆栈(Stack)节点,请在安装后添加其它 IP 地址。

下一步显示之前所选选项的摘要。重新检查每个设置,可以通过 Previous 按钮返回更改设置。接受,单击 Install 按钮。安装程序开始格式化磁盘并复制软件包到目标,请等待直到此步骤完成;然后卸下安装介质并重启系统。
更多配置通过 Proxmox 的 web 界面完成,将浏览器指向安装过程中给定的IP地址(https://youripaddress:8006)。
|
|
默认登录名为 "root" (领域为 PAM) ,密码为安装过程中指定的密码。 |
安装程序将创建名为 pve 的卷组(VG),并附加名为 root、data、swap 的逻辑卷(LV),要控制这些卷的大小,请使用:
定义要使用的总硬盘大小。通过这种方式,您可以在硬盘上保留可用空间,以便进一步分区(例如: 用于在同一硬盘上,添加可用于 LVM 存储的 PV 和 VG )。
定义 swap 卷的大小。默认值为安装的内存大小,最小 4 GB,最大 8 GB。结果值不能大于 hdsize/8 。
|
|
如果设置为 0,不会创建 swap 卷。 |
定义 root 卷的最大值,用于存储操作系统。root 卷的最大值不能大于 hdsize/4 。
定义 data 卷的最大值。data 卷的实际大小为:
datasize = hdsize - rootsize - swapsize - minfree
其中 datasize 不能大于 maxvz 。
|
|
如果是 LVM thin(精简类型的存储),仅当 datasize 大于 4GB 时才会创建 data 池 。 |
|
|
如果设置为 0,不会创建 data 卷,存储配置也将相应调整。 |
定义 LVM 卷组 pve 中剩余的可用空间量。超过 128 GB 的可用存储空间默认为 16 GB,否则将使用 hdsize/8 。
|
|
LVM 需要 VG(卷组)中的可用空间来创建快照(lvmthin 快照不需要)。 |
安装程序会创建 ZFS 池 rpool 。不会创建交换空间(swap),但您可以在安装的磁盘上为交换空间(swap)保留一些未分区的空间。您还可以在安装完成后创建一个交换空间 zvol,尽管这可能会带来问题。(请参阅 ZFS swap 说明)。
为创建的池定义 ashift 值。ashift 至少需要设置为底层磁盘的扇区大小(扇区的大小是 ashift 的 2 次方),或者可能放入池中的任何磁盘。(例如更换有缺陷的磁盘)。
定义是否为 rpool 启用压缩。
定义 rpool 应使用哪种校验和算法。
定义 rpool 的 copies 参数。查看 zfs(8) 手册页了解语义,以及为什么这不能替代磁盘级别的冗余。
定义要使用的总硬盘大小。更多的分区有助于节省硬件上的可用空间(例如创建一个交换分区)。hdsize 仅适用于可引导磁盘,即用于 RAID0、RAID1 或 RAID10 的第一个磁盘或镜像,以及 RAID-Z[123] 中的所有磁盘。
ZFS 使用大量内存时效果最好。您如果您打算使用 ZFS,请确保有足够的可用内存。一个很好的计算方法是每 1TB RAW 磁盘空间需要 4GB 加 1GB 内存。
ZFS 可以使用专用驱动器作为写缓存,称之为 ZFS Intent Log (ZIL),为它使用一个快速驱动器(SSD),可以在安装后使用以下命令添加:
# zpool add <pool-name> log </dev/path_to_fast_ssd>
以下各章节将重点介绍常见的虚拟化任务,并解释有关管理 Proxmox VE 和主机管理的细节。
Proxmox VE 是基于 Debian GNU/Linux,带有提供 Proxmox VE 相关软件包的扩展存储库。这意味着可以使用全范围内的 Debian 软件包,包括安全更新和错误修复。Proxmox VE 提供了基于 Ubuntu 内核的 Linux 内核。它开启所有必要的虚拟化和容器的功能,并包括 ZFS 和几个额外的硬件驱动程序。
对于以下章节未包含的其它主题,请参阅 Debian 文档。Debian 管理员手册 可在线获取,并全面介绍了 Debian 操作系统(详见 [Hertzog13])。
Proxmox VE 使用 APT 作为它的软件包管理工具,就像任何其它基于 Debian 的系统一样。
存储库是软件包的集合,它们可以用于安装新软件,但对于获取新更新也很重要。
|
|
您需要有效的 Debian 和 Proxmox 存储库才能获得最新的安全更新、错误修复和新功能。 |
APT 存储库由 /etc/apt/sources.list 文件和 /etc/apt/sources.list.d/ 中的 .list 文件中定义。
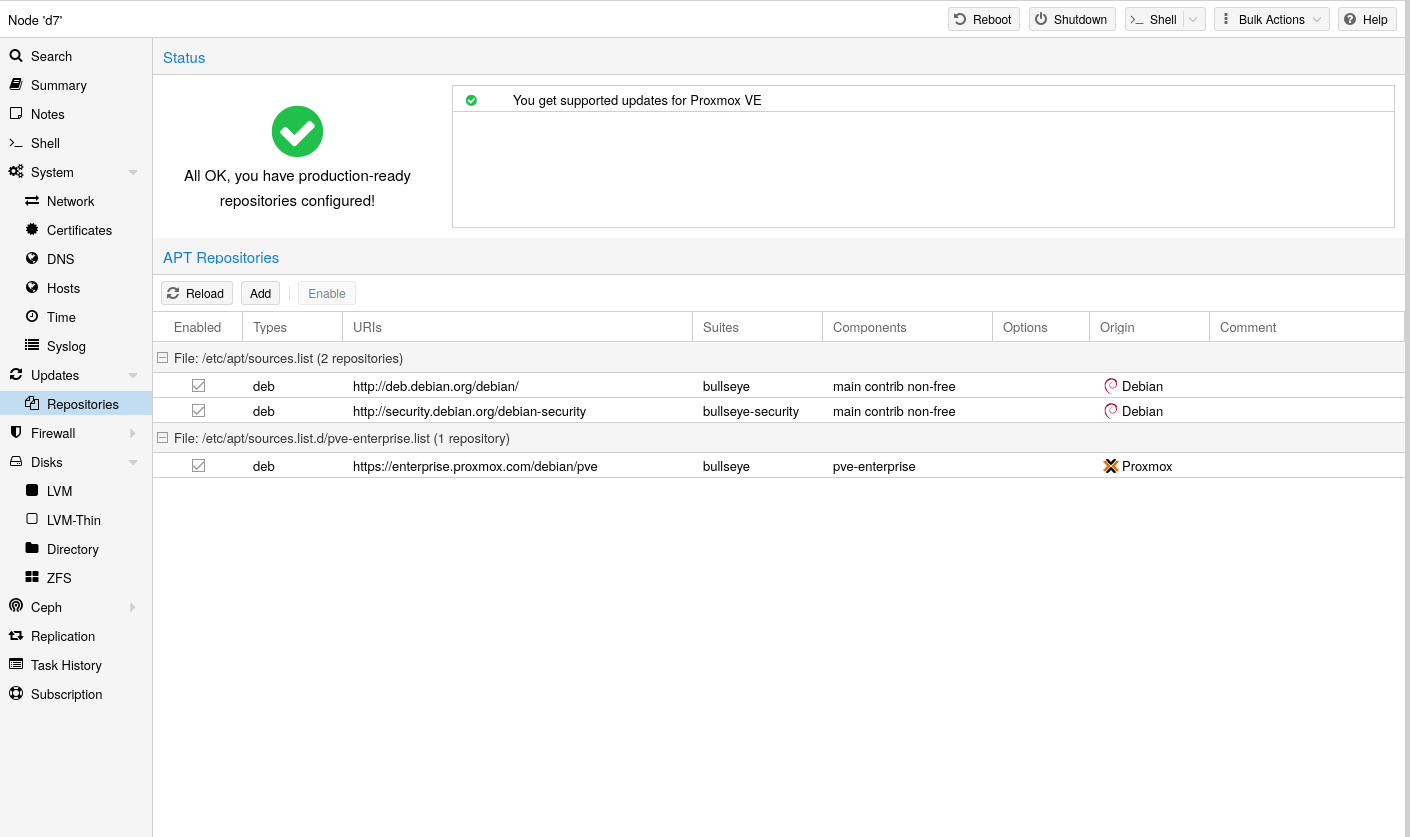
从 Proxmox VE 7.0 开始,您可以在 Web 界面中检查存储库状态。节点的摘要面板显示高级状态的概览,而单独的 存储库 面板显示所有已配置的存储库的列表和详细状态。
还支持基本的存储库管理,例如,启用和禁用一个存储库。
在 sources.list 文件中,每一行定义一个软件包存储库。首选源必须放在第一位,忽略空白行。一行中任意位置的 # 字符将该行的其余部分标记为注释。通过运行 apt-get update 获取存储库中的可用软件包。可以直接使用 apt-get,或者通过 GUI(节点 → 更新)安装更新。
deb http://ftp.debian.org/debian bullseye main contrib deb http://ftp.debian.org/debian bullseye-updates main contrib # 安全更新 deb http://security.debian.org/debian-security bullseye-security main contrib
Proxmox VE 提供了三种不同的软件包存储库。
这是默认、稳定和推荐的存储库,可供所有 Proxmox VE 的订阅用户使用。它包含最稳定的软件包,适合生产用途。默认情况下,已启用 pve-enterprise 存储库:
deb https://enterprise.proxmox.com/debian/pve bullseye pve-enterprise
用户 root@pam 会通过邮件收到关于可用更新的通知。单击 GUI 中的 变更日志 按钮,可以查看所选更新的更多详细信息。
您需要有效的订阅密钥才能访问 pve-enterprise 存储库。提供不级别的支持,更多详细信息可以在 https://www.proxmox.com/en/proxmox-ve/pricing 找到。
|
|
您可以通过使用 #(在行的开头)注释掉上面的行来禁用此存储库。如果您没有订阅密钥,这可以防止出现错误消息。在这种情况下,请配置 pve-no-subscription 存储库。 |
这是推荐用于测试和非生产用途的存储库。它的软件包没有经过严格的测试和验证。您不需要订阅密钥即可访问 pve-no-subscription 存储库。
我们建议在 /etc/apt/sources.list 中配置此存储库。
deb http://ftp.debian.org/debian bullseye main contrib deb http://ftp.debian.org/debian bullseye-updates main contrib # PVE pve-no-subscription 存储库由 proxmox.com 提供, # 不推荐用于生产用途。 deb http://download.proxmox.com/debian/pve bullseye pve-no-subscription # 安全更新 deb http://security.debian.org/debian-security bullseye-security main contrib
该存储库包含最新的软件包,主要供开发人员用于测试新功能。要配置它,请将以下行添加到 etc/apt/sources.list:
deb http://download.proxmox.com/debian/pve bullseye pvetest
|
|
此 pvetest 存储库应该(顾名思义)仅用于测试新功能或错误修复。 |
|
| Ceph Pacific (16.2) 已表明在 Proxmox VE 7.0 中很稳定。 |
此存储库包含主要的 Proxmox VE Ceph Pacific 软件包。它们适用于生产,如果您在 Proxmox VE 上运行 Ceph 客户端或完整的 Ceph 集群,请使用此存储库。
deb http://download.proxmox.com/debian/ceph-pacific bullseye main
这个 Ceph 存储库包含被移动到主存储库前的 Ceph Pacific 软件包,它用于在 Proxmox VE 上测试新的 Ceph 版本。
deb http://download.proxmox.com/debian/ceph-pacific bullseye test
|
| Ceph Octopus (15.2) 已表明在 Proxmox VE 6.3 中很稳定,它将继续在 6.x 版本的剩余生命周期 以及 Proxmox VE 7.x 中获得更新,直到 Ceph Octopus 上游版本的项目结束(EOL 到 2022-07)。 |
此存储库包含主要的 Proxmox VE Ceph Octopus 软件包。它们适用于生产,如果您在您在 Proxmox VE 上运行 Ceph 客户端或完整的 Ceph 集群,请使用此存储库。
deb http://download.proxmox.com/debian/ceph-octopus bullseye main
请注意,在较旧的 Proxmox VE 6.x 版本上,您需要把上面存储库的规则中的 bullseye 更改为 buster。
这个 Ceph 存储库包含被移动到主存储库前的 Ceph 软件包,它用于在 Proxmox VE 上测试新的 Ceph 版本。
deb http://download.proxmox.com/debian/ceph-octopus bullseye test
存储库中的 Release 文件使用 GnuPG 签名。APT 使用这些签名来验证所有软件包是否来自一个可信的源。
如果您从官方 ISO 映像安装 Proxmox VE,则已安装验证密钥。
如果您在 Debian 上安装 Proxmox VE,请使用以下命令下载并安装密钥:
# wget https://enterprise.proxmox.com/debian/proxmox-release-bullseye.gpg -O /etc/apt/trusted.gpg.d/proxmox-release-bullseye.gpg
随后使用命令行(CLI)工具 sha512sum 来验证校验值:
# sha512sum /etc/apt/trusted.gpg.d/proxmox-release-bullseye.gpg 7fb03ec8a1675723d2853b84aa4fdb49a46a3bb72b9951361488bfd19b29aab0a789a4f8c7406e71a69aabbc727c936d3549731c4659ffa1a08f44db8fdcebfa /etc/apt/trusted.gpg.d/proxmox-release-bullseye.gpg
或者使用命令行(CLI)工具 md5sum :
# md5sum /etc/apt/trusted.gpg.d/proxmox-release-bullseye.gpg bcc35c7173e0845c0d6ad6470b70f50e /etc/apt/trusted.gpg.d/proxmox-release-bullseye.gpg
Proxmox 定期为所有存储库提供更新。要安装更新,可以使用基于 Web 的 GUI 或者下列的命令行(CLI)命令:
# apt-get update # apt-get dist-upgrade
|
|
APT 软件包管理系统非常灵活并提供了许多功能,请参阅 man apt-get 或者通过 [Hertzog13] 获取更多信息。 |
|
|
定期更新对于获取最新补丁和与安全相关的修复至关重要。主要系统升级会在 Proxmox VE 社区论坛 中宣布。 |
网络配置可以通过 GUI 或手动编辑包含整个网络配置的文件 /etc/network/interfaces 来完成。接口(5) 手册页包含完整的格式说明。虽然所有 Proxmox VE 工具都努力保持用户的直接修改,但使用 GUI 更适合,因为它可以保护您免受错误的影响。
配置网络后,您可以使用 Debian 的传统工具 ifup 和 ifdown 命令启动和关闭网络接口。
Proxmox VE 不会直接将更改写入 /etc/network/interfaces。相反,我们将写到名为 /etc/network/interfaces.new 的临时文件, 这样,您可以同时进行许多相关的更改,还允许在应用之前确保您的更改是正确的,因为错误的网络配置可能导致节点无法访问。
使用默认安装的 ifupdown 网络管理软件包,您需要重启才能提交任何挂起的网络更改。多数情况下,Proxmox VE 基本的网络设置很稳定且无需经常更改,因此也无需经常重启。
使用可选的 ifupdown2 网络管理软件包,您可以实时重载网络配置,而无需重启。
从 Proxmox VE 6.1 开始,您可以通过 web 界面,使用节点的 网络 面板中的 应用配置 按钮,应用挂起的网络更改。
安装 ifupdown2 前确保您已经安装了最新的 Proxmox VE 更新。
|
|
安装 ifupdown2 时将会移除 ifupdown,但是,由于 0.8.35+pve1 版本之前的 ifupdown 的移除脚本存在一个问题,即移除 [引用于 Debian Buster:https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=945877] 时网络会完全停止,因此,您 必须 确保具有最新的 ifupdown 软件包版本。 |
然后您可以简单地执行以下操作进行安装:
apt install ifupdown2
万事具备,如果您遇到问题,可随时切换回 ifupdown 。
我们目前对设备名称使用以下命名约定:
以太网设备:en*, systemd 网络接口名称。此命名方案用于 5.0 版以后的全新安装的 Proxmox VE。
以太网设备:eth[N], 其中 0 ≤ N (eth0, eth1, …) ,此命名方案用于 5.0 版本之前安装的 Proxmox VE 主机,当升级到 5.0 版本时,名称保持原样。
Bridge 名称:vmbr[N], 其中 0 ≤ N ≤ 4094 (vmbr0 - vmbr4094)
Bond(绑定):bond[N], 其中 0 ≤ N (bond0, bond1, …)
VLAN:只需将 VLAN 编号添加到设备名称中,以句点分隔。(eno1.50, bond1.30)
这使得调试网络问题变得更容易,因为设备名称表明了设备类型。
Systemd 通过两个字符前缀 en 表明以太网网络设备。下一个字符则取决于设备驱动和哪个方案优先匹配的事实。
o<index>[n<phys_port_name>|d<dev_port>] — 板载的设备
s<slot>[f<function>][n<phys_port_name>|d<dev_port>] — 热插拔设备的 id
[P<domain>]p<bus>s<slot>[f<function>][n<phys_port_name>|d<dev_port>] — 总线设备的 id
x<MAC> — 设备的 MAC 地址
最常见的范例是:
eno1 — 是第一个板载的网卡
enp3s0f1 — 是在第 3 个 pci 总线的第 0 插槽上的第 1 个网卡设备。
有关更多信息,请参阅 可预测的网络接口名称 。
根据您当前的网络组织和资源,您可以选择桥接、路由或伪装网络设置。
在这种情况下,桥接 模型最有意义,这也是新安装 Proxmox VE 的默认模式。每个来宾系统都将有一个虚拟接口连接到 Proxmox VE 的网桥(bridge),这实际上类似于将来宾的网卡直接连接到局域网的新交换机上,而 Proxmox VE 主机则扮演交换机的角色。
对于此设置,您可以使用 桥接 或 路由 模式,具体取决于供应商允许的情况。
在这种情况下,为您的来宾系统获取输出网络访问的唯一方法是使用 伪装。对于来宾的传入网络访问,您需要配置 端口转发。
为了获得更多的灵活性,您可以配置 VLAN(IEEE 802.1q)和网络绑定,也称为“链路聚合”,这是一个建立复杂且灵活的虚拟网络的合理方式。

网桥就像在软件中实现的物理网络交换机。所有虚拟来宾都可以共享一个网桥,或者您可以创建多个网桥来分隔网络域。每个主机最多可以有 4094 个网桥。
安装程序创建的一个名为 vmbr0 的网桥,它会连接到第一张以太网网卡。相应的配置在 /etc/network/interfaces 中,它可能如下所示:
auto lo
iface lo inet loopback
iface eno1 inet manual
auto vmbr0
iface vmbr0 inet static
address 192.168.10.2/24
gateway 192.168.10.1
bridge-ports eno1
bridge-stp off
bridge-fd 0
虚拟机表现得就像它们直接连接到物理网络一样。相反,网络认为每个虚拟机均有自己的 MAC 地址,即使只有一条网线将所有虚拟机连接到网络。
大多数主机供应商不支持上述设置。出于安全原因,一旦在单个接口上检测到多个 MAC 地址,它们就会禁用网络。
|
|
某些供应商允许您通过其管理界面注册额外的 MAC 地址。这避免了问题,但是配置起来可能比较笨拙,因为您需要为您的每个 VM 注册一个 MAC 地址。 |
您可以通过单个接口“路由”所有流量来避免该问题,这确保所以网络数据包使用相同的 MAC 地址。

一个常见的场景是,您有一个公网 IP 地址(本例假设为 198.51.100.5 ),以及用于 VM 的额外 IP 段(203.0.113.16/28)。针对此类情况,我们建议采用以下设置:
auto lo
iface lo inet loopback
auto eno0
iface eno0 inet static
address 198.51.100.5/29
gateway 198.51.100.1
post-up echo 1 > /proc/sys/net/ipv4/ip_forward
post-up echo 1 > /proc/sys/net/ipv4/conf/eno1/proxy_arp
auto vmbr0
iface vmbr0 inet static
address 203.0.113.17/28
bridge-ports none
bridge-stp off
bridge-fd 0伪装允许只有一个专有 IP 地址的来宾使用主机的 IP 地址来访问网络,用于传出流量。每个传出的数据包都由 iptables 重写,以显示其来源为主机,并且相应地重写响应数据包,使其能路由到原来的发送方。
auto lo
iface lo inet loopback
auto eno1
#real IP address
iface eno1 inet static
address 198.51.100.5/24
gateway 198.51.100.1
auto vmbr0
#private sub network
iface vmbr0 inet static
address 10.10.10.1/24
bridge-ports none
bridge-stp off
bridge-fd 0
post-up echo 1 > /proc/sys/net/ipv4/ip_forward
post-up iptables -t nat -A POSTROUTING -s '10.10.10.0/24' -o eno1 -j MASQUERADE
post-down iptables -t nat -D POSTROUTING -s '10.10.10.0/24' -o eno1 -j MASQUERADE
|
|
在某些防火墙已开启的伪装设定中,传出连接可能需要连接跟踪(conntrack)区域。否则防火墙可能会阻止传出连接,因为它们更喜欢 VM 网桥的 POSTROUTING(源地址转换),而不是 MASQUERADE(地址伪装)。 |
在 /etc/network/interfaces 中添加这些行可以解决这个问题:
post-up iptables -t raw -I PREROUTING -i fwbr+ -j CT --zone 1 post-down iptables -t raw -D PREROUTING -i fwbr+ -j CT --zone 1
有关这方面的更多信息,请参阅以下链接:
Bond(绑定,也称为 NIC 组合或链路聚合)是一种将多个 NIC(网卡)绑定到单个网络设备的技术,它可以实现不同的目标,例如让网络具有容错能力、提高性能或两者兼而有之。
光纤通道等高速硬件和相关的交换硬件可能非常昂贵,通过链路聚合,将两个网卡作为一个逻辑接口,从而实现双倍的速度。这是大多数交换机都支持的 Linux 内核自带的功能。如果您的节点拥有多个以太网端口,您可以通过将网络电缆连接到不同的交换机来分散故障点,并且在网络出现故障时,绑定的连接会将故障转移到一根或另一根电缆。
聚合的链路可以改善实时迁移的延迟,并提高 Proxmox VE 集群节点之间数据复制的速度。
有 7 种绑定的模式:
轮询调度 Round-robin(balance-rr,负载均衡):传输网络数据包按顺序从可用的第一个从属(slave)网络接口(网卡)依次传输到最后一个。本模式提供负载均衡和容错的能力。
主要-备用 Active-backup(active-backup,主-备): 绑定中只有一个从属(slave)NIC 设备处于活动状态。当且当活动状态的从属(slave)设备发生故障时,另一个从属(slave)设备才会变成活动状态。为避免网络交换机发生混乱,单个逻辑绑定接口仅有一个 NIC(端口)的 MAC 地址对外可见。本模式提供容错功能。
XOR(balance-xor,均衡容错): 传输网络数据包基于 [(源 MAC 地址异或(XOR)目标 MAC 地址)%(模运算)从属(slave) NIC 的数量]。这将为每个目标 MAC 地址选择相同的从属(slave) NIC 。本模式提供负载均衡和容错的能力。
广播 (broadcast,广播): 在所有从属(slave)的网络接口中传输网络数据包。本模式提供容错功能。
IEEE 802.3ad 动态链接聚合(简称 802.3ad)(LACP): 创建可以共享相同速度和双工设置的聚合组。根据 802.3ad 规范,使用活动状态的汇聚组中的所有从属(slave)网络接口。
自适应传输负载均衡(balance-tlb): Linux 绑定驱动程序模式,不需要任何特殊的网络交换机支持。外出网络的数据包流量是按当前负载(相对于速度计算)分配到每个从属(slave)的网络接口上,传入流量由当前指定的从属(slave)网络接口进行接收,如果此接收的从属(slave)设备发生故障,则另一个从属(slave)设备接管故障的从属(slave)设备的 MAC 地址。
自适应负载均衡(balance-alb): 包括 balance-tlb 和用于 IPV4 流量的接收负载均衡(rlb),且不需要任何特殊的网络交换机支持。通过 ARP 协商实现了接收负载平衡。绑定驱动程序拦截本地系统发送的 ARP Replies(ARP 回应报文),然后把单个逻辑绑定的接口中的某个从属(slave)NIC 设备的唯一硬件地址覆盖源硬件地址,以此为不同网络节点的网络数据包流量使用不同的 MAC 地址。
如果您的交换机支持 LACP (IEEE 802.3ad) 协议,则我们建议使用相应的绑定模式(802.3ad)。除此之外,通常应该使用主-备(active-backup)模式。
如果您打算在绑定接口上运行集群网络,则您必须在绑定接口上使用主动-被动(active-passive)模式,不支持其他模式。
以下绑定配置可用作分布式/共享存储网络。这样做的好处是,您可以获得更高的速度,并且网络将具有容错能力。
auto lo
iface lo inet loopback
iface eno1 inet manual
iface eno2 inet manual
iface eno3 inet manual
auto bond0
iface bond0 inet static
bond-slaves eno1 eno2
address 192.168.1.2/24
bond-miimon 100
bond-mode 802.3ad
bond-xmit-hash-policy layer2+3
auto vmbr0
iface vmbr0 inet static
address 10.10.10.2/24
gateway 10.10.10.1
bridge-ports eno3
bridge-stp off
bridge-fd 0
另一种可能性是直接使用 bond(绑定)作为桥接端口,这可以让来宾网络具有容错性。
auto lo
iface lo inet loopback
iface eno1 inet manual
iface eno2 inet manual
auto bond0
iface bond0 inet manual
bond-slaves eno1 eno2
bond-miimon 100
bond-mode 802.3ad
bond-xmit-hash-policy layer2+3
auto vmbr0
iface vmbr0 inet static
address 10.10.10.2/24
gateway 10.10.10.1
bridge-ports bond0
bridge-stp off
bridge-fd 0一个虚拟局域网(VLAN)是一个广播域,它在二层网络进行分区和隔离。因此,在一个物理网络中可能有多个网络(4096 个),每个网络相互独立。
每个 VLAN 网络使用一个通常称为 标签(tag) 的数字进行标识。然后,给网络数据包 打标签(tagged) 以识别它们属于哪个虚拟网络。
Proxmox VE 支持这种开箱即用的设置。您可以在创建 VM 时指定 VLAN 标签,则此 VLAN 标签是来宾网络配置的一部分。网络层支持不同的模式来实现 VLAN,具体取决于桥接(bridge)的配置:
在 Linux bridge 上的 VLAN 感知:在这种情况下,每个来宾的虚拟网卡都分配了一个 VLAN 标签,Linux bridge(网桥) 支持透明传递标签。中继模式(Trunk)也是可能的,但这需要在来宾中进行配置。
在 Linux bridge 上的 "传统" VLAN:与 VLAN 感知方法相比,此方法不是透明的,而是为每个 VLAN 创建一个具有关联网桥的 VLAN 设备。也就是说,例如在 VLAN 5 上创建一个来宾,将创建两个接口 eno1.5 和 vmbr0v5,它们将一直保留到重新启动。
Open vSwitch VLAN:此模式使用 OVS VLAN 功能。
来宾配置的 VLAN:VLAN 是在来宾内部分配的。在这种情况下,设置在来宾内部完成且不受外部影响。优势是您可以在单个虚拟网卡上使用多个 VLAN 。
允许主机与隔离网络通信。可以将 VLAN 标签应用于任何网络设备(网卡、Bond(绑定)、Bridge(网桥))。通常,您应该在接口上配置 VLAN,使其与物理网卡之间有最少的抽象层。
例如,在默认配置中,您希望将主机管理地址放置在单独的 VLAN 上。
auto lo
iface lo inet loopback
iface eno1 inet manual
iface eno1.5 inet manual
auto vmbr0v5
iface vmbr0v5 inet static
address 10.10.10.2/24
gateway 10.10.10.1
bridge-ports eno1.5
bridge-stp off
bridge-fd 0
auto vmbr0
iface vmbr0 inet manual
bridge-ports eno1
bridge-stp off
bridge-fd 0
auto lo
iface lo inet loopback
iface eno1 inet manual
auto vmbr0.5
iface vmbr0.5 inet static
address 10.10.10.2/24
gateway 10.10.10.1
auto vmbr0
iface vmbr0 inet manual
bridge-ports eno1
bridge-stp off
bridge-fd 0
bridge-vlan-aware yes
bridge-vids 2-4094
下一个范例是相同的设置,但使用了一个 bond(绑定)来确保网络具有容错性。
auto lo
iface lo inet loopback
iface eno1 inet manual
iface eno2 inet manual
auto bond0
iface bond0 inet manual
bond-slaves eno1 eno2
bond-miimon 100
bond-mode 802.3ad
bond-xmit-hash-policy layer2+3
iface bond0.5 inet manual
auto vmbr0v5
iface vmbr0v5 inet static
address 10.10.10.2/24
gateway 10.10.10.1
bridge-ports bond0.5
bridge-stp off
bridge-fd 0
auto vmbr0
iface vmbr0 inet manual
bridge-ports bond0
bridge-stp off
bridge-fd 0
Proxmox VE 集群堆栈(stack)本身在很大程度上依赖一个事实:所有节点都精确地同步了时间。如果所有节点上的本地时间不同步,其他一些组件(如 Ceph)也将无法正常工作。
使用“网络时间协议”(简称 NTP)可以实现节点之间的时间同步。从 Proxmox VE 7 开始,chrony 被用作默认的 NTP 守护进程,而 Proxmox VE 6 使用 systemd-timesyncd。两者都预先配置为使用一组公共服务器。
|
|
如果您将系统升级到 Proxmox VE 7,建议手动安装 chrony、ntp 或 openntpd。 |
在某些情况下,可能需要使用非默认的 NTP 服务器。例如,如果您的 Proxmox VE 节点受限于防火墙策略而未能访问公共互联网,则您需要设置本地 NTP 服务器并告知 NTP 守护进程使用它们。
应在 /etc/chrony/chrony.conf 中为 chrony 指定使用哪些服务器:
server ntp1.example.com iburst server ntp2.example.com iburst server ntp3.example.com iburst
重启 chrony:
# systemctl restart chronyd
检查日志以确认正在使用新配置的 NTP 服务器:
# journalctl --since -1h -u chrony
... Aug 26 13:00:09 node1 systemd[1]: Started chrony, an NTP client/server. Aug 26 13:00:15 node1 chronyd[4873]: Selected source 10.0.0.1 (ntp1.example.com) Aug 26 13:00:15 node1 chronyd[4873]: System clock TAI offset set to 37 seconds ...
应在 /etc/systemd/timesyncd.conf 中为 systemd-timesyncd 指定使用哪些服务器:
[Time] NTP=ntp1.example.com ntp2.example.com ntp3.example.com ntp4.example.com
然后,重启同步服务(systemctl restart systemd-timesyncd),并通过检查日志(journalctl --since -1h -u systemd-timesyncd)来验证新配置的 NTP 服务器是否正在使用中:
... Oct 07 14:58:36 node1 systemd[1]: Stopping Network Time Synchronization... Oct 07 14:58:36 node1 systemd[1]: Starting Network Time Synchronization... Oct 07 14:58:36 node1 systemd[1]: Started Network Time Synchronization. Oct 07 14:58:36 node1 systemd-timesyncd[13514]: Using NTP server 10.0.0.1:123 (ntp1.example.com). Oct 07 14:58:36 node1 systemd-timesyncd[13514]: interval/delta/delay/jitter/drift 64s/-0.002s/0.020s/0.000s/-31ppm ...
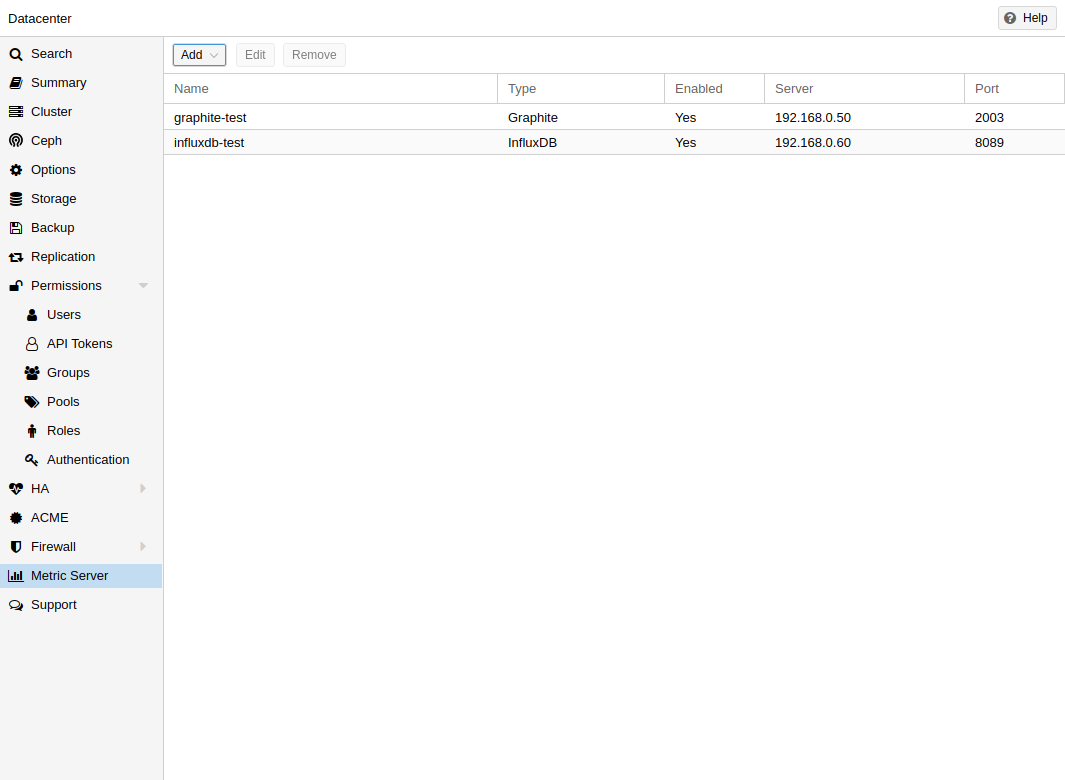
在 Proxmox VE 中,您可以定义外部度量服务器,它将定期接收有关主机、虚拟来宾和存储的各种统计信息。
目前支持的有:
Graphite (详见 https://graphiteapp.org )
InfluxDB (详见 https://www.influxdata.com/time-series-platform/influxdb/ )
外部度量服务器的定义保存在 /etc/pve/status.cfg,并可通过 Web 界面进行编辑。
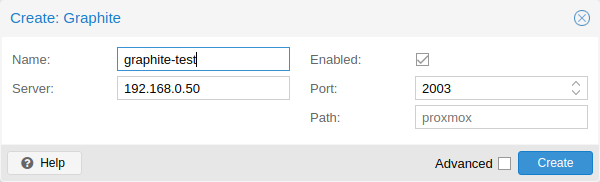
默认端口设置为 2003,且 graphite 默认的路径是 proxmox 。
默认情况下,Proxmox VE 通过 UDP 发送数据,因此需要将 graphite 服务器配置为接受该数据。此处最大传输单元(MTU)可以配置为不使用标准 1500 MTU 的环境。
您还可以配置插件来使用 TCP,为了不阻塞重要的 pvestatd 统计数据收集守护进程,需要配置“超时”来应对网络问题。
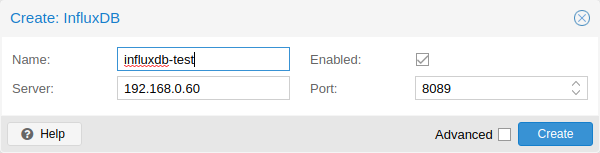
Proxmox VE 通过 UDP 发送数据,因此需要将 influxdb 服务器配置为接受该数据。如有必要,也可在此配置 MTU。
下面是 influxdb 的范例配置(在您的 influxdb 服务器上):
[[udp]] enabled = true bind-address = "0.0.0.0:8089" database = "proxmox" batch-size = 1000 batch-timeout = "1s"
使用这个配置,您的服务器侦听端口 8089 上的所有 IP 地址,并将数据写入 proxmox 数据库。
或者,该插件可以配置为使用 InfluxDB 2.x 的 http(s) API。InfluxDB 1.8.x 版本事实上包含了一个向前兼容的 v2 版本 API 端口。
要使用它,请将 influxdbproto 设置为 http 或 https(取决于您的配置)。默认情况下,Proxmox VE 使用的“组织”和“插槽/数据库”均为 proxmox(它们可以分别配置 组织 和 插槽 进行设置 )。
由于 InfluxDB 的 v2 API 仅适用于认证,您必须生成一个令牌,这个令牌可以写入正确的插槽(bucket)并进行设置。
在 1.8.x 版本的 v2 版本兼容性 API 中,您可以使用 user:password(用户名:密码) 作为令牌(如果需要),并且可以省略 组织,因为这在 InfluxDB 1.x 中没有意义。
您还可以通过 超时 来设置 HTTP 超时的时间(默认是 1 秒),以及使用 max-body-size 来设置(这对应于同名的 InfluxDB 设置)的最大批次大小(默认为 25000000 字节)。
尽管推荐使用强健的冗余存储,但是它对监视本地磁盘的健康也非常有帮助。
从 Proxmox VE 4.3 开始,必须要安装 smartmontools
[smartmontools 主页 https://www.smartmontools.org]
软件包。这是一组用于监视和控制本地硬盘的 S.M.A.R.T 系统的工具。
您可以通过发出以下命令来获取磁盘的状态:
# smartctl -a /dev/sdX
其中 /dev/sdX 是一个本地磁盘的路径。
如果输出显示:
# SMART 支持:已禁用
SMART support is: Disabled
您可以使用以下命令启用它:
# smartctl -s on /dev/sdX
有关如何使用 smartctl 的更多信息,请参阅 man smartctl。
默认情况下,smartmontools 的守护进程 smartd 处于活动状态并启用,每 30 分钟扫描一次 /dev/sdX 和 /dev/hdX 下的磁盘,以查找错误和警告,并在检测到问题时向管理员(root)发送电子邮件。
有关如何配置 smartd 的更多信息,请参阅 man smartd 和 man smartd.conf。
如果您将硬盘和硬件 RAID 控制器一起使用,有许多类似的工具可以监视 RAID 阵列里的磁盘和阵列本身。有关这方面的更多信息,请参阅 RAID 控制器的供应商。
大多数人直接在本地磁盘上安装 Proxmox VE 。Proxmox VE 的安装 CD 为本地磁盘管理提供了多个选项,当前的默认设置使用 LVM 。安装程序允许您为此类设置选择单个磁盘,并将该磁盘作为卷组(VG)( Volume Group)pve 的物理卷。以下输出是来自使用小容量的 8GB 磁盘的测试安装:
# pvs PV VG Fmt Attr PSize PFree /dev/sda3 pve lvm2 a-- 7.87g 876.00m # vgs VG #PV #LV #SN Attr VSize VFree pve 1 3 0 wz--n- 7.87g 876.00m
安装程序在此 VG 内分配了三个逻辑卷(LV)(Logical Volumes):
# lvs LV VG Attr LSize Pool Origin Data% Meta% data pve twi-a-tz-- 4.38g 0.00 0.63 root pve -wi-ao---- 1.75g swap pve -wi-ao---- 896.00m
格式为 ext4,并包含操作系统。
交换(Swap)分区
此卷使用 LVM-thin,并用来存储 VM 映像。LVM-thin 更适合此任务,因为它提供了对快照和克隆的高效率支持。
对于 4.1 版本之前的 Proxmox VE,安装程序创建一个名为 “data” 的标准逻辑卷(LV),该卷挂载在 /var/lib/vz。
从 4.2 版本开始,逻辑卷 “data” 是一个 LVM-thin pool(LVM 精简配置池),用于存储 基于块(block)的 来宾映像,而 /var/lib/vz 只是 root 文件系统上的一个目录。
我们强烈建议对此类设置使用硬件 RAID 控制器(带 BBU)。这会提高性能、提供冗余并使更换磁盘更容易(可热插拔)。
LVM 本身不需要任何特殊的硬件,且对内存的要求很低。
我们默认安装了两个引导加载程序。第一个分区包含标准的 GRUB 引导加载程序,第二个分区是一个 EFI 系统分区(EFI System Partition (ESP 分区) ), 它可以在 EFI 系统上启动。
假设我们有一个空磁盘 /dev/sdb,我们想在其上创建一个名为“vmdata”的卷组(VG)。
|
|
请注意,以下命令将销毁 /dev/sdb 上的所有现有数据。 |
首先创建一个分区。
# sgdisk -N 1 /dev/sdb
创建一个无需确认和 250K 元数据大小的物理卷(PV)(Physical Volume)。
# pvcreate --metadatasize 250k -y -ff /dev/sdb1
在 /dev/sdb1 上创建一个名为“vmdata” 的卷组(VG)。
# vgcreate vmdata /dev/sdb1
这可以通过创建一个新的精简逻辑卷(Thin LV)来轻松完成。
# lvcreate -n <Name> -V <Size[M,G,T]> <VG>/<LVThin_pool>
一个真实的例子:
# 在 pve 卷组中的 data 精简配置池中创建一个名为 vz,容量 10G 的逻辑卷(LV)。
# lvcreate -n vz -V 10G pve/data
现在必须在名为 vz 的逻辑卷(LV)上创建一个文件系统。
# mkfs.ext4 /dev/pve/vz
最后必须要挂载它才能使用。
|
|
确保 /var/lib/vz 为空,在默认安装中它不是空的。 |
要使其始终可访问,请在 /etc/fstab 中添加以下行。
# echo '/dev/pve/vz /var/lib/vz ext4 defaults 0 2' >> /etc/fstab
可以通过以下命令调整逻辑卷(LV)和元数据池(pool)的大小:
# lvresize --size +<size[\M,G,T]> --poolmetadatasize +<size[\M,G]> <VG>/<LVThin_pool>
|
|
在扩展数据池时,也必须扩展元数据池。 |
必须在卷组(VG)上创建精简池(thin pool)。如何创建卷组(VG)请参阅 逻辑卷管理(LVM)的 创建卷组(VG)章节。
# lvcreate -L 80G -T -n vmstore vmdata
ZFS 是由 Sun Microsystems 设计的组合文件系统和逻辑卷(LV)管理器。从 Proxmox VE 3.4 开始,ZFS 文件系统作为原生 Linux 内核引入的可选文件系统,同样也作为 root 文件系统的附加选择。无需手动编译 ZFS 模块 - 所有软件包已包含在内。
通过使用 ZFS,不仅可以利用低预算硬件实现最大的企业功能,还可以利用 SSD 缓存甚至仅用 SSD 设置来实现高性能的系统。ZFS 可以通过适度的 CPU、内存负载并结合轻松的管理来代替成本高昂的硬件 RAID 卡。
通过 Proxmox VE GUI 界面和命令行(CLI)轻松配置和管理。
可靠
防止数据损坏
文件系统级别的数据压缩
快照
写时复制克隆
不同 RAID 级别:RAID0,RAID1,RAID10,RAIDZ-1,RAIDZ-2 和 RAIDZ-3
可用 SSD 作为缓存
自我修复
持续完整性检查
专为高存储容量而设计
网络异步复制
开源
加密
…
ZFS 严重依赖 内存,因此您至少需要 8GB 内存才能启动。在实践中,尽可能多地使用您的硬件/预算。为防止数据损坏,我们建议使用高品质的 ECC 内存。
如果您使用专用缓存和[/或]日志磁盘,则应该使用企业级的 SSD(例如 Intel SSD DC S3700 系列),这可以显著提高整体性能。
|
|
不要在自带缓存管理的硬件 RAID 上使用 ZFS,因为 ZFS 需要直接与磁盘通信,所以 HBA 适配器或者类似将固件更新为 “IT”模式(flashed IT mode)的 LSI 控制器更适合。 |
如果您正尝试在 VM 中安装 Proxmox VE(嵌套虚拟化),请不要为该 VM 的磁盘使用 virtio,这是由于 ZFS 不支持它们,可以改用 IDE 或 SCSI(也适用于 virtio SCSI 控制器类型)。
当您使用 Proxmox VE 安装程序进行安装时,您可以选择 ZFS 作为 root 文件系统,您需要在安装时选择 RAID 类型:
| RAID0 |
也称为“条带”。该卷的容量是所有磁盘容量的总和。但是 RAID0 并未添加任何冗余,因此单个驱动器的故障会导致卷无法使用。 |
| RAID1 |
也称为“镜像”。数据以相等的方式写入所有磁盘。此模式至少需要 2 个相同大小的磁盘,产生的容量是单个磁盘的容量。 |
| RAID10 |
RAID0 和 RAID1 的组合。至少需要 4 个磁盘。 |
| RAIDZ-1 | RAID-5 的变体之一,单奇偶校验,至少需要 3 个磁盘。 |
| RAIDZ-2 | RAID-5 的变体之一,双奇偶校验,至少需要 4 个磁盘。 |
| RAIDZ-3 | RAID-5 的变体之一,三重奇偶校验,至少需要 5 个磁盘。 |
安装程序会自动对磁盘进行分区,创建一个名为 rpool 的 ZFS 池,并在 ZFS 子卷 rpool/ROOT/pve-1 上安装 root 文件系统。
创建另一个名为 rpool/data 的子卷用于存储 VM 映像。为了与 Proxmox VE 工具一起使用,安装程序在 /etc/pve/storage.cfg 文件中创建下列配置条目:
zfspool: local-zfs
pool rpool/data
sparse
content images,rootdir安装以后,您可以使用 zpool 命令查看 ZFS 池状态:
# zpool status
pool: rpool
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sda2 ONLINE 0 0 0
sdb2 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
sdc ONLINE 0 0 0
sdd ONLINE 0 0 0
errors: No known data errorszfs 命令用于配置和管理您的 ZFS 文件系统。以下命令列出安装完成后的所有文件系统:
# zfs list NAME USED AVAIL REFER MOUNTPOINT rpool 4.94G 7.68T 96K /rpool rpool/ROOT 702M 7.68T 96K /rpool/ROOT rpool/ROOT/pve-1 702M 7.68T 702M / rpool/data 96K 7.68T 96K /rpool/data rpool/swap 4.25G 7.69T 64K -
在选择 ZFS 池(ZFS pool)的布局时,需要考虑几个因素。ZFS 池的基本构建块(block)是虚拟设备或叫 vdev(虚拟设备)。在池中的所有的 vdev 均等使用,并且数据之间进行条带化处理(RAID0)。查看 zpool(8) 手册页以了解关于 vdev 的更多详细信息。
每种 vdev 类型都有不同的性能表现。感兴趣的两个参数是 IOPS(Input/Output Operations per Second,即每秒输入/输出操作的次数)和数据读取或写入的带宽。
在写入数据时,镜像 的 vdev (RAID1) 在这两个参数方面的表现与单个磁盘相似,而在读取数据时,其表现类似于镜像中的磁盘数。
一个常见的情况是有 4 个磁盘。当将其设置为 2 个镜像的 vdev(RAID10)时,该 pool 将在 IOPS 和带宽方面具有两个单磁盘的写入特性。对于读取操作,它将类似于 4 个单磁盘。
就具有大量带宽的 IOPS 而言,任何冗余级别的 RAIDZ 都近似于单个磁盘,至于多少带宽则取决于 RAIDZ 的 vdev 的容量大小和冗余级别。
对于正在运行的 VM ,在大多数情况下,IOPS 是很重要的指标。
虽然由 镜像 的 vdev 组成的池(pool)将具有最佳的性能特性,但是可用空间将只有可用磁盘的 50%,如果镜像的 vdev 包括 2 个以上的磁盘,可用空间将会更少(例如在一个 3-way 镜像中)。每个镜像至少需要一个运行状况良好的磁盘才能使池(pool)保持正常运行。
N 个磁盘的 RAIDZ 类型的 vdev 的可用空间大致为 N-P(N 减去 P),P 对应 RAIDZ 的级别(RAIDZ-级别)。RAIDZ 的级别表明在不丢失数据的情况下允许发生故障的任意磁盘数量。一种特殊情况是使用 RAIDZ2 的 4 个磁盘池,在这种情况下,通常最好使用 2 个镜像的 vdev 以获得更好的性能,因为可用空间将是相同的。
使用任何 RAIDZ 级别时另一个重要因素是用于 VM 磁盘的 ZVOL 数据集的行为方式。对于每个数据块(block),池需要奇偶校验数据,该数据大小至少是池定义的 ashift 值最小的块尺寸的大小,当 ashift 为 12 时,池的块尺寸是 4k。ZVOL 的默认块尺寸为 8k。因此,在 RAIDZ2 中,每写入 8k 的块同时会写入两个额外的 4k 奇偶校验块,8k + 4k + 4k = 16k 。当然这是一种简化的方法,实际情况会略有不同,在本例中未将元数据、是否压缩等考虑在内。
当检查 ZVOL 的以下属性时可以观察到此行为:
volsize
refreservation(如果池未进行精简配置)
used(如果池是精简配置且不存在快照)
# zfs get volsize,refreservation,used <pool>/vm-<vmid>-disk-X
volsize 是提供给 VM 的磁盘大小,而 refreservation 显示池(pool)上的保留空间,其中包括奇偶校验数据所需的预期空间。如果池(pool)是精简配置的,则 refreservation 将设置为 0。观察该行为的另一种方法是比较 VM 中的已用磁盘空间和已使用属性。请注意,快照会影响该值的准确性。
有几个选项可提高空间利用率:
增加 volblocksize(卷-块尺寸),以改善数据进行奇偶检验的比率。
使用 镜像 的 vdev,而不是 RAIDZ。
使用 ashift=9(块大小为 512 字节)。
volblocksize(卷-块尺寸) 属性只能在创建 ZVOL 时设置。可以在存储配置中更改默认值。执行此操作时,来宾(虚拟机)需要根据用例进行相应的调整,如果只是从 ZFS 层级移动到来宾(虚拟机),则会出现写入放大的问题。
在创建池时使用 ashift=9 会导致性能不佳,具体取决于下面的磁盘,并且以后无法更改。
镜像的 vdev(RAID1、RAID10)对于 VM 的工作负载具有良好的表现。除非您的环境具有 RAIDZ 可接受的特定需求与特征,否则请使用它们。
Proxmox VE 使用 proxmox-boot-tool 来管理引导加载程序(bootloader)配置。有关详细信息,请参阅 Proxmox VE 主机 bootloader(引导加载程序) 一章。/p>
本节为您提供了一些常见任务的使用范例。ZFS 本身非常强大,并提供了许多选项。管理 ZFS 的主要命令是 zfs 和 zpool。这两个命令都带有很棒的手册页,可以通过以下方式阅读:
# man zpool # man zfs
要创建一个新池(pool),至少需要一个磁盘。ashift 应与底层磁盘具有相同(ashift 的 2 次方)或更大的扇区大小。
# zpool create -f -o ashift=12 <pool> <device>
激活压缩(参阅 ZFS 中的压缩 部分):
# zfs set compression=lz4 <pool>
至少 1 个磁盘
# zpool create -f -o ashift=12 <pool> <device1> <device2>
至少 2 个磁盘
# zpool create -f -o ashift=12 <pool> mirror <device1> <device2>
至少 4 个磁盘
# zpool create -f -o ashift=12 <pool> mirror <device1> <device2> mirror <device3> <device4>
至少 3 个磁盘
# zpool create -f -o ashift=12 <pool> raidz1 <device1> <device2> <device3>
至少 4 个磁盘
# zpool create -f -o ashift=12 <pool> raidz2 <device1> <device2> <device3> <device4>
可以使用专用缓存驱动器分区来提高性能(使用SSD)。
比如 <device>,可以使用更多设备,就如“使用 RAID* 创建新池”中所示。
# zpool create -f -o ashift=12 <pool> <device> cache <cache_device>
可以使用专用缓存驱动器分区来提高性能(使用SSD)。
比如 <device>,可以使用更多设备,就如“使用 RAID* 创建新池”中所示。
# zpool create -f -o ashift=12 <pool> <device> log <log_device>
如果您有一个没有缓存和日志的池。使用 parted 或 gdisk 将 SSD 分成 2 个分区。
|
| 始终使用 GPT 分区表。 |
日志设备的最大大小应该是物理内存大小的一半左右,所以这通常很小。SSD 的其余部分可用作缓存。
# zpool add -f <pool> log <device-part1> cache <device-part2>
# zpool replace -f <pool> <old device> <new device>
根据 Proxmox VE 的安装方式,它使用 proxmox-boot-tool
[安装有 Proxmox VE 6.4 或更高版本的系统,安装有 Proxmox VE 5.4 或更高版本的 EFI 系统]
或简单的 grub 作为 bootloader(引导加载程序)(参阅 主机 Bootloader(引导加载程序))。您可以通过运行以下命令来检查:
# proxmox-boot-tool status
第一步都是相同的,包括复制分区表、重新发布 GUID 和替换 ZFS 分区。为了让系统可以从全新磁盘引导,需要根据所使用的 bootloader(引导加载程序) 来执行不同的步骤。
# sgdisk <healthy bootable device> -R <new device> # sgdisk -G <new device> # zpool replace -f <pool> <old zfs partition> <new zfs partition>
|
|
使用 zpool status -v 命令监控新磁盘的恢复过程的进展情况。 |
# proxmox-boot-tool format <new disk's ESP> # proxmox-boot-tool init <new disk's ESP>
|
|
ESP 代表 EFI 系统分区,该分区从 5.4 版本起,由 Proxmox VE 安装程序在可引导磁盘上设置为第 2 个分区。有关详细信息,请参阅 设置新分区以用作同步 ESP。 |
# grub-install <new disk>
ZFS 附带一个事件守护进程,它监视 ZFS 内核模块生成的事件。此守护进程还能发送有关 ZFS 事件(类似池错误)的电子邮件。较新的 ZFS 软件包在单独的软件包中提供守护进程,您可以使用 apt-get 安装:
# apt-get install zfs-zed
要激活守护进程,需要使用您喜欢的编辑器编辑 /etc/zfs/zed.d/zed.rc,并取消 ZED_EMAIL_ADDR 设置的注释:
ZED_EMAIL_ADDR="root"
请注意 Proxmox VE 将邮件转发到为 root 用户配置的电子邮件地址。
|
|
唯一需要的设置是 ZED_EMAIL_ADDR,所有其他设置都是可选的。 |
默认情况下,ZFS 将 50% 的主机内存用于自适应替换缓存(ARC)(Adaptive Replacement Cache)。为 ARC 分配足够的内存对于 IO 性能至关重要,因此请谨慎减少内存。作为一般经验法则,至少分配 2GB 内存 + 每 1TB 存储用 1G 内存。例如,如果您有一个具有 8TB 可用存储空间的池,则您应该为 ARC 使用 10GB(=2G+1G*8)内存。
您可以通过以下命令,直接写入 zfs_arc_max 模块参数来更改当前引导(重新启动会再次重置此更改)的 ARC 使用限制:
echo "$[10 * 1024*1024*1024]" >/sys/module/zfs/parameters/zfs_arc_max
要 永久更改 ARC 限制,请将以下行添加到 /etc/modprobe.d/zfs.conf:
options zfs zfs_arc_max=8589934592
此范例设置将内存使用限制为 8GB(8 * 230)。
|
|
如果您想要的 zfs_arc_max 值小于或等于 zfs_arc_min(默认为系统内存的 1/32),除非您设置zfs_arc_min 至多到 zfs_arc_max - 1,否则 zfs_arc_max 将被忽略。 |
echo "$[8 * 1024*1024*1024 - 1]" >/sys/module/zfs/parameters/zfs_arc_min echo "$[8 * 1024*1024*1024]" >/sys/module/zfs/parameters/zfs_arc_max
此范例设置(临时)在总内存超过 256GB 的系统上将内存的使用限制为 8GB(8 * 230) ,其中仅设置 zfs_arc_max 是不起作用的。
|
|
如果您的 root 文件系统是 ZFS,则每次此值更改时,必须更新您的 initramfs: # update-initramfs -u 您 必须重启 才能激活这些更改。 |
在 zvol 上创建交换空间(Swap-space)可以会产生一些问题,例如阻塞服务器或产生高 IO 负载,这在开始备份到外部存储时经常看到。
我们强烈建议使用足够的内存,这样您通常不会遇到内存不足的情况。如果您需要(或想要)添加 swap(交换),最好在物理磁盘上创建一个分区,并将其用作交换(swap)设备,您可以在 安装程序 的 高级选项 中为此留出一些空间。此外,您可以降低“swappiness”的值,服务器的最佳值为 10:
# sysctl -w vm.swappiness=10
要使 swappiness 持久化,请使用您选择的编辑器打开 /etc/sysctl.conf,并添加以下行:
vm.swappiness = 10
| 值 | 策略 |
|---|---|
vm.swappiness = 0 | 内核仅交换(swap)以避免 out of memory(内存不足) 的情况。 |
vm.swappiness = 1 | 不完全禁用的最小交换量。 |
vm.swappiness = 10 | 当系统内存充足时,有时建议使用此值来提高性能。 |
vm.swappiness = 60 |
默认值 |
vm.swappiness = 100 | 内核将积极交换。 |
Linux 0.8.0 版上的 ZFS 引入了对数据集原生加密的支持。Linux 版本中的旧版 ZFS 升级以后,可以为每个池启用加密功能:
# zpool get feature@encryption tank NAME PROPERTY VALUE SOURCE tank feature@encryption disabled local # zpool set feature@encryption=enabled # zpool get feature@encryption tank NAME PROPERTY VALUE SOURCE tank feature@encryption enabled local
|
|
目前不支持使用 Grub 从具有已加密数据集的池启动,并且仅有限支持在启动时自动解锁已加密数据集。没有加密支持的旧版本 ZFS 将无法解密存储的数据。 |
|
|
建议在启动后手动解锁存储的数据集,或编写自定义单元,将启动时解锁所需的密钥材料传递给 zfs load-key 。 |
|
|
在启用生产数据的加密之前,建立并测试备份的步骤,如果相关的密钥材料/密语/密码文件已丢失,则无法再访问加密的数据。 |
创建数据集/zvol(datasets/zvols)时需要设置加密,且默认情况下子数据集会继承加密。例如,要创建加密的数据集 tank/encrypted_data,并将其配置为 Proxmox VE 中的存储,请运行以下命令:
# zfs create -o encryption=on -o keyformat=passphrase tank/encrypted_data Enter passphrase: Re-enter passphrase: # pvesm add zfspool encrypted_zfs -pool tank/encrypted_data
在此存储上创建的所有来宾的卷/磁盘,都将使用父数据集的共享密钥材料进行加密。
要实际使用存储,需要加载关联的密钥材料,并且需要挂载数据集。这可以通过以下方式一步到位:
# zfs mount -l tank/encrypted_data Enter passphrase for 'tank/encrypted_data':
通过在创建数据集时或在现有数据集上使用 zfs change-key 命令,设定 keylocation 和 keyformat 属性,就可以一个使用(随机)密钥文件来而不是提示输入密码:
# dd if=/dev/urandom of=/path/to/keyfile bs=32 count=1 # zfs change-key -o keyformat=raw -o keylocation=file:///path/to/keyfile tank/encrypted_data
|
|
使用密钥文件时,需要特别小心,以防止未经授权的访问或意外丢失密钥文件。没有密钥文件,无法访问明文数据! |
在已加密的数据集下创建的来宾(虚拟机)卷,将相应地对其 encryptionroot 属性进行设置。密钥材料仅需要每个 encryptionroot 加载一次,即可用于其下的所有加密数据集。
有关更多详细信息和高级用法,请参阅 encryptionroot、encryption、keylocation、keyformat 和 keystatus 属性,zfs load-key、zfs unload-key 和 zfs change-key 命令,以及 man zfs 的 Encryption 部分。
当对数据集启用压缩时,ZFS 会尝试在写入之前压缩所有 新 块,并在读取时解压它们。已经存在的数据(旧块)不会被追溯压缩。
您可以通过以下方式启用压缩:
# zfs set compression=<algorithm> <dataset>
我们推荐使用 lz4 算法,因为它只增加非常少的 CPU 开销。也可以用其它算法,例如 lzjb 和 gzip-N,其中 N 是从 1(最快)到 9(最佳压缩比)的整数。根据算法和数据的可压缩程度,启用压缩甚至可以提高 I/O 性能。
您可以随时通过以下命令禁用压缩:
# zfs set compression=off <dataset>
同样,只有新块会受到此更改的影响。
从 0.8.0 版本开始,ZFS 支持 专用 设备。池中的 专用 设备用于存储元数据、重复数据删除表和可选的小文件块。
一个 专用 的设备可以提高由慢速硬盘组成的池的速度,该池中包含大量“元数据更改”。例如,涉及创建、更新或删除大量文件的工作负载将受益于 专用 设备的存在。还可以将 ZFS 数据集配置为在 专用 设备上存储全部小文件,从而进一步提高性能。对 专用 设备使用快速 SSD 。
|
|
专用 设备的冗余应与池中的冗余相匹配,因为 专用 设备是整个池的故障点。 |
|
|
无法撤消添加到池中的 专用 设备! |
# zpool create -f -o ashift=12 <pool> mirror <device1> <device2> special mirror <device3> <device4>
# zpool add <pool> special mirror <device1> <device2>
ZFS 数据集阐明 special_small_blocks=<size> 属性。size(块大小)可以是 0 ,用于禁止在 专用 设备上存储小文件块;或者是 512B 到 128K 范围内的二次幂。设置属性后,将在 专用 设备上分配使用小于 size(块大小)的新文件块。
|
|
如果 special_small_blocks 的值大于或等于数据集的 recordsize(默认 128K),则 所有 数据都将写入到 专用 设备,因此要小心! |
设置池的 special_small_blocks 属性,将更改所有子 ZFS 数据集的该属性的默认值(例如,池中的所有容器都将选择小文件块)。
# zfs set special_small_blocks=4K <pool>
# zfs set special_small_blocks=4K <pool>/<filesystem>
# zfs set special_small_blocks=0 <pool>/<filesystem>
ZFS 中磁盘格式的更改仅在主要版本之间通过指定的 功能 进行。在 zpool-features(5) 手册页中详细记录了所有功能以及常规机制。
由于启用新功能会使旧版本的 ZFS 无法导入池,这需要管理员主动通过在池上运行 zpool upgrade 命令来完成(请参阅 zpool-upgrade(8) 手册页)。
除非您需要使用其中一项新功能,否则启用它们没有任何好处。
事实上,启用新功能有一些缺点:
由于在 grub 中与 ZFS 的实施不兼容,如果 rpool 上的新功能处于活动状态,则仍然使用 grub 引导的 ZFS 上的 root 系统将无法引导。
当使用旧内核启动时,系统将无法导入任何升级的池,旧内核仍然带有旧 ZFS 模块。
引导一个较旧的 Proxmox VE ISO 来修复一个非引导系统也同样不起作用。
|
|
如果系统仍然使用 grub 启动,请 不要 升级 rpool,这将使系统无法引导。这包括 Proxmox VE 5.4 之前已安装的系统,以及使用传统 BIOS 引导方式的系统启动(请参阅 如何确定 bootloader(引导加载程序))。 |
# zpool upgrade <pool>
|
|
BTRFS 目前是以 技术预览 的形式集成到 Proxmox VE。 |
BTRFS 是一个 Linux 内核原生支持的现代化写时复制的文件系统,通过数据校验和元数据,实现了例如快照、内建 RAID 和自我修复的功能。从 Proxmox VE 7.0 开始,引入 BTRFS 作为 root 文件系统的可选项。
主系统设置及传统的基于 ext4 的设置大同小异
快照
文件系统级别的数据压缩
写时复制克隆
RAID0,RAID1 和 RAID10
防止数据损坏
自我修复
Linux 内核原生支持
…
RAID 级别 5/6 具有实验性和危险性
当您使用 Proxmox VE 安装程序进行安装时,您可以选择 BTRFS 作为 root 文件系统,您需要在安装时选择 RAID 类型:
| RAID0 |
也称为“条带”。该卷的容量是所有磁盘容量的总和。但是 RAID0 并未添加任何冗余,因此单个驱动器的故障会导致卷无法使用。 |
| RAID1 |
也称为“镜像”。数据以相等的方式写入所有磁盘。此模式至少需要 2 个相同大小的磁盘,产生的容量是单个磁盘的容量。 |
| RAID10 |
RAID0 和 RAID1 的组合。至少需要 4 个磁盘。 |
安装程序会自动对磁盘进行分区,并在 /var/lib/pve/local-btrfs 上创建附加的子卷。为了与 Proxmox VE 工具一起使用,安装程序在 /etc/pve/storage.cfg 文件中创建下列配置条目:
dir: local
path /var/lib/vz
content iso,vztmpl,backup
disable
btrfs: local-btrfs
path /var/lib/pve/local-btrfs
content iso,vztmpl,backup,images,rootdir
这会明确地禁用默认的 本地 存储,转而支持附加在子卷上的 btrfs 所指定的存储条目。
btrfs 命令用于配置和管理 btrfs 文件系统,安装完成后,可以使用下列命令列出所有附加的子卷:
# btrfs subvolume list / ID 256 gen 6 top level 5 path var/lib/pve/local-btrfs
本节为您提供了一些常见任务的使用范例。
要创建 BTRFS 文件系统,可以使用 mkfs.btrfs。使用 -d 和 -m 参数,可分别用于设置元数据的配置文件和数据的配置文件。使用可选的 -L 参数,可以设置标签。
通常,以下模式均已支持:single、raid0、raid1、raid10。
在单磁盘 /dev/sdb 上创建一个使用标签 My-Storage 的 BTRFS 文件系统:
# mkfs.btrfs -m single -d single -L My-Storage /dev/sdb
或者在 /dev/sdb1 和 /dev/sdc1 这两个分区上创建一个 RAID1:
# mkfs.btrfs -m raid1 -d raid1 -L My-Storage /dev/sdb1 /dev/sdc1
然后可以手动挂载新的文件系统,例如:
# mkdir /my-storage # mount /dev/sdb /my-storage
BTRFS 也可以像任何其它挂载点一样添加到 /etc/fstab,在启动时自动挂载。建议避免使用块设备(block-device)路径,而是使用 mkfs.btrfs 命令打印的 UUID 值,尤其在 BTRFS 设置中有多个磁盘的情况下。
例如:
# ... other mount points left out for brevity # using the UUID from the mkfs.btrfs output is highly recommended UUID=e2c0c3ff-2114-4f54-b767-3a203e49f6f3 /my-storage btrfs defaults 0 0
|
|
如果没有可用的 UUID,您可以使用 blkid 工具列出块设备的所有属性。 |
然后,您可以通过执行以下命令触发第一次挂载:
mount /my-storage
下次重启后,系统在启动时将会自动完成挂载。
您可以通过 Web 界面或使用 CLI 将现有的 BTRFS 文件系统添加到 Proxmox VE,例如:
pvesm add btrfs my-storage --path /my-storage
创建一个子卷,并链接为 btrfs 文件系统中的一个路径,该路径将显示为一个常规目录。
# btrfs subvolume create /some/path
之后,/some/path 将像常规目录一样工作。
与通过 rmdir 命令删除目录相反,通过 btrfs 命令删除子卷无需为空。
# btrfs subvolume delete /some/path
BTRFS 实际上并未区分快照和普通子卷,因此生成快照也可以看作是子卷创建的任意副本。按照惯例,Proxmox VE 在创建来宾磁盘的快照或子卷的快照时将对其使用只读标志,但此标志也可以稍后更改。
# btrfs subvolume snapshot -r /some/path /a/new/path
将创建("克隆")一个 /some/path 只读的子卷到 /a/new/path,将来对 /some/path 的任何修改,都会导致修改后的数据在修改前已被复制。
如果省略只读 (-r) 选项,则两个子卷都将是可写的。
默认情况下,BTRFS 不压缩数据。要启用 压缩,可以添加压缩挂载选项。请注意,已写入的数据在事后不会被压缩。
默认情况下,将会在 /etc/fstab 中列出 rootfs(root 文件系统),如下所示:
UUID=<您的 root 文件系统的 uuid> / btrfs defaults 0 1
您可以简单地将 compress=zstd、compress=lzo 或 compress=zlib 追加到上面的 defaults 中,如下所示:
UUID=<您的 root 文件系统的 uuid> / btrfs defaults,compress=zstd 0 1
此更改将在重新启动后生效。
对于某些 btrfs 设置,经典工具 df 可能会输出令人困惑的值,要获得更好的估计值,建议使用 btrfs filesystem usage /PATH 命令,例如:
# btrfs fi usage /my-storage
Proxmox VE 节点管理工具(pvenode)允许您控制节点的特有设置和资源。
当前,pvenode 允许您设置节点的描述,在节点来宾(虚拟机)上运行各种批量操作,查看节点的任务历史记录,并管理节点的 SSL 证书,这些证书通过 pveproxy 用于 API 和 web GUI。
局域网唤醒(WoL)允许您通过发送一个魔术封包(magic packet),来启动在网络中休眠的计算机。至少需要一个 NIC 必须支持该功能,并需要在计算机的固件(BIOS/UEFI)的配置中启用相应的选项,选项的名称可以从 Enable Wake-on-Lan 变化为 Power On By PCIE Device;如果您不确定,请查阅主板的供应商手册。运行 ethtool 命令可以用来检查 <interface> 的 WoL 配置:
ethtool <interface> | grep Wake-on
pvenode 命令允许您通过 WoL 唤醒集群中休眠的节点,使用以下命令:
pvenode wakeonlan <node>
通过 UDP 的端口 9 广播 WoL 魔术封包(magic packet),其中包含从 wakeonlan 属性获得的 <node>(节点)的 MAC 地址。可以使用以下命令设置节点特有的 wakeonlan 属性:
pvenode config set -wakeonlan XX:XX:XX:XX:XX:XX
在排除服务器问题(例如,失败的备份任务)故障时,拥有之前运行的任务日志通常会有所帮助。使用 Proxmox VE,您可以通过 pvenode task 命令访问节点的任务历史记录。
您可以使用 list 子命令,获取节点中已完成任务的过滤列表。例如,要获取结束时出现错误的 VM 100 相关的任务列表,可以使用如下命令:
pvenode task list --errors --vmid 100
可以使用相应的 UPID 打印任务的日志:
pvenode task log UPID:pve1:00010D94:001CA6EA:6124E1B9:vzdump:100:root@pam:
如果您的许多 VM / 容器,可以使用 pvenode 的 startall 和 stopall 子命令批量完成启动和停止来宾的操作。默认情况下,pvenode startall 将仅能启动那些已设置为在开机自动启动的虚拟机/容器(请参阅 虚拟机的自动启动和关机),但是,您可以使用 --force 标志覆盖这个行为。这两个命令还有一个 --vms 选项,它通过指定 VMID 来限制停止/启动的来宾。
例如,要启动 VM 100、101 和 102,无论它们是否拥有 onboot 设置,都使用以下命令:
pvenode startall --vms 100,101,102 --force
要停止这些来宾以及可能正在运行的任何其它来宾,使用以下命令:
pvenode stopall
如果您的 VM / 容器依赖于启动缓慢的外部资源,例如 NFS 服务器,您还可以在 Proxmox VE 引导时间和已配置自动启动的第一台 VM /容器的引导时间之间设置每个节点的延迟。(请参阅 虚拟机的自动启动和关机)。
您可以通过以下设置来实现延迟(其中 10 表示以秒为单位的延迟):
pvenode config set --startall-onboot-delay 10
如果有升级情况需要您将所有来宾从一个节点迁移到另一个节点,pvenode 还提供 migrateall 子命令用于批量迁移。默认情况下,此命令会将系统上的每个来宾都迁移到目标节点。可以将其设置为仅迁移一组来宾。
例如,要将 VM 100、101 和 102 迁移到节点 pve2,并启用本地磁盘的实时迁移,您可以运行:
pvenode migrateall pve2 --vms 100,101,102 --with-local-disks
默认情况下,每个 Proxmox VE 集群都会创建自己的(自签名)证书颁发机构 (CA),并为每个节点生成一个由上述 CA 签名的证书。这些证书用于与集群的 pveproxy 服务和 Shell / 终端的功能(如果使用 SPICE)进行加密通信。
CA 证书和密钥存储在 Proxmox 集群文件系统 (pmxcfs) 中。
REST API 和 Web GUI 由每个节点上运行的 pveproxy 服务提供。
对于 pveproxy 使用的证书,您有以下选项:
默认情况下,使用 /etc/pve/nodes/NODENAME/pve-ssl.pem 作为节点指定的证书。此证书由集群 CA 签署,因此浏览器和操作系统不会自动信任它。
使用外部提供的证书(例如,由商业 CA 签署)。
使用 ACME(Let’s Encrypt)来获得一个自动续期的可信证书,这也已集成在 Proxmox VE API 和 Web 界面中。
对于选项 2 和 3,使用文件 /etc/pve/local/pveproxy-ssl.pem (和 /etc/pve/local/pveproxy-ssl.key,需要无密码)。
|
|
请记住,/etc/pve/local 是一个节点特定的符号链接,它指向 /etc/pve/nodes/NODENAME 。 |
通过 Proxmox VE 节点管理命令进行管理证书(请参阅 pvenode(1) 手册页)。
|
|
请勿替换或手动修改自动生成的节点证书文件(/etc/pve/local/pve-ssl.pem 和 /etc/pve/local/pve-ssl.key),或者群集 CA 文件(/etc/pve/pve-root-ca.pem 和 /etc/pve/priv/pve-root-ca.key)。 |
如果您已经拥有要用于 Proxmox VE 节点的证书,则只需通过 Web 界面上传该证书即可。
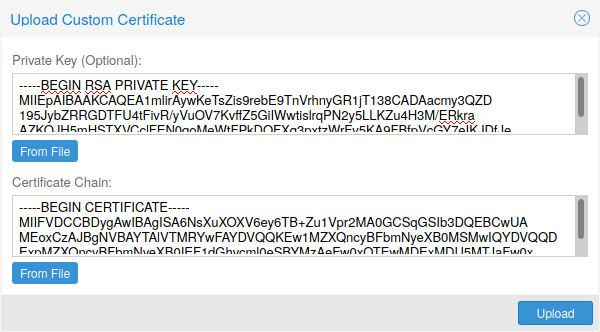
请注意,证书密钥文件(如果提供)不得受密码保护。
Proxmox VE 包含有一个 ACME(Automatic Certificate Management Environment,自动证书管理环境)协议的实现,允许 Proxmox VE 管理员使用类似 Let’s Encrypt 这样的 ACME 供应商来轻松设置 TLS 证书,这些证书在现代操作系统与 Web 浏览器上开箱即用,都是可接受与可信任的。
目前,实现的两个 ACME 端点是 Let’s Encrypt (LE) 产品和其暂存环境。我们的 ACME 客户端支持使用内置 Web 服务器校验 http-01 质询,并使用支持所有 DNS API 端点 acme.sh(shell 脚本) 的 DNS 插件验证 dns-01 质询。
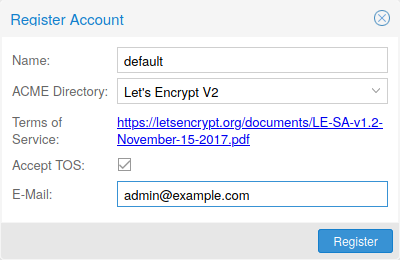
需要为每个具有您要使用的端点的的集群注册一个 ACME 帐户。该帐户使用的电子邮件地址将作为联络点,接收来自 ACME 端点的到期续费通知或类似的通知。
您可以通过 Web 界面的 数据中心 -> ACME 或使用 pvenode 命令行工具注册和停用 ACME 帐户。
pvenode acme account register account-name mail@example.com
|
|
因为 rate-limits(速率限制),您应该使用 LE 的 staging 进行试验,或者如果您是初次使用 ACME。 |
ACME 插件的任务是提供自动验证,确保您以及您操作下的 Proxmox VE 集群是域的真正所有者。这是自动证书管理的基础构件。
ACME 协议规定了质询的不同类型,例如 http-01,其中 Web 服务器提供一个具有特定内容的文件以证明其控制一个域。有时这是不可能的,要么是因为技术限制,要么是因为无法从公共互联网访问记录的地址。在这种情况下可以使用 dns-01 质询。这个质询是通过在域的区域内创建特定的 DNS 记录来完成的。
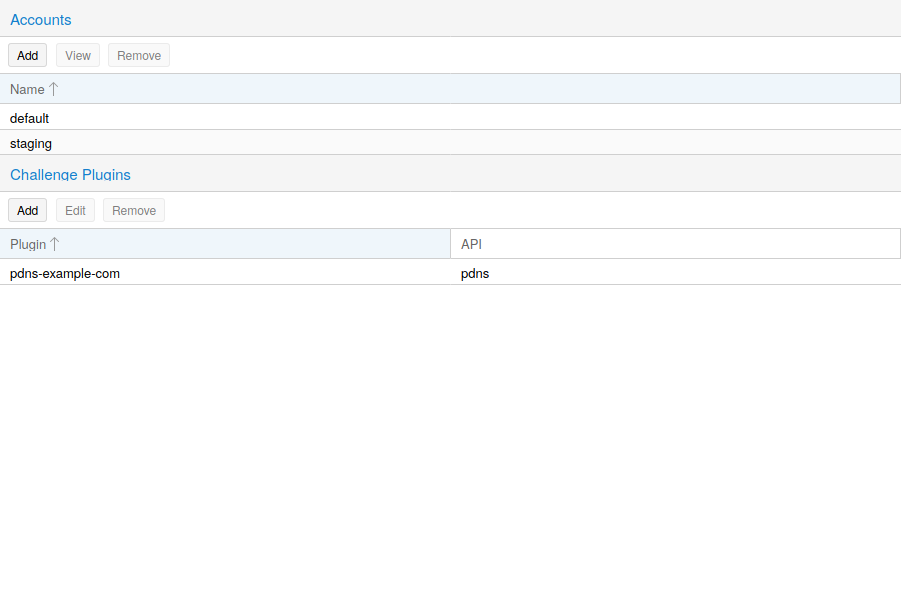
Proxmox VE 完全支持这两种质询类型,您可以通过 Web 界面下的 数据中心 -> ACME,或者使用 pvenode acme plugin add 命令来配置插件。
ACME 插件配置存放在 /etc/pve/priv/acme/plugins.cfg 。一个插件可用于集群中的所有节点。
每个域都是特定于节点的。您可以在 节点 -> 证书 下添加新的域条目或管理现有域条目,或使用 pvenode config 命令。
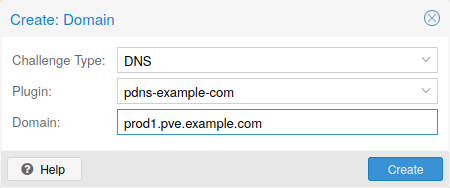
在为节点配置所需的域并确保选择了所需的 ACME 帐户后,您可以通过 Web 界面订购新证书。界面将在成功后 10 秒后重新加载。
将会 自动 续约。
始终有一个隐式配置的 独立 插件,内置 Web 服务器通过 80 端口验证 http-01 验证。
|
|
独立 这个名称意味着它可以自己提供验证,而无需任何第三方服务。因此,这个插件也适用于集群节点。 |
使用 Let’s Encrypts ACME 进行证书管理需要满足有一些先决条件。
您必须接受 Let's Encrypt 的 ToS 才能注册帐户。
从 Internet 必须可以访问节点的 80 端口 。
不得 有其他侦听器在侦听 80 端口。
请求的(子)域需要解析为节点的公共 IP 。
在无法或不希望使用外部访问的方式进行 http-01 方式验证的系统上,可以使用 dns-01 验证方式。该验证方法需要一个允许通过 API 配置 TXT 记录的 DNS 服务器。
Proxmox VE 重新使用为 acme.sh
[acme.sh https://github.com/acmesh-official/acme.sh]
项目开发的 DNS 插件,请参阅其文档以了解有关特定 API 配置的详细信息。
使用 DNS API 配置新插件的最简单方法是使用 Web 界面。(数据中心 -> ACME)。
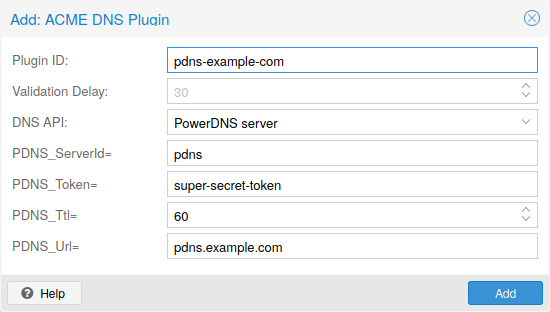
选择 DNS 作为质询类型。然后您可以选择您的 API 供应商,输入凭证数据后通过他们的 API 访问您的帐户。
|
|
查看 acme.sh 如何使用 DNS API 的 wiki ,了解有关为您的供应商获取 API 凭据的更多详细信息。 |
由于有许多 DNS 提供商和 API 端点,Proxmox VE 会自动为某些提供商生成凭据表单。对于其他的,您将看到一个更大的文本区域,只需将所有凭证 KEY=VALUE 成对复制到其中。
一个特殊的 别名(alias) 模式可用于处理不同域/DNS 服务器上的验证,以防您的主要/实际的 DNS 不支持通过 API 进行配置。手动设置 _acme-challenge.domain1.example 指向 _acme-challenge.domain2.example 的一个永久的CNAME 记录,并将 Proxmox VE 节点配置文件中的 alias(别名)属性设置为 domain2.example,允许 domain2.example 的 DNS 服务器验证 domain1.example 的所有质询。
如果您的节点可通过具有不同要求或 DNS 配置功能的多个域访问,则可以组合使用 http-01 和 dns-01 验证。通过为每个域指定不同的插件实例,也可以混合来自多个提供者或实例的 DNS API 。
|
|
通过多个域访问同一服务会增加复杂性,应尽可能避免。 |
如果一个节点已经成功配置了 ACME 提供的证书(无论通过 pvenode 还是通过 GUI),证书将通过 pve-daily-update.service 自动续订。目前,如果证书已经过期或将在接下来的 30 天内过期,则会尝试续订。
root@proxmox:~# pvenode acme account register default mail@example.invalid Directory endpoints: 0) Let's Encrypt V2 (https://acme-v02.api.letsencrypt.org/directory) 1) Let's Encrypt V2 Staging (https://acme-staging-v02.api.letsencrypt.org/directory) 2) Custom Enter selection: 1 Terms of Service: https://letsencrypt.org/documents/LE-SA-v1.2-November-15-2017.pdf Do you agree to the above terms? [y|N]y ... Task OK root@proxmox:~# pvenode config set --acme domains=example.invalid root@proxmox:~# pvenode acme cert order Loading ACME account details Placing ACME order ... Status is 'valid'! All domains validated! ... Downloading certificate Setting pveproxy certificate and key Restarting pveproxy Task OK
|
|
无论使用什么插件,注册账号的步骤都是一样的,这里不再赘述。 |
|
|
根据 OVH API 文档,需要从 OVH 获取 OVH_AK 和 OVH_AS 。 |
首先,您需要获取所有信息,以便您和 Proxmox VE 可以访问 API 。
root@proxmox:~# cat /path/to/api-token
OVH_AK=XXXXXXXXXXXXXXXX
OVH_AS=YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY
root@proxmox:~# source /path/to/api-token
root@proxmox:~# curl -XPOST -H"X-Ovh-Application: $OVH_AK" -H "Content-type: application/json" \
https://eu.api.ovh.com/1.0/auth/credential -d '{
"accessRules": [
{"method": "GET","path": "/auth/time"},
{"method": "GET","path": "/domain"},
{"method": "GET","path": "/domain/zone/*"},
{"method": "GET","path": "/domain/zone/*/record"},
{"method": "POST","path": "/domain/zone/*/record"},
{"method": "POST","path": "/domain/zone/*/refresh"},
{"method": "PUT","path": "/domain/zone/*/record/"},
{"method": "DELETE","path": "/domain/zone/*/record/*"}
]
}'
{"consumerKey":"ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ","state":"pendingValidation","validationUrl":"https://eu.api.ovh.com/auth/?credentialToken=AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA"}
(open validation URL and follow instructions to link Application Key with account/Consumer Key)
root@proxmox:~# echo "OVH_CK=ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ" >> /path/to/api-token
现在,您可以设置 ACME 插件:
root@proxmox:~# pvenode acme plugin add dns example_plugin --api ovh --data /path/to/api_token root@proxmox:~# pvenode acme plugin config example_plugin ┌────────┬──────────────────────────────────────────┐ │ key │ value │ ╞════════╪══════════════════════════════════════════╡ │ api │ ovh │ ├────────┼──────────────────────────────────────────┤ │ data │ OVH_AK=XXXXXXXXXXXXXXXX │ │ │ OVH_AS=YYYYYYYYYYYYYYYYYYYYYYYYYYYYYYYY │ │ │ OVH_CK=ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ │ ├────────┼──────────────────────────────────────────┤ │ digest │ 867fcf556363ca1bea866863093fcab83edf47a1 │ ├────────┼──────────────────────────────────────────┤ │ plugin │ example_plugin │ ├────────┼──────────────────────────────────────────┤ │ type │ dns │ └────────┴──────────────────────────────────────────┘
最后,您可以配置要获取证书的域,并为其下证书订单:
root@proxmox:~# pvenode config set -acmedomain0 example.proxmox.com,plugin=example_plugin root@proxmox:~# pvenode acme cert order Loading ACME account details Placing ACME order Order URL: https://acme-staging-v02.api.letsencrypt.org/acme/order/11111111/22222222 Getting authorization details from 'https://acme-staging-v02.api.letsencrypt.org/acme/authz-v3/33333333' The validation for example.proxmox.com is pending! [Wed Apr 22 09:25:30 CEST 2020] Using OVH endpoint: ovh-eu [Wed Apr 22 09:25:30 CEST 2020] Checking authentication [Wed Apr 22 09:25:30 CEST 2020] Consumer key is ok. [Wed Apr 22 09:25:31 CEST 2020] Adding record [Wed Apr 22 09:25:32 CEST 2020] Added, sleep 10 seconds. Add TXT record: _acme-challenge.example.proxmox.com Triggering validation Sleeping for 5 seconds Status is 'valid'! [Wed Apr 22 09:25:48 CEST 2020] Using OVH endpoint: ovh-eu [Wed Apr 22 09:25:48 CEST 2020] Checking authentication [Wed Apr 22 09:25:48 CEST 2020] Consumer key is ok. Remove TXT record: _acme-challenge.example.proxmox.com All domains validated! Creating CSR Checking order status Order is ready, finalizing order valid! Downloading certificate Setting pveproxy certificate and key Restarting pveproxy Task OK
不支持更改帐户的 ACME 目录,但由于 Proxmox VE 支持多个帐户,您可以使用生产(可信)ACME 目录作为端点创建一个新帐户。您还可以停用暂存帐户并重新创建它。
root@proxmox:~# pvenode acme account deactivate default Renaming account file from '/etc/pve/priv/acme/default' to '/etc/pve/priv/acme/_deactivated_default_4' Task OK root@proxmox:~# pvenode acme account register default example@proxmox.com Directory endpoints: 0) Let's Encrypt V2 (https://acme-v02.api.letsencrypt.org/directory) 1) Let's Encrypt V2 Staging (https://acme-staging-v02.api.letsencrypt.org/directory) 2) Custom Enter selection: 0 Terms of Service: https://letsencrypt.org/documents/LE-SA-v1.2-November-15-2017.pdf Do you agree to the above terms? [y|N]y ... Task OK
根据安装程序中选择的磁盘设置,Proxmox VE 当前使用两个引导加载程序中的其中一个。
一个是以 ZFS 作为 root 文件系统,已安装使用systemd-boot 的 EFI 系统,另一个是所有其他部署使用标准的 grub bootloader(引导加载程序)(这通常也适用于安装在 Debian 之上的系统)。
Proxmox VE 安装程序在所有选择安装的磁盘上创建 3 个分区。
创建的分区是:
一个 1MB 的 BIOS 引导分区(gdisk 类型 EF02)
一个 512MB 的 EFI 系统分区(ESP分区,gdisk 类型 EF00)
第三个,使用设置的 hdsize 参数的分区,或者将剩余空间使用所选存储类型的分区
在使用 ZFS 作为 root 文件系统的系统上,通过存储在 512MB 的 EFI 系统分区上的内核与 initrd 映像进行引导。对于传统的 BIOS 系统,使用 grub ,为 EFI 系统使用 systemd-boot。两个都已安装并配置为指向 ESP 分区。
BIOS 模式下的 grub(--target i386-pc)安装在所有使用 grub
[这些都是在 ext4 或 xfs 上使用 root 安装,在非 EFI 系统上使用 root 安装在 ZFS 上]
引导的系统上的所有选定磁盘的 BIOS 引导分区上。
proxmox-boot-tool是一个实用程序,用于保持正确地配置和同步 EFI 系统分区的内容。它将某些内核版本复制到所有 ESP 分区,并将相应的 bootloader(引导加载程序) 配置为从 vfat 格式的 ESP 分区引导。在 ZFS 作为 root 文件系统的环境中,这意味着您可以使用在 root 池上的所有可选功能,而不是在 grub 里存在的子集与 grub 里的 ZFS 实现也存在的子集,或者不得不创建一个单独的小引导池
[使用 grub 在 root 上引导 ZFS https://github.com/zfsonlinux/zfs/wiki/Debian-Stretch-Root-on-ZFS]
。
通过安装程序,使得在冗余设置中,所有磁盘都带有一个 ESP 分区。这样可以确保即使第一个引导设备故障或 BIOS 只能从特定磁盘引导,系统也能引导。
ESP 常规操作期间不会保持挂载状态。这有助于在系统崩溃时,防止文件系统损坏波及到 vfat 格式的 ESP 分区,并且在主引导设备出现故障时无需手动调整 /etc/fstab 。
proxmox-boot-tool 处理以下任务:
格式化并设置新的分区
将新的内核映像和 initrd 映像复制并配置到所有列出的 ESP
在内核升级和其他维护任务时同步配置
管理已同步的内核版本列表
您可以通过运行以下命令查看当前配置的 ESP 及其状态:
# proxmox-boot-tool status
要格式化和初始化一个分区为同步 ESP 分区,例如,在替换 rpool 中一个出现故障的 vdev 之后,或者在转换一个同步机制之前的现有系统时,可以使用 pve-kernel-helpers 中 proxmox-boot-tool 。
|
|
format(格式化)命令将格式化 <partition>(分区),确保传递给正确的设备或分区! |
例如,要格式化一个空的分区 /dev/sda2 作为 ESP 分区,运行下列命令:
# proxmox-boot-tool format /dev/sda2
要设置一个位于 /dev/sda2 上的现有的且未挂载的 ESP 分区,同时包含在 Proxmox VE 的内核更新同步机制中,使用以下命令:
# proxmox-boot-tool init /dev/sda2
之后在 /etc/kernel/proxmox-boot-uuids 中应该包含一个带有新添加分区的 UUID 的新行。init 命令还将自动触发所有已配置 ESP 分区的刷新。
要复制和配置所有可引导的内核,并使得 /etc/kernel/proxmox-boot-uuids 中列出的所有 ESP 分区保持同步,您只需要运行:
# proxmox-boot-tool refresh
(相当于以 root 权限,在使用 ext4 或 xfs 的系统上运行 update-grub)。
如果您更改了内核命令行,或者想要同步所有内核和 initrd,这是必要的操作。
|
|
update-initramfs 和 apt(必要时)都会自动触发刷新。 |
默认配置了以下内核版本:
当前正在运行的内核
软件包更新时新安装的版本
最新安装的两个内核
倒数第二个内核系列的最新版本(例如 5.0、5.3),如果适用
任何手动选择的内核
如果您希望将某个内核和 initrd 映像添加到可引导内核列表中,请使用 proxmox-boot-tool kernel add 命令。
例如,运行以下命令将 ABI 版本 5.0.15-1-pve 的内核添加到内核列表中,以保持安装并同步到所有 ESP 分区:
# proxmox-boot-tool kernel add 5.0.15-1-pve
proxmox-boot-tool kernel list 将列出当前选择用于引导的所有内核版本:
# proxmox-boot-tool kernel list Manually selected kernels: 5.0.15-1-pve Automatically selected kernels: 5.0.12-1-pve 4.15.18-18-pve
运行 proxmox-boot-tool kernel remove 从手动选择的内核列表中删除内核,例如:
# proxmox-boot-tool kernel remove 5.0.15-1-pve
|
|
从上面手动添加或删除内核后,需要运行 proxmox-boot-tool refresh 来更新所有 EFI 系统分区 (ESP 分区)。 |
确定使用哪个 bootloader(引导加载程序),最简单、最可靠的方法是观察 Proxmox VE 节点的引导过程。
您将看到 grub 的蓝色框,或简单黑白的 systemd-boot 。
从正在运行的系统确定引导加载程序可能不是 100% 准确。最安全的方法是运行以下命令:
# efibootmgr -v
如果它返回不支持 EFI 变量的消息,在 BIOS/Legacy 模式中使用 grub 。
如果输出包含类似于以下内容的行,则在 UEFI 模式下使用 grub 。
Boot0005* proxmox [...] File(\EFI\proxmox\grubx64.efi)
如果输出包含类似于以下内容的行,则使用 systemd-boot 。
Boot0006* Linux Boot Manager [...] File(\EFI\systemd\systemd-bootx64.efi)
通过运行:
# proxmox-boot-tool status
您可以查看是否配置了 proxmox-boot-tool,这很好地表明了系统是如何启动的。
grub多年来一直是引导 Linux 系统的事实上的标准,并且有很好的文档记录
[Grub 手册 https://www.gnu.org/software/grub/manual/grub/grub.html]
。
对 grub 配置的更改是通过默认文件 /etc/default/grub 或 /etc/default/grub.d 中的配置片段完成的。要在更改配置后重新生成配置文件,请运行:
[使用 proxmox-boot-tool 的系统将在 update-grub 调用 proxmox-boot-tool refresh。]
# update-grub
systemd-boot 是一个轻量级的 EFI 引导加载程序。它直接从安装它的 EFI 服务分区 (ESP 分区) 读取内核和 initrd 映像。直接从 ESP 分区加载内核的主要优点是不需要重新实现访问存储的驱动程序。在 Proxmox VE 中,proxmox-boot-tool 用于保持 ESP 分区上的配置同步。
systemd-boot 是通过 EFI 系统分区(ESP 分区)里的根(root)目录中的文件 loader/loader.conf 配置的。有关详细信息,请参阅 loader.conf(5) 手册页。
每个 bootloader(引导加载程序)的条目都放置在目录 loader/entries/ 下的自己的文件中。
一个 entry.conf 的范例如下所示(/ 指的是 ESP 分区的根(root)):
title Proxmox version 5.0.15-1-pve options root=ZFS=rpool/ROOT/pve-1 boot=zfs linux /EFI/proxmox/5.0.15-1-pve/vmlinuz-5.0.15-1-pve initrd /EFI/proxmox/5.0.15-1-pve/initrd.img-5.0.15-1-pve
根据使用的 bootloader(引导加载程序),您可以在以下位置修改内核命令行:
内核命令行需要放置在文件 /etc/default/grub 中的变量 GRUB_CMDLINE_LINUX_DEFAULT 中。运行 update-grub 会将其内容附加到文件 /boot/grub/grub.cfg 中的所有 linux 条目。
内核命令行需要作为一行放置在 /etc/kernel/cmdline 文件中。要应用更改,请运行 proxmox-boot-tool refresh,它将其设置为 loader/entries/proxmox-*.conf 中所有配置文件的 option 行。
Proxmox VE 很简单。无需安装单独的管理工具,一切都可以通过您的浏览器完成(首选最新版的 Firefox 或 Google Chrome)。内置了 HTML5 控制台用于访问来宾控制台,还可以使用 SPICE 作为替代方案。
因为我们使用 Proxmox 集群文件系统(pmxcfs),您可以连接到任何节点来管理整个集群。每个节点可以管理整个集群,不需要专用的管理员节点。
您可以在任何现代的浏览器中使用基于 Web 的管理界面。当 Proxmox VE 检测到您正在从移动设备连接时,您将被重定向到一个更简单的、基于触摸的用户界面。
可以通过 https://youripaddress:8006 访问 Web 界面(默认登录名为:root,密码为安装过程中指定的密码)。
Proxmox VE 集群的无缝集成和管理
用于资源动态更新的 AJAX 技术
通过 SSL 加密(https)安全访问所有虚拟机和容器
快速搜索驱动的界面,能够处理成百上千个虚拟机
安全的 HTML5 控制台或 SPICE
所有对象( VM 、存储、节点等)的基于角色的权限管理
支持多个身份验证源(例如本地、MSADS、LDAP等)
二次验证(OATH、Yubikey)
基于 ExtJS 6.x JavaScript 框架
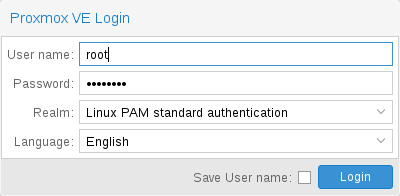
当连接到服务器,您首先会看到登录窗口。Proxmox VE 支持各种身份验证的后端(领域),同时您可以在这里选择语言,GUI 界面已被翻译超过 20 种语言。
|
|
您可以通过选择底部的复选框,在客户端保存用户名。这可以在您下次登录时节省一些输入。 |
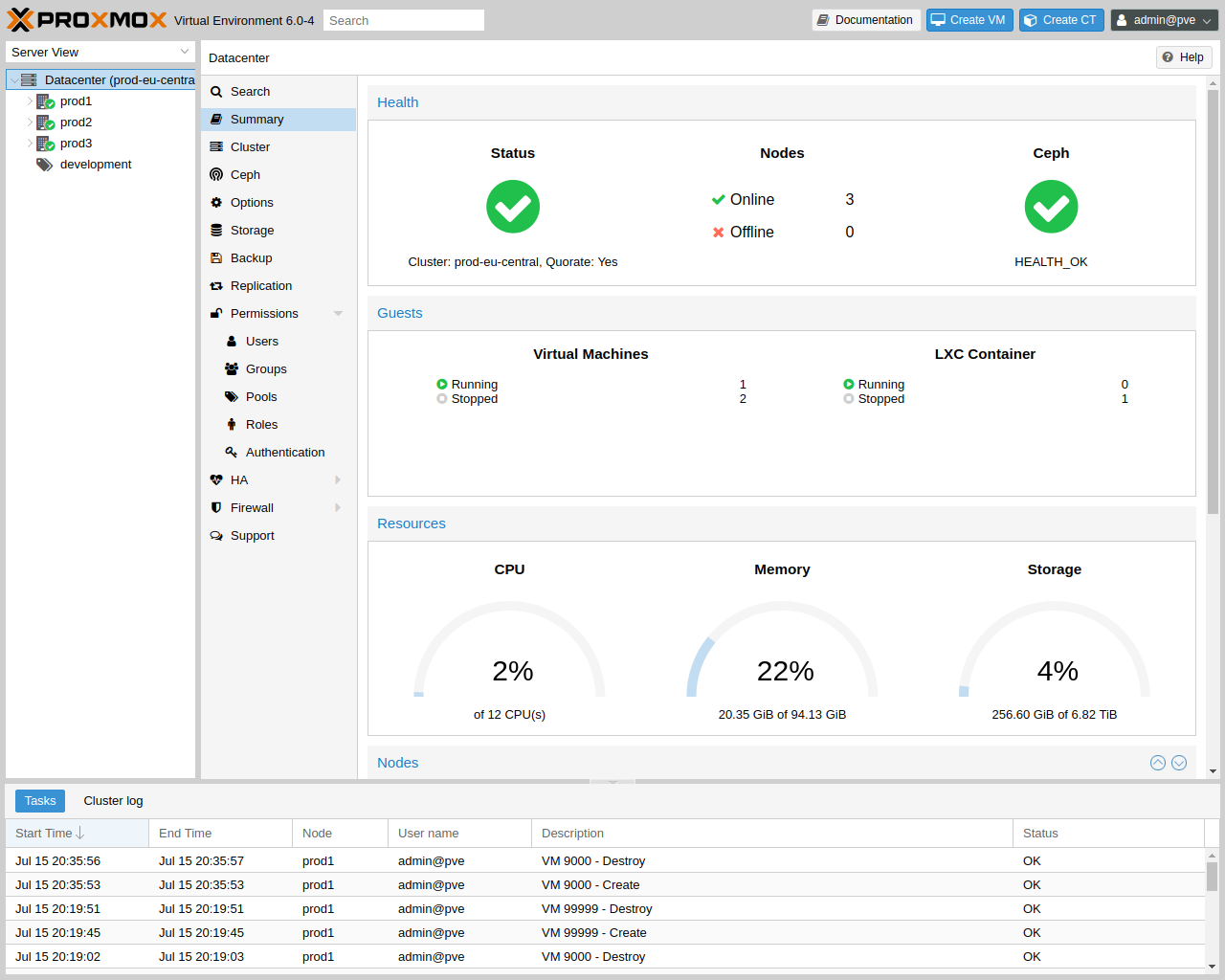
Proxmox VE 的用户界面由四个区域组成。
| 页眉 |
最上面。显示状态信息并包括最重要操作的按钮。 |
| 资源树 |
在左侧。您可以在其中选择特定对象的导航树。 |
| 内容面板 |
中间区域。选定对象在此显示配置选项和状态。 |
| 日志面板 |
在底部。显示最近任务的日志条目。您可以双击这些日志条目以获取更多详细信息,或中止正在运行的任务。 |
|
|
您可以缩小和扩展资源树和日志面板的大小,或者完全隐藏日志面板。当您在小型显示器上工作并需要更多空间来查看其他内容时,这会很有帮助。 |
在左上角,您首先看到的是 Proxmox logo 标志。接下来是 Proxmox VE 当前运行的版本。在左侧的搜索栏中,您可以搜索特定的对象( VM 、容器、节点等)。这有时比在资源树中选择一个对象要快。
在搜索栏的右侧,我们会看到身份标识(登录名)。齿轮符号按钮用于打开 我的设置 对话框。在那里,您可以自定义一些客户端用户界面设置(重置已保存的登录名、重置已保存的布局)
页眉的最右侧部分包含四个按钮:
| 文档 |
打开一个新的浏览器窗口,显示参考文档。 |
| 创建虚拟机 |
打开虚拟机创建向导。 |
| 创建 CT |
打开容器创建向导。 |
| 注销 |
注销,并再次显示登录对话框。 |
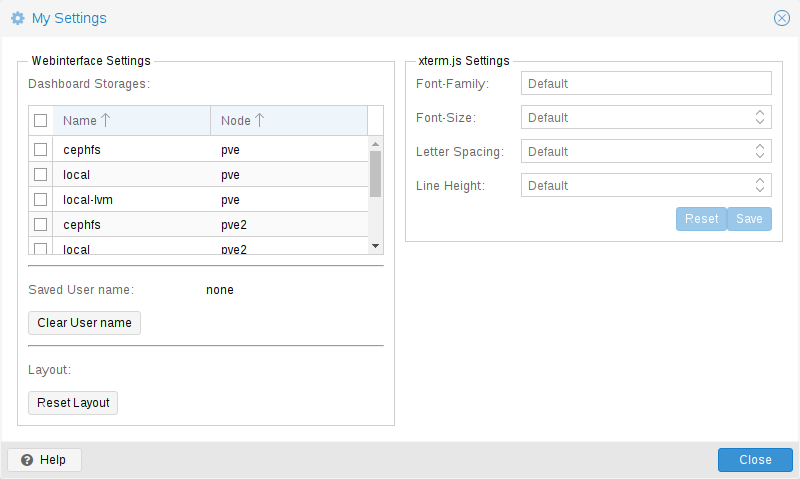
我的设置 窗口允许您设定本地存储的设置。其中包括 仪表板存储,它允许您启用或禁用特定存储,用以计入数据中心摘要中可见的总量。如果未选择任何存储,则总数为所有存储的总和,等同于启用每个存储。
在仪表板设置下面,您可以找到已保存的用户名和一个清除它的 重置 按钮,以及一个将 GUI 的所有布局重置为默认值的 重置 按钮。
在右侧是 xterm.js 设置 。这些包含以下选项:
| 字体系列 |
在 xterm.js 中使用的字体(例如 Arial)。 |
| 字体大小 |
要使用的首选字体大小。 |
| 字母间距 |
增加或减少文本中字母之间的间距。 |
| 行高 |
指定行的绝对高度。 |
这是主导航树。在树的顶部,您可以选择一些预定义的视图,这些视图会更改下面树的结构。默认视图是 服务器视图,它显示以下对象类型:
| 数据中心 |
包括集群范围内的设置(与所有节点相关) |
| 节点 |
代表集群内的主机,来宾在其中运行。 |
| 来宾 |
VM ,CT 和模板 |
| 存储 |
数据存储。 |
| 资源池 |
可以使用资源池将来宾分组以简化管理。 |
以下视图类型可用:
| 服务器视图 |
显示按节点分组的各种对象。 |
| 文件夹视图 |
显示按对象类型分组的各种对象。 |
| 存储视图 |
仅显示按节点分组的存储对象。 |
| 资源池视图 |
显示按资源池分组的 VM 和容器。 |
日志面板的主要目的是向您展示集群中当前正发生的事情。诸如创建新的 VM 之类的操作在后台执行,我们将这种后台作业称为 任务 。
此类任务的任何输出都保存在单独的日志文件中。您只需要双击一个任务日志条目即可查看该日志,也可以在那里中止正在运行的任务。
请注意,我们在此处显示了所有集群节点的最新任务。因此,您可以实时查看其他人何时在另一个集群节点上工作。
|
|
我们从日志面板中删除旧的和已完成的任务,以保持该列表简短。但是,您仍然可以在节点面板中的 任务历史 里找到这些任务的记录。 |
有些短期运行的操作只是将日志发送到所有集群成员。您可以在 集群日志 面板中看到这些消息。
当从资源树中选择一个项目时,相应的对象会在内容面板中显示配置和状态信息。以下章节简要概述了这些功能。请参阅参考文档中的相应章节以获取更多详细的信息。
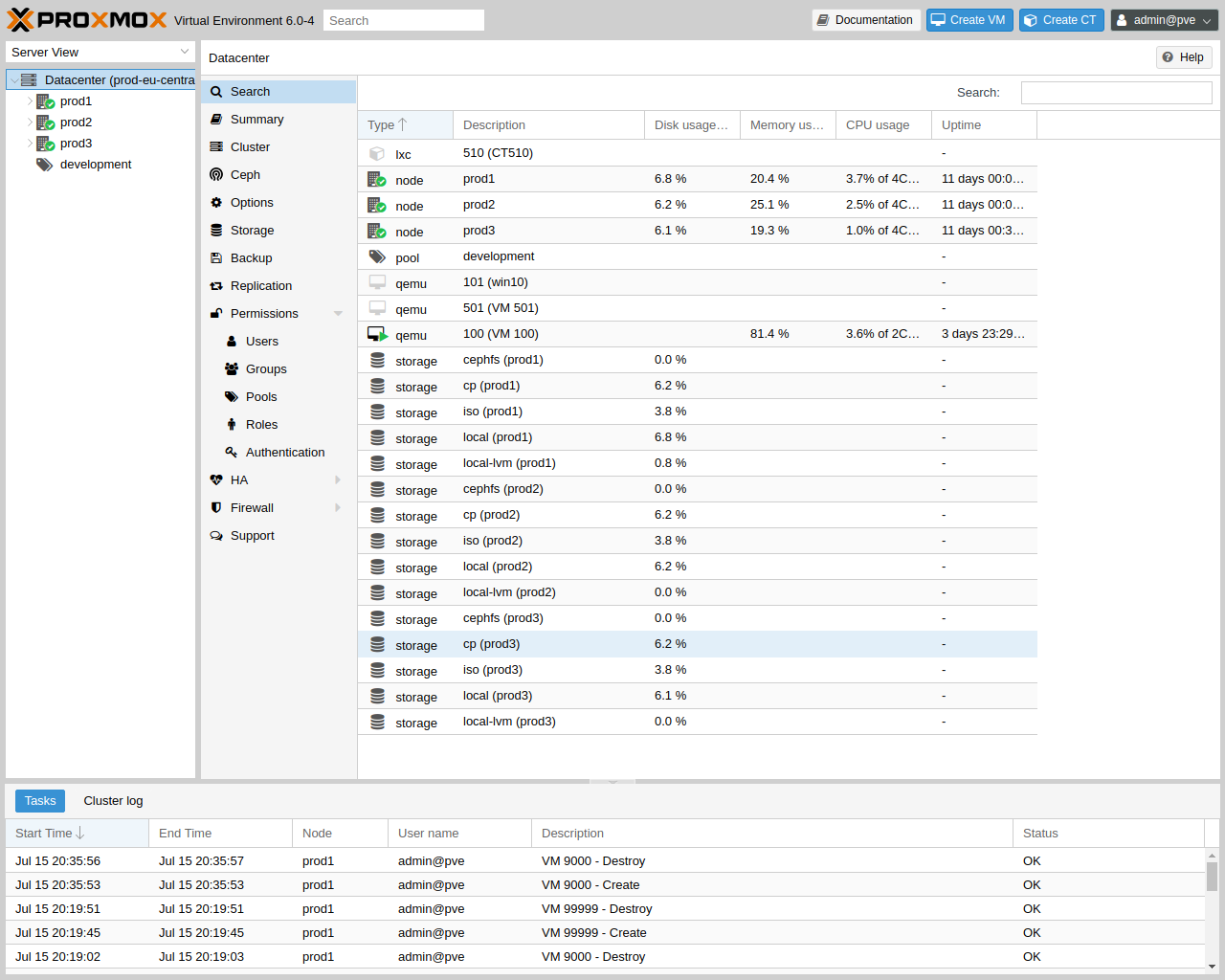
在数据中心级别,您可以访问集群范围的设置和信息。
搜索:对节点、 VM 、容器、存储设备和资源池执行集群范围的搜索。
摘要:简要概述集群的健康状况和资源使用情况。
集群:提供创建或加入集群所需的功能和信息。
选项:查看和管理集群范围的默认设置。
存储:提供用于管理集群存储的界面。
备份:计划备份作业。这在集群范围内运行,因此在调度时,VM 或容器在集群上的位置无关紧要。
复制:查看和管理复制作业
权限:管理用户、群组和 API 令牌权限,以及 LDAP、MS-AD 和二次验证。
HA:管理 Proxmox VE 高可用性。
ACME:为服务器节点设置 ACME(Let’s Encrypt)证书。
防火墙:为 Proxmox 防火墙集群范围配置和制作模板。
度量服务器:为 Proxmox VE 定义外部度量服务器。
支持:显示有关您的支持订阅的信息。
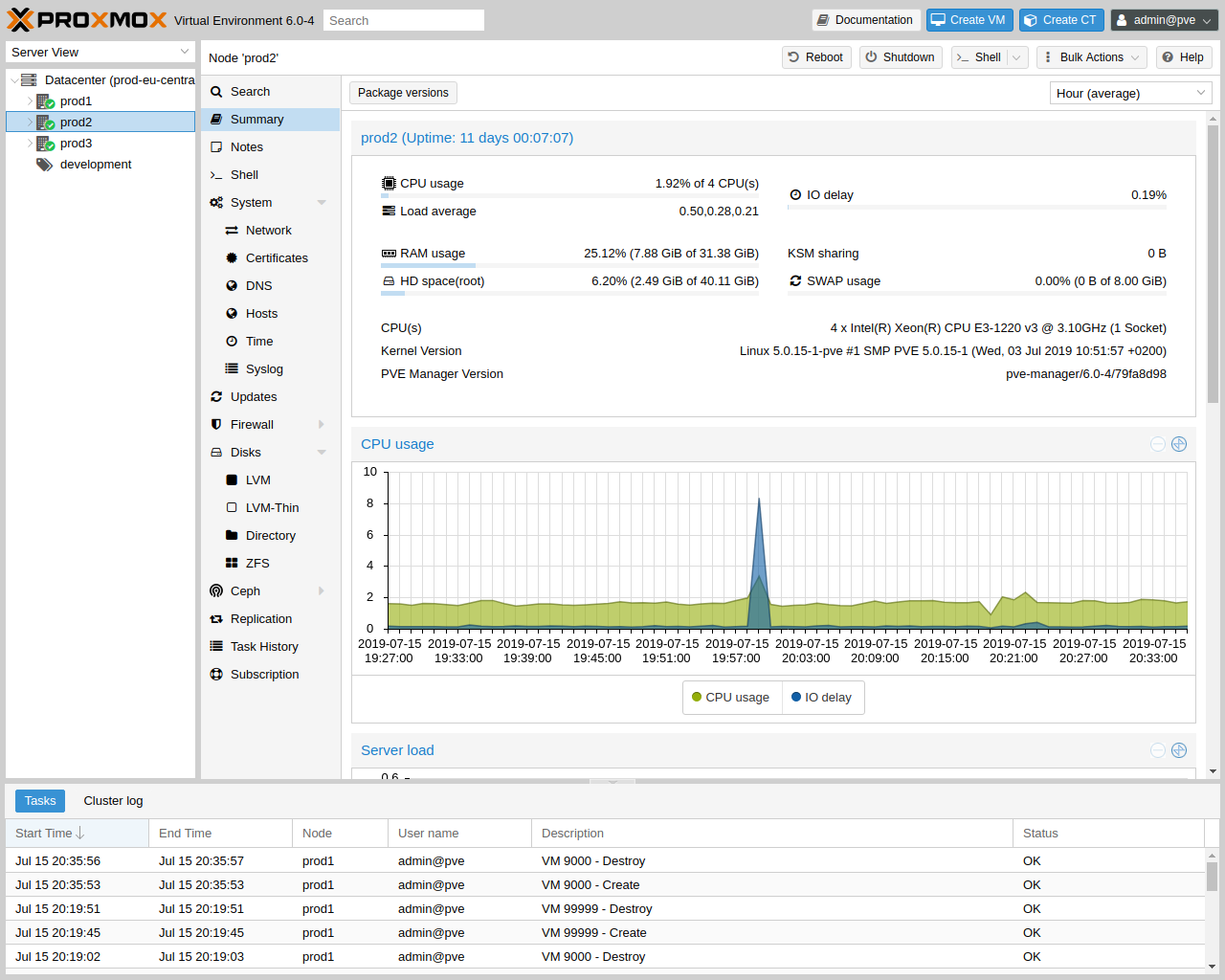
集群中的节点可以在此级别单独管理。
顶部页眉有一些有用的按钮,例如 重启、关机、Shell、批量操作 和 帮助。Shell 有 noVNC、SPICE 和 xterm.js 选项。批量操作 有 批量启动、批量停止 和 批量迁移 选项。
搜索:搜索节点中的 VM 、容器、存储设备和资源池。
摘要:显示节点资源使用情况的简要概述。
备注:使用 Markdown 语法 书写自定义的备注。
Shell:访问节点的 shell 界面。
系统:配置网络、DNS和时区设置,以及访问 syslog(系统日志)。
更新:升级系统并查看可用的新软件包。
防火墙:管理特定节点的 Proxmox 防火墙。
磁盘:获得附加磁盘的概览,并管理的它们使用方式。
Ceph:仅在您的主机安装了 Ceph 服务器时使用。在这种情况下,您可以管理 Ceph 集群并在此处查看它的状态。
复制:查看和管理复制作业。
任务历史: 查看过去的任务列表。
订阅:上传订阅密钥,并生成用于支持案例的系统报告。
有两种不同类型的来宾,两者都可以转换为模板。一个是基于内核的虚拟机(KVM),另一个是 Linux 容器(LXC)。这些的导航基本相同;只有一些选项不同。
要访问来宾的各种管理界面,请在左侧菜单中选择一个 VM 或容器。
页眉包含诸如电源管理、迁移、控制台访问以及类型,克隆、HA 以及帮助等项目的命令。其中一些按钮包含下拉菜单,例如,关机 还包含其他电源选项,控制台 包括不同的控制台类型:SPICE、noVNC 和 xterm.js。
右侧的面板包含一个界面,用于显示从左侧菜单中选择的任何项目。
可用的界面如下所示。
摘要: 提供 VM 活动的简要概述,以及使用 Markdown 语法 注释的 备注 区域。
控制台:访问 VM /容器的交互式控制台。
硬件(虚拟机):定义 KVM VM 可用的硬件。
资源(容器):定义 LXC 容器可用的系统资源。
网络(容器):配置容器的网络设置。
DNS(容器):配置容器的 DNS 设置。
选项:管理来宾选项。
任务历史:查看与所选来宾相关的所有先前任务。
监视器(虚拟机):KVM 进程的交互式通信接口。
备份:创建与恢复系统备份。
复制:查看和管理所选来宾的复制作业。
快照:创建与恢复 VM 的快照。
防火墙:在 VM 级别配置防火墙。
权限:管理所选来宾的权限。
与来宾界面一样,存储界面由左侧的某些存储元素的菜单和右侧的用于管理这些元素的界面组成。
在这个视图中,我们有一个两个分区的拆分视图。在左侧,我们有存储选项,在右侧,将显示所选选项的内容。
摘要:显示关于存储的重要信息,例如存储的类型、用量以及所存储的内容。
内容:存储中储存的每种内容类型的菜单项,例如备份、ISO 光盘映像、CT 模板。
权限:管理存储的权限。
同样,资源池视图包含两个分区:左侧的菜单和右侧每个菜单项的对应界面。
摘要:显示资源池的描述。
成员:显示和管理资源池成员(来宾和存储)。
权限:管理资源池的权限。
Proxmox VE 集群管理器 pvecm 是一个用于创建一组物理服务器的工具。这样的组称为 集群。我们使用 Corosync Cluster Engine 实现可靠的组通信。集群中的节点数量没有明确的限制。实际上,实际可用的节点数可能会受到主机和网络性能的限制。目前(2021 年),有报告称在生产环境中有超过50个节点的集群(使用高端企业硬件)。
pvecm 可用于创建新的集群,将节点加入到集群,离开集群,获取状态信息以及执行各种其他集群相关的任务。使用 Proxmox 集群文件系统(Proxmox Cluster File System (简称“pmxcfs”)),将集群配置透明地分发到所有集群节点。
将节点组合到集群中具有以下优点:
基于 Web 的集中管理
多主集群:每个节点可以做所有的管理任务
使用数据库驱动的文件系统 pmxcfs 来存储配置文件,使用 corosync 在所有节点上实时复制
在物理主机之间轻松迁移虚拟机和容器
快速部署
集群范围的服务,比如防火墙和 HA(高可用性)
所有节点必须能够通过 UDP 端口 5404 和 5405 相互连接,以便 corosync 可以正常工作。
日期和时间必须同步。
需要在节点之间的 TCP 端口 22 上建立 SSH 隧道。
如果您对高可用性感兴趣,则需要至少三个节点才能获得可靠的仲裁(quorum)。所有节点都应该具有相同的版本。
我们建议为集群流量使用专用 NIC,尤其是在您使用共享存储时。
添加节点需要集群节点的 root 密码。
|
|
Proxmox VE 3.x 及更早版本无法与 Proxmox VE 4.X 版本的集群节点混合使用。 |
|
|
虽然可以混合 Proxmox VE 4.4 和 Proxmox VE 5.0 节点,但不支持将其作为生产的配置,且只能在将整个集群从一个主要版本升级到另一个主要版本期间临时进行。 |
|
|
无法运行具有早期版本的 Proxmox VE 6.x 集群。Proxmox VE 6.x 和更早版本之间的集群协议(corosync)发生了根本性的变化。Proxmox VE 5.4 的 corosync 3 软件包仅计划用于升级到 Proxmox VE 6.0 的过程。 |
首先,在所有节点上安装 Proxmox VE 。确保每个节点都安装了最终的主机名和 IP 配置。创建集群后无法更改主机名和 IP 。
虽然在 /etc/hosts 中引用所有节点名称及其 IP(或通过其他方式解析它们的名称)是很常见的,但这对于集群的工作来说不是必需的。但是,它可能很有用,因为您可以使用更容易记住的节点名称(另请参阅 链接地址类型),通过 SSH 从一个节点连接到另一个节点。请注意,我们始终建议在集群配置中根据节点的IP地址引用节点。
您可以在控制台(通过登录 ssh)上创建集群,也可以通过 API 使用 Proxmox VE Web 界面(数据中心 → 集群)。
|
|
为您的集群使用唯一的名称。此名称以后无法更改。集群名称遵循与节点名称相同的规则。 |
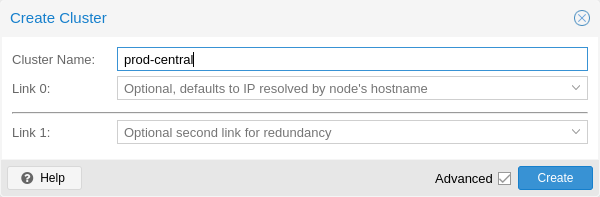
在 数据中心 → 集群 下, 单击 创建集群。输入集群名称并从下拉列表中选择一个网络连接作为主集群网络(Link 0)。它默认为通过节点的主机名解析的 IP。
从 Proxmox VE 6.2 开始,最多可以向一个集群添加 8 个后备(fallback)链接。要添加冗余链接,请单击 添加 按钮,然后从相应字段中选择链接编号和 IP 地址。在 Proxmox VE 6.2 之前,要添加第二个链接作为后备,您可以选中 高级 复选框并选择其他网络接口(Link 1,另请参见 Corosync 冗余)。
|
|
确保为集群通信选择的网络不用于任何高流量的用途,例如网络存储或实时迁移。虽然集群网络本身产生少量数据,但它对延迟非常敏感。查看完整的集群网络要求。集群网络需求。 |
通过 ssh 登录到第一个 Proxmox VE 节点并运行以下命令:
hp1# pvecm create CLUSTERNAME
要检查新集群的状态,请使用:
hp1# pvecm status
可以在同一个物理或逻辑网络中创建多个集群。在这种情况下,每个集群必须有一个唯一的名字,以避免在集群通信堆栈中可能发生的冲突。此外,通过使集群区别明显,有助于避免人为混淆。
虽然 corosync 集群的带宽需求相对较低,但是包延迟和包转发率(PPS)是限制因素。在同一网络中的不同集群可以相互竞争这些资源,因此,对于更大的集群使用单独的物理基础设施仍然是有意义的。
|
|
即将添加到集群的节点不能容纳任何来宾。加入集群时,在 /etc/pve 中的所有现有配置都将被覆盖,否则来宾的 ID 可能会发生冲突。作为一种变通方法,您可以在将节点添加到集群后,创建来宾的备份(vzdump)并以不同的 ID 恢复它。 |
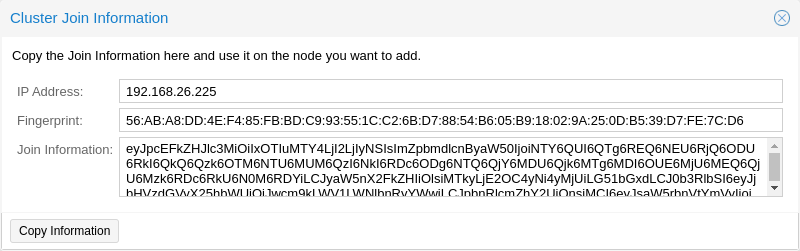
登录到现有集群节点上的 Web 界面。在数据中心 → 集群 下面,单击顶部的 加入信息 按钮。然后,单击 复制信息 按钮。或者,手动复制 信息 字段的字符串。
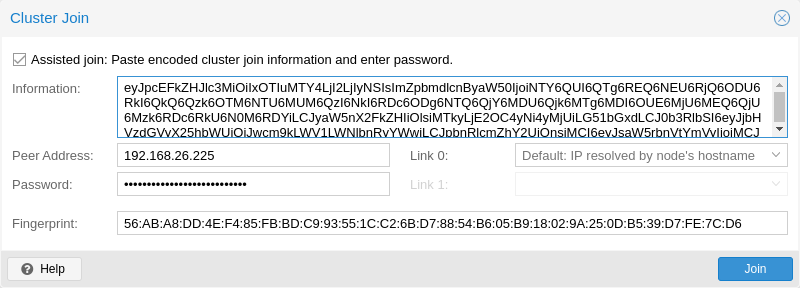
接下来,登录到要添加的节点上的 Web 界面。在 数据中心 → 集群 下面,单击 加入集群 。使用您之前复制的 加入信息 文本填写到 信息 字段。加入集群的大多数设置将自动填写。出于安全原因,必须手动输入集群的密码。
|
|
要手动输入所有必需的数据,您可以禁用 辅助加入 复选框。 |
单击 加入 按钮后,集群加入过程将立即开始。节点加入集群以后,它当前的节点证书将由集群证书颁发机构(CA)签署的证书替换。这意味着当前会话将在几秒钟后停止工作。然后您可能需要强制重载 Web 界面并使用集群凭据再次登陆。
现在,您的节点应该在 数据中心 → 集群 下可见。
通过 ssh 登录到要加入到现有集群的节点。
# pvecm add IP-ADDRESS-CLUSTER
对于 IP-ADDRESS-CLUSTER ,使用现有集群节点的 IP 或主机名。建议使用 IP 地址(请参阅 链路地址类型)。
要检查集群的状态,请使用:
# pvecm status
# pvecm status
Cluster information
~~~~~~~~~~~~~~~~~~~
Name: prod-central
Config Version: 3
Transport: knet
Secure auth: on
Quorum information
~~~~~~~~~~~~~~~~~~
Date: Tue Sep 14 11:06:47 2021
Quorum provider: corosync_votequorum
Nodes: 4
Node ID: 0x00000001
Ring ID: 1.1a8
Quorate: Yes
Votequorum information
~~~~~~~~~~~~~~~~~~~~~~
Expected votes: 4
Highest expected: 4
Total votes: 4
Quorum: 3
Flags: Quorate
Membership information
~~~~~~~~~~~~~~~~~~~~~~
Nodeid Votes Name
0x00000001 1 192.168.15.91
0x00000002 1 192.168.15.92 (local)
0x00000003 1 192.168.15.93
0x00000004 1 192.168.15.94
如果只想列出所有节点,请使用:
# pvecm nodes
# pvecm nodes
Membership information
~~~~~~~~~~~~~~~~~~~~~~
Nodeid Votes Name
1 1 hp1
2 1 hp2 (local)
3 1 hp3
4 1 hp4在集群网络分离的集群中添加节点时,需要使用 link0 参数设置该网络上的节点地址:
pvecm add IP-ADDRESS-CLUSTER -link0 LOCAL-IP-ADDRESS-LINK0
如果要使用 Kronosnet 传输层的内置 冗余,还要使用 link1 参数。
使用 GUI 界面,您可以从 加入集群 对话框中相应的 Link X 字段中选择正确的接口。
|
|
在继续之前仔细阅读该过程,因为它可能不是您想要或需要的。 |
从节点移动所有虚拟机。确保您已经生成了要保留的任何本地数据或备份的副本。此外,请确保要删除的节点已经删除掉任何计划的复制作业。
|
|
在删除节点之前未能将复制作业删除,将导致复制作业变得不可删除。特别要注意的是,如果迁移复制的 VM ,复制会自动切换方向,因此通过从要删除的节点迁移复制的 VM ,复制作业将会自动设置到该节点。 |
在以下范例中,我们将从集群中删除节点 hp4 。
登录到一个 不同的 集群节点(非 hp4),并发出 pvecm nodes 命令来标识要删除的节点 ID:
hp1# pvecm nodes
Membership information
~~~~~~~~~~~~~~~~~~~~~~
Nodeid Votes Name
1 1 hp1 (local)
2 1 hp2
3 1 hp3
4 1 hp4此时,您必须关闭 hp4 并确保它不会以其当前的配置再次启动(在网络中)。
|
|
如上所述,在移除节点之前关闭电源至关重要,并确保它将不会以其当前的配置再次开启(在现在集群网络中)。如果按原样开启节点,集群最终可能会损坏,并且可能难以将其恢复到正常运行状态。 |
关闭节点 hp4 的电源后,我们可以安全地将其从集群中移除。
hp1# pvecm delnode hp4 Killing node 4
|
|
此时,您可能会接收到一条显示为 Could not kill node (error = CS_ERR_NOT_EXIST)(无法终止节点) 的错误消息。实际上这并不意味着节点删除失败,更准确的说是在尝试停止离线节点的 corosync 时发生失败。因此,可以安全地忽略它。 |
使用 pvecm nodes 或 pvecm status 再次检查节点列表。它应该看起来像:
hp1# pvecm status
...
Votequorum information
~~~~~~~~~~~~~~~~~~~~~~
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate
Membership information
~~~~~~~~~~~~~~~~~~~~~~
Nodeid Votes Name
0x00000001 1 192.168.15.90 (local)
0x00000002 1 192.168.15.91
0x00000003 1 192.168.15.92无论出于何种原因,如果您希望此服务器再次加入同一个集群,您必须:
在其上重新安装 Proxmox VE
然后加入它,如前一节所述。
|
|
移除节点以后,它的 SSH 指纹信息仍将驻留在其他节点的已知主机(known_hosts)中。如果在重新加入具有相同 IP 或主机名的节点后收到一个 SSH 错误,请在重新添加的节点上运行一次 pvecm updatecerts 以更新集群范围的指纹信息。 |
|
|
这 不是 推荐的方法,请谨慎操作。如果您不确定,请使用前面的方法。 |
您还可以将节点与集群分离,而无需从头开始重新安装。但是从集群中删除节点后,它仍然可以访问任何共享存储。这必须在开始从集群中删除节点之前解决此问题。Proxmox VE 集群不能与另一个集群共享完全相同的存储,因为存储锁定在集群边界上不起作用。此外,它还可能导致 VMID 冲突。
建议您新建一个存储,只有您要分离的节点才能访问。仅举几个例子,这可以是 NFS 上新导出的或者新的 Ceph 资源池。很重要的一点是多个集群不会访问完全相同的存储。设置此存储后,将所有数据和 VM 从节点移动到该存储。然后您可以将节点从集群中分离出来了。
|
|
确保所有共享资源完全分离!否则您会遇到冲突和问题。 |
首先,停止节点上的 corosync 和 pve-cluster 服务:
systemctl stop pve-cluster systemctl stop corosync
在本地模式下再次启动集群文件系统:
pmxcfs -l
删除 corosync 配置文件:
rm /etc/pve/corosync.conf rm -r /etc/corosync/*
现在,您可以把文件系统作为普通服务再次启动:
killall pmxcfs systemctl start pve-cluster
该节点现在与集群分离。您可以使用以下命令从集群的任何其余节点中删除它:
pvecm delnode oldnode
如果由于剩余节点中的仲裁(quorum)丢失而导致命令失败,您可以将预期投票数(votes)设置为 1 作为解决方法:
pvecm expected 1然后重复 pvecm delnode 命令。
现在切换回分离的节点并删除其上所有剩余的集群文件。这确保节点可以毫无问题地再次添加到另一个集群。
rm /var/lib/corosync/*由于来自其他节点的配置文件仍在集群文件系统中,您可能也需要清理它们。在绝对确保您拥有正确的节点名称后,您可以简单地从 /etc/pve/nodes/NODENAME(节点名称) 递归删除整个目录
|
|
节点的 SSH 密钥将保留在 authorized_key 文件中。这意味着节点仍然可以通过公钥认证相互连接。您可以从 /etc/pve/priv/authorized_keys 文件中删除相应的密钥来解决此问题。 |
Proxmox VE 使用基于仲裁(quorum)的技术在所有集群节点之间提供一致的状态。
仲裁(quorum)是分布式事务必须获得的最小投票数,以便允许在分布式系统中执行操作。
在网络分区的情况下,状态更改需要大多数节点在线。如果失去仲裁,集群将切换到只读模式。
|
|
默认情况下,Proxmox VE 为每个节点分配一票。 |
集群网络是集群的核心。通过它发送的所有消息都必须按照各自的顺序可靠地传递给所有节点。在 Proxmox VE 中,这部分由 corosync 完成,这是一个高性能、低开销、高可用性的开发工具箱的实现。它提供给我们一个去中心化配置的文件系统。(pmxcfs,即 Proxmox VE 集群文件系统)。
这需要一个延迟低于 2 毫秒(LAN 性能)的可靠网络才能正常工作。该网络不应被其他成员大量使用;理想情况下,corosync 运行在自己的网络上。不要将共享网络用于 corosync 和存储(除非作为 冗余 配置中潜在的低权后备)。
在设置集群之前,最好先检查网络是否适合该目的。为了确保集群网络上的节点可以相互连接,您可以使用 ping 工具测试它们之间的连通性。
如果已启用 Proxmox VE 防火墙,将会自动为 corosync 生成 ACCEPT 规则 - 无需手动操作。
|
|
Corosync 在 3.0 版本之前使用多播(在 Proxmox VE 6.0 中引入)。新的版本依赖 Kronosnet 进行集群通信,目前仅支持常规的 UDP 单播。 |
|
|
您仍然可以通过在 corosync.conf 中将传输设置为 udp 或 udpu 来启用多播或传统单播,但是请记住,这将禁用所有加密和冗余支持,因此不推荐这样做。 |
当创建未带任何参数的集群时,corosync 集群通常与 Web 界面和 VM 共享同一个网络。根据您的设置,甚至存储的流量也可能通过同一个网络发送。建议进行更改,毕竟 corosync 是一个注重时效性的实时应用程序。
首先,您必须设置一个新的网络接口。它应该是物理上的单独网络。确保您的网络满足 集群网络需求。
这可以通过用于创建新集群的命令 pvecm create 的 linkX 参数实现。
如果您已经为附加的 NIC 设置了静态地址 10.10.10.1/25 ,并希望通过该接口发送和接收所有集群通信,您将执行:
pvecm create test --link0 10.10.10.1
要检查一切是否正常,请执行:
systemctl status corosync
之后,按上述步骤 添加具有分离集群网络的节点 。
如果您已经创建了一个集群并希望将其通信切换到另一个网络,您可以这样做,而无需重建整个集群,但是,这一变化可能会导致集群中的仲裁(quorum) 出现短时间的丢失,因为节点必须重启 corosync 并在新的网络上一个接一个地出现。
首先检查如何 编辑 corosync.conf 文件 。然后打开它,您应该会看到以下类似的内容:
logging {
debug: off
to_syslog: yes
}
nodelist {
node {
name: due
nodeid: 2
quorum_votes: 1
ring0_addr: due
}
node {
name: tre
nodeid: 3
quorum_votes: 1
ring0_addr: tre
}
node {
name: uno
nodeid: 1
quorum_votes: 1
ring0_addr: uno
}
}
quorum {
provider: corosync_votequorum
}
totem {
cluster_name: testcluster
config_version: 3
ip_version: ipv4-6
secauth: on
version: 2
interface {
linknumber: 0
}
}|
|
ringX_addr 实际上指定了一个 corosync 的 链路地址 。“ring”这个名字是为了与旧版的 corosync 保持向后兼容而遗留的。 |
如果您未看到它们,那您要做的第一件事情是在节点条目中添加 name(名字)属性。这些 必须 与节点的名称匹配。
然后,使用新的地址替换所有节点的 ring0_addr 属性的所有地址。您可以在此处直接使用 IP 地址或主机名。如果您使用主机名,确保它们可以从所有节点被解析(另请参阅 链路地址类型)。
在这个范例中,我们想将集群通信切换到 10.10.10.1/25 网络,所以我们分别更改了每个节点的 ring0_addr 。
|
|
完全相同的过程也可用于更改其它 ringX_addr 值。但是,我们建议一次只更改一个链路地址,以便在出现问题时更容易恢复。 |
在我们增加 config_version 属性后,新的配置文件应该如下所示:
logging {
debug: off
to_syslog: yes
}
nodelist {
node {
name: due
nodeid: 2
quorum_votes: 1
ring0_addr: 10.10.10.2
}
node {
name: tre
nodeid: 3
quorum_votes: 1
ring0_addr: 10.10.10.3
}
node {
name: uno
nodeid: 1
quorum_votes: 1
ring0_addr: 10.10.10.1
}
}
quorum {
provider: corosync_votequorum
}
totem {
cluster_name: testcluster
config_version: 4
ip_version: ipv4-6
secauth: on
version: 2
interface {
linknumber: 0
}
}然后,在最后检查所有更改的信息是否正确后,我们将其保存并再次按照 编辑 corosync.conf 文件 章节的操作使其生效。
更改将立即生效,因此重新启动 corosync 并不是有绝对的必要。如果您还更改了其他设置,或者注意到 corosync 出现问题,您可以选择触发重新启动。
在单个节点上执行:
systemctl restart corosync
现在检查是否一切正常:
systemctl status corosync
如果 corosync 再次开始工作,也请在所有其他节点上重新启动它。然后它们将在新网络上作为成员逐个加入集群。
Corosync 链路地址(使用 ringX_addr 在 corosync.conf 文件中作为向后兼容的标志)可以通过两种方式指定:
IPv4/v6 地址 可以直接使用。推荐使用它们,因为它们是静态且通常不会随意更改。
主机名 将使用 getaddrinfo 进行解析,这意味着在默认情况下,如果可用,将首先使用 IPv6 地址(另请参阅 man gai.conf)。请记住这一点,尤其是在将现有集群升级到 IPv6 时。
|
|
应该谨慎使用主机名,因为它们解析的地址可以在不接触 corosync 或其运行的节点的情况下进行更改——在未考虑对 corosync 产生影响的情况下,地址的更改可能会导致状况。 |
如果首选使用主机名,推荐为 corosync 使用单独的、专用的静态主机名。此外,请确保集群中的每个节点都可以正确的解析所有主机名。
从 Proxmox VE 5.1 开始才支持,主机名将在加入时进行解析。只有解析的 IP 才会保存到配置中。
在早期版本中,加入集群的节点可能仍使用 corosync.conf 中未解析的主机名。如上所述,用 IP 或单独的主机名替换它们是个不错的主意。
在默认情况下,Corosync 通过其集成的 Kronosnet 层支持冗余网络(它不支持在传统的 udp/udpu 上传输)。它可以通过指定多个链接地址来启用,或者通过 pvecm 的 --linkX 参数,然后在 GUI 中作为 Link 1(在创建集群或添加新节点时),又或者通过在 corosync.conf 中指定多个 ringX_addr。
|
|
为了提供有用的故障转移,每个链接都应该在自己的物理网络连接上。 |
根据优先级设置使用链路。您可以在 corosync.conf 的相应接口部分中,通过设置 knet_link_priority 来配置此优先级,或者最好在使用 pvecm 创建集群时使用优先级参数:
# pvecm create CLUSTERNAME --link0 10.10.10.1,priority=15 --link1 10.20.20.1,priority=20
这将会优先使用 link1 ,因为它具有更高的优先级(priority=20)。
如果未手动配置优先级(或两条链路具有相同优先级),则按照链路编号的顺序使用,编号越小的优先级越高。
即使所有链路都在工作,只有具有最高优先级的链接才能看到 corosync 的数据流量。链接优先级不能混淆,这意味着具有不同优先级的链路将无法相互通信。
由于低优先级的链路无法看到数据流量,除非所有高优先级的都发生故障,一种有用的规划是将用于其他任务( VM 、存储等)的网络指定为低优先级链路。如果发生最坏的情况,更高的延迟或更拥挤的连接可能好过完全没有连接。
要向正在运行的配置添加新的链接,请首先查看如何 编辑 corosync.conf 文件。
然后,在 nodelist 部分中的每个节点添加一个新的 ringX_addr。确保您的 X 与添加到的每个节点都相同,并且对于每个节点都是唯一的。
最后,添加一个新的 interface 到 totem 部分,如下所示,使用上面选择的链接编号替换 X 。
假设您添加了一个编号为 1 的链接,新的配置文件可能如下所示:
logging {
debug: off
to_syslog: yes
}
nodelist {
node {
name: due
nodeid: 2
quorum_votes: 1
ring0_addr: 10.10.10.2
ring1_addr: 10.20.20.2
}
node {
name: tre
nodeid: 3
quorum_votes: 1
ring0_addr: 10.10.10.3
ring1_addr: 10.20.20.3
}
node {
name: uno
nodeid: 1
quorum_votes: 1
ring0_addr: 10.10.10.1
ring1_addr: 10.20.20.1
}
}
quorum {
provider: corosync_votequorum
}
totem {
cluster_name: testcluster
config_version: 4
ip_version: ipv4-6
secauth: on
version: 2
interface {
linknumber: 0
}
interface {
linknumber: 1
}
}只要您按照最后的步骤 编辑 corosync.conf 文件,就会启用新的链接,而无需重启。您可以使用以下方式检查 corosync 是否加载了新的链接:
journalctl -b -u corosync
有一个不错的测试新链接的办法,就是通过临时断开一个节点上的旧链接并确保其状态在断开连接时能保持在线:
pvecm status
如果您看到健康的集群状态,则意味着正在使用您的新链接。
Proxmox VE 利用 SSH 隧道实现各种功能。
代理控制台/控制台会话(节点和来宾)
当连接到节点 A 的同时为节点 B 使用控制台时,会连接到节点 A 上的终端代理,而终端代理又通过非交互式的 SSH 隧道连接并登录控制台到节点 B 上。
使用 安全 模式迁移 VM 与 CT 的内存和本地存储。
在迁移过程中,源节点和目标节点之间会建立一个或多个 SSH 隧道,以便交换迁移信息并传输内存和磁盘内容。
存储复制
|
|
自动执行 .bashrc 和类似文件的缺陷
如果您有自定义的 .bashrc 或类似的文件,这些文件配置为控制台登录时执行,ssh 将会在成功建立会话时自动运行一次。这可能会导致一些意外行为,因为这些命令可能会以 root 权限执行以上任何操作。这问题可能会造成负面效应! 为了避免这种复杂情况,建议在 /root/.bashrc 中添加检查以确保会话是交互式的,然后才能运行 .bashrc 命令。 您可以在 .bashrc 文件的开头添加此代码段: # Early exit if not running interactively to avoid side-effects!
case $- in
*i*) ;;
*) return;;
esac |
本节描述了一种在 Proxmox VE 集群中部署外部投票器的方法。配置之后,集群可以承受更多的节点故障,而不会违反集群通信的安全属性。
为此,需要两个服务参与:
在每个 Proxmox VE 节点上运行一个 QDevice 守护进程。
在独立服务器上运行的外部投票守护进程
因此,即使在小型的设置中(例如 2+1 个节点),也可以实现更高的可用性。
Corosync 仲裁设备(Quorum Device,简称 QDevice)是一个运行在每个集群节点上的守护进程。它根据外部运行的第三方仲裁员的决定,为集群的仲裁子系统提供一个配置的投票数。它的主要用途是允许集群可以承受比标准仲裁规则允许的更多的节点故障。由于外部设备可以看到所有节点,因此只要选择一组节点就可以安全地完成投票。只有在收到第三方投票后,所述节点群(再次)达到规定数量时,才会这样做。
目前,仅支持 QDevice Net 作为第三方仲裁者。这是一个守护进程,它为集群分区提供投票权,前提是它可以通过网络到达分区的成员。它在任何时候都只会给集群的一个分区投票。它旨在支持多个集群并且几乎无需配置和无状态的。新的集群是动态处理的,在运行 QDevice 的主机上不需要配置文件。
对于外部主机的唯一要求是它需要通过网络访问到集群,并拥有可用的 corosync-qnetd 软件包。我们为基于 Debian 的主机提供了一个软件包,其他 Linux 发行版也应该拥有通过它们各自的包管理器提供的软件包。
|
|
与 corosync 本身不同,QDevice 通过 TCP/IP 连接到集群。守护进程甚至可能在集群的 LAN 之外运行,并且可能具有超过 2 毫秒的延迟。 |
我们支持将 QDevice 用于节点数为偶数的集群,如果推荐将它用于 2 个节点的集群,它们应该会提供更高的可用性。目前我们不鼓励将 QDevice 用于节点数为奇数的集群,其原因是 QDevice 为每种类型的集群提供不相同的投票数。偶数集群会获得单一的附加票,这只会增加可用性,因为如果 QDevice 自身出现故障,您的处境等同于完全没有 Device 。
另一方面,对于奇数大小的集群,QDevice 提供 (N-1) 票数 — 其中 N 对应于集群的节点数量。这是种合理的替代行为;如果它只有一个附加票,集群可能会陷入分裂的局面。该算法允许除一个节点(当然还有 QDevice 自身)之外的所有节点发生故障。但是,这样做有两个缺点:
如果 QNet 守护进程自身发生故障,则其他节点可能不会发生故障或集群将立即失败仲裁。例如,在有 15 个节点的集群中,可能有 7 个节点在集群的规定数量不达标之前就已经发生故障。但是,如果在这里配置了 QDevice 并且它自身出现故障,则 15 个节点中可能没有一个节点会发生故障。在这种情况下,QDevice 几乎充当了单点故障。
事实上一开始,除了一个节点和 QDevice 之外的所有节点都可能出现故障,这听起来很有希望,但这可能会导致 HA 服务的大量恢复,它可能会导致剩余的单个节点过载。此外,如果只有 ((N-1)/2) 个或更少的节点保持在线状态,Ceph 服务器将停止提供服务。
如果您了解这些缺点和影响,您可以自行决定是否要在奇数的集群设置中使用此技术。
我们建议以非特权用户身份运行任何为 corosync-qdevice 提供投票权的守护进程。Proxmox VE 和 Debian 提供了一个已完成此类配置的软件包。守护进程和集群之间的数据流量必须加密,以确保 QDevice 安全的集成到 Proxmox VE。
首先,在您的外部服务器上安装 corosync-qnetd 软件包
external# apt install corosync-qnetd
并在所有集群节点上安装 corosync-qdevice 软件包
pve# apt install corosync-qdevice
执行此操作后,确保集群中的所有节点都在线。
您现在可以通过在 Proxmox VE 节点之一上运行以下命令来设置 QDevice:
pve# pvecm qdevice setup <QDEVICE-IP>
集群中的 SSH 密钥将自动复制到 QDevice 。
|
|
如果在此步骤中要求您输入密码,请确保外部服务器上的 SSH 配置允许 root 通过密码登录。 |
输入密码并成功完成所有步骤以后,您将会看到 “Done”(完成)。您可以使用以下命令验证 QDevice 是否已经设置:
pve# pvecm status
...
Votequorum information
~~~~~~~~~~~~~~~~~~~~~
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate Qdevice
Membership information
~~~~~~~~~~~~~~~~~~~~~~
Nodeid Votes Qdevice Name
0x00000001 1 A,V,NMW 192.168.22.180 (local)
0x00000002 1 A,V,NMW 192.168.22.181
0x00000000 1 Qdevice在平局的情况下,两个相同大小的集群分区无法相互看到,但都可以看到 QDevice,QDevice 会随机选择其中一个分区并将选票投给它。
对于节点数为偶数的集群,使用 QDevice 时没有负面影响,如果它无法正常工作,相当于完全没有 QDevice 。
如果要在具有 QDevice 设置的集群中添加新节点或删除现有节点,需要先删除 QDevice 。之后,您可以正常的添加或删除节点。一旦您再次拥有一个偶数节点数的集群,您就可以如前所述重新设置 QDevice 。
如果您使用官方的 pvecm 工具添加 QDevice,则可以运行以下命令将其删除:
pve# pvecm qdevice remove
文件 /etc/pve/corosync.conf 在 Proxmox VE 集群中扮演着核心角色。它控制集群成员及其网络。有关它的更多信息,请查看 corosync.conf 手册页:
man corosync.conf对于节点成员,您应该始终使用 Proxmox VE 提供的 pvecm 工具。您可能需要手动编辑配置文件以进行其他更改。以下是执行此操作的一些最佳实践技巧。
编辑 corosync.conf 文件并不总是很简单。每个集群节点上有两个,一个是 /etc/pve/corosync.conf ,另一个是 /etc/corosync/corosync.conf 。编辑我们的集群文件系统中的这个文件,会将改动传播到本地的另一个,但反之则不然。
一旦文件更改,配置将自动更新。这意味着集成到正在运行的 corosync 中的改动将立即生效。因此,您应该始终为该文件创建一个复本后再编辑,以避免在保存编辑中的文件时触发意外的改动。
cp /etc/pve/corosync.conf /etc/pve/corosync.conf.new
然后,使用您最喜欢的编辑器打开配置文件,例如 nano 或者 vim.tiny ,它们预装在每个 Proxmox VE 节点上。
|
|
配置更改后应始终增加 config_version 的编号;忽略这点将会导致问题。 |
进行必要的更改后,创建当前工作中的配置文件的另一个副本。这是作为在新的配置故障无法应用或造成其他问题时的备份。
cp /etc/pve/corosync.conf /etc/pve/corosync.conf.bak
然后使用新的配置文件替换旧的配置文件:
mv /etc/pve/corosync.conf.new /etc/pve/corosync.conf
您可以使用以下命令检查更改是否可以自动应用:
systemctl status corosync journalctl -b -u corosync
如果更改未能自动应用,您可以通过以下命令重启 corosync 服务:
systemctl restart corosync
关于错误,请查看下面的故障排除部分。
当 corosync 启动失败时,您可以在系统日志中收到以下消息:
[...]
corosync[1647]: [QUORUM] Quorum provider: corosync_votequorum failed to initialize.
corosync[1647]: [SERV ] Service engine 'corosync_quorum' failed to load for reason
'configuration error: nodelist or quorum.expected_votes must be configured!'
[...]
这意味着您在配置中用于 corosync 的 ringX_addr 设定的主机名无法被解析。
如果您需要在没有仲裁的节点上更改 /etc/pve/corosync.conf 文件,并且您了解自己在做什么,请使用:
pvecm expected 1这会将预期的投票计数设置为 1,并使集群达到规定数量。然后您可以修复您的配置,或者将其恢复到上次工作备份。
如果 corosync 再也无法启动,这是不够的,在这种情况下,最好编辑 corosync 的配置文件 /etc/corosync/corosync.conf 的本地副本,以便 corosync 可以再次启动。确保在所有节点上,此配置具有相同的内容,以避免出现分裂的局面。
这是节点之间的 Kronosnet 连接的不同链接地址的名称
很明显,当所有节点都离线时,一个集群无法达到规定数量。这在断电后的常见情况。
|
|
使用一个不间断电源(“UPS”,也称为“备用电池”)来避免这种状态始终是一个好主意,尤其是在您需要 HA 的情况下。 |
在节点启动时,pve-guests 服务启动并等待仲裁。一旦达到规定数量,它会启动带有 onboot 标志的所有来宾。
当您开启节点,或者断电后恢复供电时,某些节点可能会比其他节点启动得更快。
将虚拟来宾迁移到其他节点是集群中一项很有用的功能。有一些设置可以控制此类迁移的行为。这可以通过配置文件 datacenter.cfg 或者通过 API 或命令行参数进行特定的迁移来完成。
如果来宾在线或离线,或者它具有本地资源(如本地磁盘),情况会有所不同。
有关虚拟机迁移的详细信息,请参阅 QEMU/KVM 迁移章节 。
有关容器迁移的详细信息,请参阅 容器迁移章节 。
迁移的类型定义了迁移数据是应该通过一个已加密(安全)通道还是一个未加密(不安全)通道进行发送。设置为不安全的迁移类型意味着虚拟来宾的内存内容也会以未加密的方式传输,这可能导致来自来宾内部的关键数据(例如,密码或者加密的密钥)发生信息泄露。
因此,如果您未能完全控制网络并且不能保证没有人窃取,我们强烈建议使用安全隧道。
|
|
存储迁移不遵循此设置。目前,它始终通过安全通道发送存储内容。 |
加密需要大量的计算能力,因此经常将此设置更改为“不安全”以实现更好的性能。对现代系统的影响较小,因为它们在硬件中实现了 AES 加密。在可以传输 10Gbps 或更高的快速网络中,性能影响尤为明显。
默认情况下,Proxmox VE 使用进行集群通信的网络来发送迁移流量。这不是最优的,因为敏感的集群通信流量可能会中断,并且该网络可能不具有节点上可用的最佳带宽。
设置迁移网络参数允许对所有迁移流量使用专用的网络。除了内存,这也会影响离线迁移的存储流量。
迁移网络设置为使用 CIDR 表示法的网络。这样做的好处是您不必为每个节点设置单独的 IP 地址。Proxmox VE 可以从 CIDR 类型中所指定的网络里确定目标节点上的真实地址。要启用此功能,必须指定网络,以便每个节点在各自的网络中只有一个 IP 。
我们假设我们有一个三节点设置,具有三个独立的网络。一个用于与 Internet 的公共通信,一个用于集群通信,还有一个非常快,我们希望将其用作迁移的专用网络。
这样设置的网络配置可能如下所示:
iface eno1 inet manual
# public network
auto vmbr0
iface vmbr0 inet static
address 192.X.Y.57/24
gateway 192.X.Y.1
bridge-ports eno1
bridge-stp off
bridge-fd 0
# cluster network
auto eno2
iface eno2 inet static
address 10.1.1.1/24
# fast network
auto eno3
iface eno3 inet static
address 10.1.2.1/24在此,我们将使用网络 10.1.2.0/24 作为迁移网络。对于单个迁移,您可以在以下命令行工具中使用 migration_network 参数来执行此操作:
# qm migrate 106 tre --online --migration_network 10.1.2.0/24
要将其配置为集群中所有迁移的默认网络,请设置 /etc/pve/datacenter.cfg 文件的 migration 属性:
# use dedicated migration network migration: secure,network=10.1.2.0/24
|
|
在 /etc/pve/datacenter.cfg 中设置迁移网络时,必须始终设置迁移类型。 |
Proxmox 集群文件系统(“pmxcfs”)是一个数据库驱动的文件系统,用于存储配置文件,并使用 corosync 实时复制到所有集群节点。我们用它存储所有 PVE 相关的配置文件。
尽管文件系统存储将所有数据在磁盘上的持久数据库中,但数据的副本驻留在内存中。当前对最大容量(当前为 30 MB)采取了限制,这仍然足以存储数千个虚拟机的配置。
该系统具有以下优点:
将所有配置实时无缝复制到所有节点
提供强一致性检查以避免重复的 VM ID
当节点失去仲裁(quorum)时只读
Corosync 自动更新集群配置到所有节点
包括分布式锁定机制
文件系统基于 FUSE ,因此其行为类似于 POSIX 。但是部分功能根本没有实现,因为我们不需要它们:
您可以只生成普通文件和目录,但不能生成符号链接等…
您不能重命名非空目录(因为这样可以更轻松地保证 VMID 是唯一的)。
您无法更改文件权限(权限基于路径)
O_EXCL 创建不是原子的(就像旧的 NFS)
O_TRUNC 创建不是原子的(FUSE 限制)
所有文件和目录都归用户 root 所有,并拥有 www-data 组。仅 root 用户拥有写入权限,但是 www-data 组可以读取大多数文件。下列路径下的文件只能由 root 用户访问:
/etc/pve/priv/
/etc/pve/nodes/${NAME}/priv/我们使用 Corosync Cluster Engine(集群引擎)进行集群通信,数据库文件使用 SQlite 。文件系统是使用 FUSE 在用户空间中实现的。
该文件系统挂载到:
/etc/pve
authkey.pub |
凭证系统使用的公钥 |
ceph.conf |
Ceph 配置文件(注意:/etc/ceph/ceph.conf 是指向该文件的符号链接) |
corosync.conf |
Corosync 集群配置文件(在 Proxmox VE 4.x 之前,此文件被称为 cluster.conf) |
datacenter.cfg |
Proxmox VE 数据中心范围的配置(键盘布局、代理等) |
domains.cfg |
Proxmox VE 身份验证域 |
firewall/cluster.fw |
应用于所有节点的防火墙配置 |
firewall/<NAME>.fw |
用于单个节点的防火墙配置 |
firewall/<VMID>.fw |
VM 和容器的防火墙配置 |
ha/crm_commands |
显示 CRM 当前正在执行的 HA 操作。 |
ha/manager_status |
关于集群上 HA 服务的 JSON 格式信息 |
ha/resources.cfg |
由高可用性管理的资源及其当前状态 |
nodes/<NAME>/config |
特定于节点的配置 |
nodes/<NAME>/lxc/<VMID>.conf |
用于 LXC 容器的 VM 配置数据 |
nodes/<NAME>/openvz/ |
在 PVE 4.0 之前,用于容器配置数据(已弃用,即将删除) |
nodes/<NAME>/pve-ssl.key |
对应 pve-ssl.pem 的私有 SSL 密钥 |
nodes/<NAME>/pve-ssl.pem |
用于 Web 服务器的公共 SSL 证书(由集群 CA 签名) |
nodes/<NAME>/pveproxy-ssl.key |
对应 pveproxy-ssl.pem 的私有 SSL 密钥(可选) |
nodes/<NAME>/pveproxy-ssl.pem |
用于 Web 服务器的公共 SSL 证书(链)(pve-ssl.pem 的可选覆盖) |
nodes/<NAME>/qemu-server/<VMID>.conf |
用于 KVM VM 的 VM 配置数据 |
priv/authkey.key |
凭证系统使用的私钥 |
priv/authorized_keys |
用于集群成员身份验证的 SSH 密钥 |
priv/ceph* |
Ceph 身份验证密钥和相关功能 |
priv/known_hosts |
用于集群成员的验证的 SSH 密钥 |
priv/lock/* |
锁定各种服务使用的文件,以确保集群范围内的操作安全 |
priv/pve-root-ca.key |
集群 CA 的私钥 |
priv/shadow.cfg |
用于 PVE 领域用户的 Shadow 密码文件 |
priv/storage/<STORAGE-ID>.pw |
包含明文存储的密码 |
priv/tfa.cfg |
Base64 编码的二次验证配置 |
priv/token.cfg |
所有令牌的 API 令牌机密 |
pve-root-ca.pem |
集群 CA 的公共证书 |
pve-www.key |
用于生成 CSRF 令牌的私钥 |
sdn/* |
软件定义网络(SDN)的共享配置文件 |
status.cfg |
Proxmox VE 外部度量服务器配置 |
storage.cfg |
Proxmox VE 存储配置 |
user.cfg |
Proxmox VE 访问控制配置(用户、组、其他) |
virtual-guest/cpu-models.conf |
用于存储自定义 CPU 型号 |
vzdump.cron |
集群范围的 vzdump 备份任务计划 |
集群文件系统中的某些目录使用符号链接,以指向节点自身的配置文件。因此,下表中指向的文件是指集群每个节点上的不同文件。
local |
nodes/<LOCAL_HOST_NAME> |
lxc |
nodes/<LOCAL_HOST_NAME>/lxc/ |
openvz |
nodes/<LOCAL_HOST_NAME>/openvz/(已弃用,即将删除) |
qemu-server |
nodes/<LOCAL_HOST_NAME>/qemu-server/ |
.version |
文件版本(用于检测文件修改) |
.members |
有关集群成员的信息 |
.vmlist |
所有 VM 列表 |
.clusterlog |
集群日志(最后 50 个条目) |
.rrd |
RRD 数据(最近的条目) |
您可以通过以下方式启用详细的系统日志消息:
echo "1" >/etc/pve/.debug
并通过以下方式禁用详细的系统日志消息:
echo "0" >/etc/pve/.debug
如果您的 Proxmox VE 主机存在重大问题,例如硬件问题,复制 pmxcfs 数据库文件 /var/lib/pve-cluster/config.db ,并将其移动到新的 Proxmox VE 主机可能会有所帮助。在新的主机上(没有任何运行),您需要停止 pve-cluster 服务和替换 config.db 文件(需要权限 0600)。在此之后,根据丢失的 Proxmox VE 主机调整 /etc/hostname 和 /etc/hosts ,然后重新启动并检查(不要忘记您的 VM 和 CT 的数据)。
推荐的方法是在从集群中删除节点后重新安装节点。这确保所有集群的机密和 SSH 的密钥、以及任何共享配置数据都被销毁。
在某些情况下,您可以更喜欢在不重装的情况下将节点恢复到本地模式,这在无需重装分离节点中进行了描述。
对于 nodes/<NAME>/qemu-server/( VM )和 nodes/<NAME>/lxc/(容器)中的来宾配置文件,Proxmox VE 视包含 <NAME> 的节点为相应来宾的所有者。这个概念允许使用本地锁而不是昂贵的集群范围的锁,以此来防止来宾配置的并发更改。
因此,如果拥有来宾的节点发生故障(例如,由于断电、隔离事件等),则无法进行常规迁移(即使所有磁盘都位于共享存储上),因为这样无法在拥有的节点(离线)上的本地锁。这对于 HA 管理的来宾不是问题,因为 Proxmox VE 的高可用性堆栈(stack)包括必要的(cluster-wide) 锁定和监控功能(watchdog),以确保可以正确且自动的从隔离的节点恢复来宾。
如果非 HA 管理的来宾只有共享磁盘(并且没有其他仅在故障节点上可用的本地资源),一种简单的手动恢复方式,是将故障节点的目录 /etc/pve/ 里的来宾配置文件移动到在线节点的目录(这会更改来宾的逻辑所有者或位置)。
例如,将 ID 为 100 的 VM 从离线的节点 node1 恢复到另一个节点 node2 的工作方式是在集群的任何成员节点上以 root 身份运行以下命令:
mv /etc/pve/nodes/node1/qemu-server/100.conf /etc/pve/nodes/node2/
|
|
在像这样手动恢复来宾之前,请绝对确保发生故障的源节点确实已关闭/隔离。否则,Proxmox VE 的锁定原则会被 mv 命令违反,这可能会产生无法预料的后果。 |
|
|
具有本地磁盘(或仅在离线节点上可用的其他本地资源)的来宾无法像这样的恢复。要么等待故障节点重新加入集群,要么从备份中恢复这些来宾。 |
Proxmox VE 存储模型非常灵活。虚拟机映像可以存储在一个或多个本地存储上,也可以存储在 NFS 或 iSCSI(NAS、SAN)等共享存储上。没有任何限制,您可以根据需要配置任意数量的存储池。您可以使用可用于 Debian Linux 的所有存储技术。
将 VM 存储在共享存储上的一个主要好处是能够在不停机的情况下实时迁移正在运行的机器,因为集群中的所有节点都可以直接访问 VM 的磁盘映像。无需复制 VM 映像数据,在这种情况下的实时迁移会非常快。
存储库(软件包 libpve-storage-perl)使用灵活的插件系统为所有存储类型提供了一个通用接口。这在将来可以很容易地采用并包含更多的存储类型。
基本上有两种不同的存储类型:
基于文件级别的存储技术允许访问到全功能(POSIX)的文件系统。它们通常比任何块级存储(见下文)更灵活,并允许您存储任何类型的内容。ZFS 可能是最先进的系统,它完全支持快照和克隆。
允许存储大型的 raw 映像,通常不可能在此类存储类型上存储其他文件(ISO、备份文件等)。大多数现代的块级存储实现都支持快照和克隆。RADOS 和 GlusterFS 是分布式系统,将存储的数据复制到不同节点。
| 描述 | PVE 类型 | 存储级别 | 是否共享 | 是否快照 | 是否稳定 |
|---|---|---|---|---|---|
ZFS (local) |
zfspool |
文件 |
否 |
是 |
是 |
Directory |
dir |
文件 |
否 |
否1 |
是 |
BTRFS |
btrfs |
文件 |
否 |
是 |
技术预览 |
NFS |
nfs |
文件 |
是 |
否1 |
是 |
CIFS |
cifs |
文件 |
是 |
否1 |
是 |
Proxmox Backup |
pbs |
两者均有 |
是 |
n/a |
是 |
GlusterFS |
glusterfs |
文件 |
是 |
否1 |
是 |
CephFS |
cephfs |
文件 |
是 |
是 |
是 |
LVM |
lvm |
块 |
否2 |
否 |
是 |
LVM-thin |
lvmthin |
块 |
否 |
是 |
是 |
iSCSI/kernel |
iscsi |
块 |
是 |
否 |
是 |
iSCSI/libiscsi |
iscsidirect |
块 |
是 |
否 |
是 |
Ceph/RBD |
rbd |
块 |
是 |
是 |
是 |
ZFS over iSCSI |
zfs |
块 |
是 |
是 |
是 |
1:在基于文件的存储上,快照可以使用 qcow2 格式。
2:可以在 iSCSI 或 基于 FC 的存储之上使用 LVM。这样您就可以获得 共享 的 LVM 存储。
许多存储和 qcow2 格式的 Qemu 映像,支持 自动精简配置 。当激活自动精简配置后,只有来宾系统实际用的块才会写入存储。
举个实例说明,您创建一个 32GB 硬盘的 VM ,然后安装了来宾系统的操作系统,VM 的 root 文件系统则包含了 3GB 的数据。在这种情况下,即使您的来宾 VM 看到有一个 32GB 的硬盘,也仅有 3GB 写入到存储。通过这种方式,自动精简配置允许您创建大于当前可用存储块的磁盘映像。您可以为您的 VM 创建大型的磁盘映像,并在需要时向存储添加更多磁盘,而无需调整 VM 文件系统的大小。
所有具有“快照”功能的存储类型也支持自动精简配置。
|
|
如果存储已满,则使用该存储上的卷的所有来宾都会收到 IO 错误。这会导致文件系统不一致且可能导致您的数据损坏。因此,建议避免超额配置(over-provisioning)您的存储资源,或者仔细观察可用空间以避免出现此类情况。 |
所有与 Proxmox VE 相关的存储配置都储存在单文本文件 /etc/pve/storage.cfg 中。由于此文件位于 /etc/pve/ ,它会自动分发到所有集群节点,因此所有节点共享相同的存储配置。
共享存储配置对于共享存储非常有意义,因为所有节点都可以访问相同的“共享”存储。但它对本地存储类型也很有用,在这种情况下,可以在所有节点上使用这样的本地存储。但它在物理上是不同的,并且可以具有完全不同的内容。
每个存储池都有一个<类型> ,并通过 <STORAGE_ID> 进行唯一标识。一个池的配置如下所示:
<type>: <STORAGE_ID>
<property> <value>
<property> <value>
<property>
...从 <type>: <STORAGE_ID> 行开始定义池,紧随其后的是属性列表。大多数属性需要一个值。有些具有合理的默认值,在这种情况下您可以省略该值。
更具体地说,查看安装后的默认存储配置。它包括一个名为 local 的特殊本地存储池,它指向 /var/lib/vz 目录,并且始终可用。Proxmox VE 安装程序根据在安装时选择的存储类型来创建附加的存储条目。
dir: local
path /var/lib/vz
content iso,vztmpl,backup
# default image store on LVM based installation
lvmthin: local-lvm
thinpool data
vgname pve
content rootdir,images
# default image store on ZFS based installation
zfspool: local-zfs
pool rpool/data
sparse
content images,rootdir部分存储属性在不同类型的存储中是通用的。
此存储可用或可访问的集群节点名称列表。可以使用此属性来限制对一组受限节点的存储访问。
一个存储可以支持多种类型的内容,例如虚拟磁盘映像、ISO 光盘映像、容器模板或容器 root 目录。并非所有类型的存储支持所有类型的内容。可以设置此属性用以选择此存储的用途。
KVM-Qemu VM 映像。
允许存储容器数据。
容器模板。
备份文件(vzdump)
。ISO 光盘映像。
片段文件,例如来宾的挂钩脚本。
将存储标记为共享。
您可以使用此标志完全禁用存储。
已弃用,请使用 prune-backups 替代。每个 VM 的最大备份文件数。使用 0 表现无限制。
备份的保留选项。有关详细信息,请查阅 备份保留 。
映像的默认格式(raw|qcow2|vmdk)。
|
|
不建议在不同的 Proxmox VE 集群上使用相同的存储池。部分存储操作需要独占方式访问存储,因此需要适当的锁定。虽然这是集群内实现的,但是它无法在不同集群之间起作用。 |
我们使用特殊的符号来表示存储数据。当您从存储池分配数据时,它返回这样的一个卷标识符。通过 <STORAGE_ID> 来标识的卷,紧随其后的是与卷名相关的存储类型,使用冒号分隔。有效的 <VOLUME_ID> 如下所示:
local:230/example-image.raw
local:iso/debian-501-amd64-netinst.iso
local:vztmpl/debian-5.0-joomla_1.5.9-1_i386.tar.gz
iscsi-storage:0.0.2.scsi-14f504e46494c4500494b5042546d2d646744372d31616d61
要获取 <VOLUME_ID> 的文件系统路径,请使用:
pvesm path <VOLUME_ID>
映像(image) 类型的卷存在所有权关系。每个 VM 或容器都拥有这样的卷。例如,卷 local:230/example-image.raw 是归 VM 230 所有。大多数存储后端将此所有权信息编码到卷的名称中。
当您销毁 VM 或容器时,系统也会销毁该 VM 或容器拥有的所有关联的卷。
建议您熟悉存储池和卷的标识符背后的概念,但在现实中,不会强制您在命令行上执行这些低级操作。通常,卷的分配和删除均由 VM 和容器管理工具完成。
尽管如此,还是有一个名为 pvesm(“Proxmox VE Storage Manager”,即 Proxmox VE 存储管理器的缩写)的命令行工具,它能够执行常见的存储管理任务。
添加存储池
pvesm add <TYPE> <STORAGE_ID> <OPTIONS> pvesm add dir <STORAGE_ID> --path <PATH> pvesm add nfs <STORAGE_ID> --path <PATH> --server <SERVER> --export <EXPORT> pvesm add lvm <STORAGE_ID> --vgname <VGNAME> pvesm add iscsi <STORAGE_ID> --portal <HOST[:PORT]> --target <TARGET>
禁用存储池
pvesm set <STORAGE_ID> --disable 1
启用存储池
pvesm set <STORAGE_ID> --disable 0
更改或设置存储选项
pvesm set <STORAGE_ID> <OPTIONS> pvesm set <STORAGE_ID> --shared 1 pvesm set local --format qcow2 pvesm set <STORAGE_ID> --content iso
移除存储池。这不会删除任何数据,也不会断开连接或卸载任何东西。它只是移除该存储配置。
pvesm remove <STORAGE_ID>
分配卷
pvesm alloc <STORAGE_ID> <VMID> <name> <size> [--format <raw|qcow2>]
在本地存储中分区一个 4G 的卷。如果您使用空字符串作为 <name>(名称),则名称将自动生成。
pvesm alloc local <VMID> '' 4G
释放卷(清空卷)
pvesm free <VOLUME_ID>
|
|
这会真正地销毁所有卷的数据。 |
列出存储状态
pvesm status
列出存储内容
pvesm list <STORAGE_ID> [--vmid <VMID>]
列出由 VMID 分配的卷
pvesm list <STORAGE_ID> --vmid <VMID>
列出 ISO 光盘映像
pvesm list <STORAGE_ID> --iso
列出容器模板
pvesm list <STORAGE_ID> --vztmpl
显示卷的文件系统路径
pvesm path <VOLUME_ID>
导出卷 local:103/vm-103-disk-0.qcow2 到文件 target 。通常与内部地 pvesm import 配合使用。流格式 qcow2+size 不同于 qcow2 格式。因此,导出的文件无法简单的附加到 VM 。这也适用于其他格式。
pvesm export local:103/vm-103-disk-0.qcow2 qcow2+size target --with-snapshots 1
存储池类型:dir
Proxmox VE 可以使用本地目录或本地挂载的共享进行存储。目录是文件级存储,因此您可以存储任何类型的内容,如虚拟磁盘映像、容器、模板、ISO 光盘映像或备份文件。
|
|
您可以通过标准 Linux 的 /etc/fstab 来挂载附加的存储,然后为该挂载点定义一个目录存储。这样您就可以使用 Linux 支持的任何文件系统。 |
该后端假设底层目录是 POSIX 兼容的,但是仅此而已。这意味着您无法在存储级别创建快照。但是对于使用 qcow2 文件格式的 VM 映像存在一种变通的方法,因为该格式在内部支持快照。
|
|
部分类型的存储不支持 O_DIRECT ,因此您无法对这些存储使用 none 缓存模式。只需使用 writeback 缓存模式代替。 |
我们使用预定义的目录布局,将不同类型的内容存储到不同的子目录中。所有文件级存储后端都使用此布局。
| 内容类型 | 子目录 |
|---|---|
VM 映像 |
images/<VMID>/ |
ISO 光盘映像 |
template/iso/ |
容器模板 |
template/cache/ |
备份文件 |
dump/ |
片段(Snippets)文件 |
snippets/ |
该后端支持所有常见的存储属性,并添加一个名为 path 的附加属性来指定目录。这需要文件系统的绝对路径。
dir: backup
path /mnt/backup
content backup
maxfiles 7以上配置定义了一个名为 backup 的存储池。该池可用于为每个 VM 存储最多 7 个备份(maxfiles 7)。备份文件的实际路径是 /mnt/backup/dump/... 。
该后端为 VM 映像使用定义明确的命名方案:
vm-<VMID>-<NAME>.<FORMAT>
这是指定 VM 的所有者
这可以是没有空格的任意名称(ascii)。该后端使用 disk-[N] 作为默认值,其中 [N] 使用让名字唯一的整数替换。
指定映像格式(raw|qcow2|vmdk)。
当您创建一个 VM 模板时,所有的 VM 映像都将重命名来表明它们现在是只读的,并且可以用作克隆的基础映像:
base-<VMID>-<NAME>.<FORMAT>
|
|
这些基础映像用于生成克隆的映像。因此,重要的是这些文件是只读的,且永远不会被修改。后端将访问模式更改为 0444,并在存储支持的情况下设置不可变标志(chattr +i)。 |
如上所述,大多数文件系统不支持开箱即用的快照。为了解决这个问题,此后端能够使用 qcow2 内部的快照特性。
这同样适用于克隆。后端使用 qcow2 的基础映像功能来创建克隆。
| 内容类型 | 映像格式 | 是否共享 | 快照 | 克隆 |
|---|---|---|---|---|
images rootdir vztmpl iso backup snippets | raw qcow2 vmdk subvol |
否 |
qcow2 | qcow2 |
请使用以下命令在存储 local 上分配 4 GB 的映像:
# pvesm alloc local 100 vm-100-disk10.raw 4G Formatting '/var/lib/vz/images/100/vm-100-disk10.raw', fmt=raw size=4294967296 successfully created 'local:100/vm-100-disk10.raw'
|
|
映像名称必须符合上述的命名约定。 |
实际文件系统路径显示为:
# pvesm path local:100/vm-100-disk10.raw /var/lib/vz/images/100/vm-100-disk10.raw
您可以使用以下命令移除映像:
# pvesm free local:100/vm-100-disk10.raw
存储池类型:nfs
NFS 后端是基于目录后端,因此它共享大多数属性。有相同的目录布局和文件命令约定。主要的优势是您可以直接配置 NFS 服务器属性,后端可以自动挂载共享,而无需修改 /etc/fstab 。后端还可以测试服务器是否在线,并且提供了一种向服务器查询导出共享的方法。
该后端支持所有常见的存储属性,但始终设置的共享标志除外。此外,以下属性用于配置 NFS 服务器:
服务器 IP 或 DNS 名称。要避免 DNS 查找延迟,通常最好使用 IP 地址而不是 DNS 名称——除非您有非常可选的 DNS 服务器,或在本地 /etc/hosts 文件中列出该服务器。
NFS 导出路径(由 pvesm nfsscan 列出)。
您还可以设置 NFS 挂载选项:
本地挂载点(默认指向 /mnt/pve/<STORAGE_ID>/)。
NFS 挂载选项(请参阅 man nfs)。
nfs: iso-templates
path /mnt/pve/iso-templates
server 10.0.0.10
export /space/iso-templates
options vers=3,soft
content iso,vztmpl
|
|
NFS 请求超时后,默认情况下会限制重试 NFS 请求。这可能会导致客户端意外挂起。对于只读内容,值得考虑 NFS soft 选项,这将限制重试次数为 3 次。 |
NFS 不支持快照,但此后端使用 qcow2 的特性来实现快照和克隆。
| 内容类型 | 映像格式 | 是否共享 | 快照 | 克隆 |
|---|---|---|---|---|
images rootdir vztmpl iso backup snippets |
raw qcow2 vmdk |
是 |
qcow2 |
qcow2 |
您可以通过以下方式获取导出的 NFS 共享列表:
# pvesm nfsscan <server>
存储池类型:cifs
CIFS(也叫 SMB)后端扩展了目录后端,因此无需手动设置 CIFS 挂载。这样的存储可以通过 Proxmox VE API 或 Web 界面直接添加,并具有我们所有的后端优势,例如服务器心跳检查或舒适的选择导出的共享。
该后端支持所有常见的存储属性,但始终设置的共享标志除外。此外,还有以下 CIFS 专用属性可用:
服务器 IP 或 DNS 名称。必需。
|
|
要避免 DNS 查找延迟,通常最好使用 IP 地址而不是 DNS 名称——除非您有非常可靠的 DNS 服务器,或在本地 /etc/hosts 文件中列出该服务器。 |
要使用的 CIFS 共享(通过 pvesm scan cifs <address> 或 Web 界面获取可用的共享)。必需。
用于 CIFS 存储的用户名。可选,默认为‘guest’。
用户的密码。可选。它保存在一个只能被 root 读取的文件(/etc/pve/priv/storage/<STORAGE-ID>.pw)中。
为该存储设置用户的域(工作组)。可选。
SMB 协议版本。可选,默认是 3。由于安全问题,不支持 SMB1。
本地挂载点。可选,默认指向 /mnt/pve/<STORAGE_ID>/。
cifs: backup
path /mnt/pve/backup
server 10.0.0.11
share VMData
content backup
username anna
smbversion 3
CIFS 不支持存储级别的快照。但是,如果您仍然希望可以使用快照和克隆的特性,则可以使用 qcow2 进行文件备份。
| 内容类型 | 映像格式 | 是否共享 | 快照 | 克隆 |
|---|---|---|---|---|
images rootdir vztmpl iso backup snippets |
raw qcow2 vmdk |
是 |
qcow2 |
qcow2 |
您可以通过以下方式获取导出的 CIFS 共享列表:
# pvesm scan cifs <server> [--username <username>] [--password]
然后通过以下方式,您可以将此共享作为存储添加到整个 Proxmox VE 集群:
# pvesm add cifs <storagename> --server <server> --share <share> [--username <username>] [--password]
存储池类型:pbs
该后端允许 Proxmox Backup Server(备份服务器)像任何其他存储一样直接集成到 Proxmox VE 中。Proxmox 备份存储可以通过 Proxmox VE API、CLI 或者 Web 界面直接添加。
该后端支持所有常见的存储属性,但始终设置的共享标志除外。此外,还有以下 Proxmox Backup Server 专用属性可用:
服务器 IP 或 DNS 名称。必需。
用于 Proxmox Backup Server(备份服务器)存储的用户名。必需。
|
|
不要忘记添加领域到用户名中。例如,root@pam 或者 archiver@pbs。 |
用户密码。该值保存在仅限 root 用户访问的文件 /etc/pve/priv/storage/<STORAGE-ID>.pw 中。必需。
要使用的 Proxmox Backup Server 进行数据存储的 ID 。
用于 Proxmox Backup Server 的 API 的 TLS 证书的指纹(fingerprint)。您可以在服务器仪表板中或使用 proxmox-backup-manager cert info 命令获取它。自签名证书或者主机不信任的任何一个服务器 CA 签发的证书是必需的。
用于加密客户端备份数据的密钥。目前仅支持非密码保护(无密钥派生功能(kdf))。保存在仅限 root 用户访问的文件 /etc/pve/priv/storage/<STORAGE-ID>.enc 中。使用魔法值 autogen,通过 proxmox-backup-client key create --kdf none <path> 来自动生成一个新的密钥。可选。
作为备份任务的一部分,用于加密 备份加密的密钥 的 RSA 公钥。加密的副本将被附加到备份中,并存储在 Proxmox Backup Server 实例上,以便进行恢复。可选,需要 encryption-key。
pbs: backup
datastore main
server enya.proxmox.com
content backup
fingerprint 09:54:ef:..snip..:88:af:47:fe:4c:3b:cf:8b:26:88:0b:4e:3c:b2
maxfiles 0
username archiver@pbsProxmox Backup Server 仅支持备份,备份可以基于块级或基于文件级。Proxmox VE 对虚拟机使用块级,对容器使用文件级。
| 内容类型 | 映像格式 | 是否共享 | 快照 | 克隆 |
|---|---|---|---|---|
backup |
n/a |
是 |
n/a |
n/a |
或者,您可以在 GCM 模式下使用 AES-256 配置客户端加密。可以通过 Web 界面或者使用 encryption-key 选项在 CLI 上配置加密(见上文)。密钥将保存在仅限 root 用户访问的文件 /etc/pve/priv/storage/<STORAGE-ID>.enc 中。
|
|
没有密钥,将无法访问备份。因此,您应该有序的保存放置密钥,并与所备份的内容分开的地方。例如,您可能会使用该系统上的密钥备份整个系统。如果系统由于任何原因导致无法访问并且需要进行恢复,这将是不可能的,因为损坏的系统将会失去加密的密钥。 |
建议您将密钥保存在安全且易于访问的位置,以便快速进行灾难恢复。出于这个原因,最好将它存储在您的密码管理器中,在那里它可以立即恢复。作为对此的备份,您还应该保存密钥到 USB 驱动器,并将其放在安全的地方。最后,为应对最坏的情况,您还应该考虑将密钥的纸质副本锁在安全的地方。可以使用 paperkey 子命令创建密钥的二维码版本。以下命令将使用 paperkey 命令输出发送到文本文件,以便于打印。
# proxmox-backup-client key paperkey /etc/pve/priv/storage/<STORAGE-ID>.enc --output-format text > qrkey.txt
此外,还可以使用单个 RSA 主密钥对进行密钥恢复:将所有执行加密备份的客户端配置为使用单个主公钥,并且所有后续加密备份将包含用于 AES 加密的使用 RSA 加密的密钥副本。即使客户端系统不再可用,对应的主私钥也允许恢复 AES 密钥并解密备份。(翻译备注:简单说就是用 AES 加密所有备份,然后用 RSA 公钥加密 AES 密钥,再附加到备份文件中,如果 AES 密钥丢失,可以用 RSA 私钥从备份文件中解密出 AES 的密钥进行解密。)
|
|
主密钥对的安全保管规则与常规加密密钥相同。如果没有私钥副本则不可能恢复!paperkey 命令支持生成主私钥的纸质副本,并安全存放在物理位置。 |
因为加密是在客户端管理的,您可以在服务器上为未加密备份和已加密备份使用相同的数据存储,即使它们使用不同密钥进行加密的。无论如何,是不可能删除不同密钥的备份之间的重复数据的,因此通常最好创建单独的数据存储。
|
|
如果加密没有任何好处,请不要使用加密。例如,当您在可信网络中本地运行服务器时。它总是可以更容易的从未加密的备份中恢复。 |
然后您可以通过以下命令,将此共享作为存储,添加到整个 Proxmox VE 集群:
# pvesm add pbs <id> --server <server> --datastore <datastore> --username <username> --fingerprint 00:B4:... --password
存储池类型:glusterfs
GlusterFS 是一个可扩展的网络文件系统。该系统采用模块化设计,在商用硬件上运行,能够以低成本提供高可用的企业存储。这样的系统能够扩展到数个 PB,并且可以处理数千个客户端。
|
|
在节点或块崩溃后,GlusterFS 会执行完整的 rsync 以确保数据的一致。对于大型文件,这可能需要很长时间,因此,该后端不适合存储大型 VM 映像。 |
该后端支持所有常见的存储属性,并添加以下 GlusterFS 特定选项:
GlusterFS volfile 服务器 IP 或者 DNS 名称。
备用 volfile 服务器 IP 或者 DNS 名称。
GlusterFS 卷。
GlusterFS 传输:tcp、unix 或 rdma
glusterfs: Gluster
server 10.2.3.4
server2 10.2.3.5
volume glustervol
content images,iso目录布局和文件命名约定继承自目录(dir)后端。
该存储提供文件级接口,但是非原生实现快照或克隆。
| 内容类型 | 映像格式 | 是否共享 | 快照 | 克隆 |
|---|---|---|---|---|
images vztmpl iso backup snippets | raw qcow2 vmdk |
是 |
qcow2 |
qcow2 |
存储池类型:zfspool
该后端允许您访问本地 ZFS 池(或此类池中的 ZFS 文件系统)。
该后端支持常见的存储属性(如 content(内容)、nodes(节点)、disable(禁用)),以及下列 ZFS 的专用属性:
选择 ZFS 池/文件系统。所有分配都在池中完成。
设置 ZFS 块大小参数。
使用 ZFS 自动精简配置(thin-provisioning)。稀疏卷是其不等于卷大小的预留卷。
ZFS 池/文件系统的挂载点。更改此项不会影响 zfs 看到的数据集的 mountpoint 属性。默认指向 /<pool>。
zfspool: vmdata
pool tank/vmdata
content rootdir,images
sparse该后端为 VM 映像使用以下命名方案:
vm-<VMID>-<NAME> // 普通 VM 映像 base-<VMID>-<NAME> // VM 模板映像(只读) subvol-<VMID>-<NAME> // 子卷(用于容器的 ZFS 文件系统)
这是指定 VM 的所有者
这可以是没有空格的任意名称(ascii)。该后端使用 disk[N] 作为默认值,其中 [N] 使用让名字唯一的整数替换。
在快照和克隆方面,ZFS 可能是最高级的存储类型。该后端为虚拟机(VM )映像(格式 raw )和容器数据(格式 subvol)使用 ZFS 数据集。ZFS 属性继承自父数据集,因此您只需在父数据集上设置默认值即可。
| 内容类型 | 映像格式 | 是否共享 | 快照 | 克隆 |
|---|---|---|---|---|
images rootdir |
raw subvol |
否 |
是 |
是 |
建议创建一个额外的 ZFS 文件系统用于存储您的 VM 映像:
# zfs create tank/vmdata
要在新分配的文件系统上启用压缩:
# zfs set compression=on tank/vmdata
您可以通过以下方式获取可用的 ZFS 文件系统列表:
# pvesm zfsscan
存储池类型:lvm
LVM 是位于硬盘和分区之上的轻量级软件层。它可用于将可用磁盘空间分割为更小的逻辑卷。LVM 广泛用于 Linux,让磁盘驱动器更容易管理。
另一个用例是将 LVM 置于大型 iSCSI LUN 之上。这样您就可以轻松管理该 iSCSI LUN 上的空间,否则这是不可能的,毕竟 iSCSI 规范没有为空间分配定义管理接口。
LVM 后端支持常见的存储属性(如 content(内容)、nodes(节点)、disable(禁用)),以及下列 LVM 的专用属性:
LVM 卷组名称。这必须指向现有的卷组。
基本卷。此卷在访问存储之前自动激活。当 LVM 卷组驻留在远程 iSCSI 服务器上时,这非常有用。
移除 LV 时将数据归零。这可以确保在移除卷时清除所有数据。
擦除吞吐量(cstream -t 参数值)。
lvm: myspace
vgname myspace
content rootdir,images该后端使用与 ZFS 池后端基本相同的命名约定。
vm-<VMID>-<NAME> // 普通 VM 映像
LVM 是典型的块存储,但是该后端不支持快照和克隆。不幸的是,普通的 LVM 快照效率低下,因为它们会在快照期间干扰整个卷组上的所有写入。
最大优势是您可以在共享存储(例如 iSCSI LUN)之后使用它。该后端本身实现了集群范围内适当的锁定。
|
|
较新的 LVM-thin 后端允许快照和克隆,但不支持共享存储。 |
| 内容类型 | 映像格式 | 是否共享 | 快照 | 克隆 |
|---|---|---|---|---|
images rootdir |
raw |
可用 |
否 |
否 |
列出可用卷组:
# pvesm lvmscan
存储池类型:lvmthin
LVM 通常在您创建卷时分配块。LVM thin 池在写入时分配块。这种行为称为自动精简配置(thin-provisioning),因为卷可能比物理可用空间大得多。
您可以使用普通的 LVM 命令行工具来管理和创建 LVM thin 池(有关详细信息,请参阅 man lvmthin)。假设您已有一个名为 pve 的 LVM 卷组,以下命令可以新建一个名为 data 的 LVM thin 池(大小为 100 G):
lvcreate -L 100G -n data pve lvconvert --type thin-pool pve/data
LVM thin 后端支持常见的存储属性(如 content(内容)、nodes(节点), disable(禁用)),以及下列 LVM 的专用属性:
LVM 卷组名称。这必须指向现有的卷组。
LVM thin 池的名称。
lvmthin: local-lvm
thinpool data
vgname pve
content rootdir,images该后端使用与 ZFS 池后端基本相同的命名约定。
vm-<VMID>-<NAME> // 普通 VM 映像
LVM thin 是块存储,但完全支持高效的快照和克隆。新的卷用零自动初始化。
必须提到的是,LVM thin 池不能跨越多个节点进行共享,因此您仅能将其用作本地存储。
| 内容类型 | 映像格式 | 是否共享 | 快照 | 克隆 |
|---|---|---|---|---|
images rootdir |
raw |
否 |
是 |
是 |
列出卷组 pve 上可用的 LVM thin 池:
# pvesm lvmthinscan pve
存储池类型:iscsi
iSCSI 是一种广泛应用的技术,用于连接到存储服务器。几乎所有的存储供应商都支持 iSCSI。还有可用的开源 iSCSI target 解决方案,例如 OpenMediaVault,它基于 Debian。
要使用该后端,您需要安装 Open-iSCSI (open-iscsi)软件包。这是一个标准的 Debian 软件包,但为了节省资源,默认情况下不会安装。
# apt-get install open-iscsi
可以使用 iscsiadm 工具完成低级别的 iscsi 管理任务。
该后端支持常见的存储属性(如 content(内容)、nodes(节点)、disable(禁用)),以及下列 iSCSI 的专用属性:
iSCSI 网络端口(portal)(带有可选端口的 IP 或 DNS 名称)。
iSCSI 目标(target)。
iscsi: mynas
portal 10.10.10.1
target iqn.2006-01.openfiler.com:tsn.dcb5aaaddd
content none|
|
如果您希望在 iSCSI 之上使用 LVM,应该合理的设置 content none。这样就无法直接的使用 iSCSI LUN 创建 VM 。 |
The iSCSI 协议未定义分配或删除数据的接口。相反,这需要在目标端完成,并且是特定于供应商的。目标只将它们导出为编号的 LUN。因此,Proxmox VE iSCSI 卷名只是对 linux 内核可见的有关 LUN 的一些信息进行编码。
iSCSI 是块级类型的存储,不提供管理接口。所以通常最好导致出一个大的 LUN,并在该 LUN 之上设置 LVM。您可以使用 LVM 插件管理该 iSCSI LUN 上的存储。
| 内容类型 | 映像格式 | 是否共享 | 快照 | 克隆 |
|---|---|---|---|---|
images none |
raw |
是 |
否 |
否 |
创建远程 iSCSI 网络端口(portal),并返回可用的目标(target)列表:
pvesm scan iscsi <HOST[:PORT]>
存储池类型:iscsidirect
该后端提供与 Open-iSCSI 支持的功能基本相同,但使用用户级别的库(软件包 libiscsi2)来实现。
需要注意的是,这里没有涉及内核驱动程序,因此可以将其视为性能优化。但这也带来了一个缺点,即不能在此类 iSCSI LUN 之上使用 LVM。所以,您需要在存储服务器端管理所有的空间分配。
用户模式 iSCSI 后端使用与 Open-iSCSI 支持相同的配置选项。
iscsidirect: faststore
portal 10.10.10.1
target iqn.2006-01.openfiler.com:tsn.dcb5aaaddd|
|
该后端仅作用于 VM 。容器无法使用该驱动。 |
| 内容类型 | 映像格式 | 是否共享 | 快照 | 克隆 |
|---|---|---|---|---|
images |
raw |
是 |
否 |
否 |
存储池类型:rbd
Ceph 是一个分布式对象存储和文件系统,旨在提供卓越的性能、可能性和可扩展性。RADOS 块设备实现了特性丰富的块级存储,您将获得以下优势:
自动精简配置(thin provisioning)
可调整大小的卷
分布式和冗余(在多个 OSD 上条带)
完整的快照和克隆能力
自我修复
无单点故障
可扩展到 EB 级别
内核和用户空间实现可用
|
|
对于较小的部署,也可以直接在 Proxmox VE 节点上运行 Ceph 服务。新近的硬件具有充足的 CPU 性能和内存,因此可以在同一节点上运行存储服务和 VM 。 |
该后端支持常见的存储属性(如 nodes(节点)、 disable(禁用)、content(内容)),以及下列 rbd 的专用属性:
监控守护进程的 IP 列表。可选,仅当 Ceph 不在 PVE 集群上运行时才需要。
Ceph 池名称。
RBD 用户 ID 。可选,仅当 Ceph 不在 PVE 集群上运行时才需要。请注意,应当仅使用用户 ID 。"client." 的类型前缀必须省略。
通过 krbd 内核模块强制访问 rados 块设备。可选。
|
|
容器将使用与选项值无关的 krbd 。 |
rbd: ceph-external
monhost 10.1.1.20 10.1.1.21 10.1.1.22
pool ceph-external
content images
username admin|
|
您可以使用 rbd 实用程序来执行低级别的管理任务。 |
如果您使用 cephx 身份验证,需要将密钥文件从外部 Ceph 集群复制到 Proxmox VE 主机。
通过以下命令创建目录 /etc/pve/priv/ceph
mkdir /etc/pve/priv/ceph
然后复制 keyring 文件
scp <cephserver>:/etc/ceph/ceph.client.admin.keyring /etc/pve/priv/ceph/<STORAGE_ID>.keyring
此 keyring 文件的命名必须与您的 <STORAGE_ID> 匹配。复制 keyring 文件通常需要 root 权限。
如果 Ceph 本地安装在 PVE 集群上,这将通过 pveceph 或 GUI 界面中自动完成。
rbd 后端是块级存储,并实现完整的快照和克隆功能。
| 内容类型 | 映像格式 | 是否共享 | 快照 | 克隆 |
|---|---|---|---|---|
images rootdir |
raw |
是 |
是 |
是 |
存储池类型:cephfs
CephFS 实现了 POSIX 兼容的文件系统,使用 Ceph 存储集群来存储其数据。由于 CephFS 是建立在 Ceph 之上,因此它共享其大部分属性。这包括冗余、可扩展性、自我修复和高可用性。
|
|
Proxmox VE 可以 管理 Ceph 设置,这使得配置 CephFS 存储更容易。由于现代硬件提供了大量处理能力和内存,因此可以在同一节点上运行存储服务和 VM ,而不会对性能产生重大影响。 |
要使用 CephFS 存储插件,您需要通过添加我们的 Ceph 存储库 来替换现存的 Debian Ceph 客户端。添加以后,先运行 apt update,再运行 apt dist-upgrade,以获得最新的软件包。
|
|
请确保没有配置其他 Ceph 存储库。否则安装将会失败,或者在节点上会出现软件包版本混合,导致意外行为。 |
该后端支持常见的存储属性(如 nodes(节点)、 disable(禁用)、content(内容)),以及下列 cephfs 的专用属性:
监控守护进程的地址列表。可选,仅当 Ceph 不在 PVE 集群上运行时才需要。
本地挂载点。可选,默认指向 /mnt/pve/<STORAGE_ID>/。
Ceph 用户 ID 。可选,仅当 Ceph 不在 PVE 集群上运行时才需要,默认为 admin。
CephFS 挂载的子目录。可选,默认指向 / 。
通过 FUSE 而不是内核客户端访问 CephFS 。可选,默认为 0。
cephfs: cephfs-external
monhost 10.1.1.20 10.1.1.21 10.1.1.22
path /mnt/pve/cephfs-external
content backup
username admin|
|
如果 cephx 未禁用,不要忘记设置客户端的密钥文件。 |
如果您使用 cephx 身份验证,它是默认启用的,您需要将密钥文件从外部 Ceph 集群复制到 Proxmox VE 主机。
通过以下命令创建目录 /etc/pve/priv/ceph
mkdir /etc/pve/priv/ceph
然后复制 secret 文件
scp cephfs.secret <proxmox>:/etc/pve/priv/ceph/<STORAGE_ID>.secret
此 secret 文件的命名必须与您的 <STORAGE_ID>匹配。复制 secret 文件通常需要 root 权限。该文件必须只包含密钥本身,而不是包含 rbd 后端的 [client.userid] 部分。
通过发出以下命令,可以从 Ceph 集群(由 Ceph 管理员)接收密钥,其中 userid 是已配置为访问集群的客户端 ID 。有关 Ceph 用户管理的更多信息,请参阅
Ceph 文档
[Ceph 用户管理 https://docs.ceph.com/en/nautilus/rados/operations/user-management/]
。
ceph auth get-key client.userid > cephfs.secret
如果 Ceph 本地安装在 PVE 集群上,也就是说,它是使用 pveceph 设置的,这会自动完成。
cephfs 后端是 POSIX 兼容的文件系统,位于 Ceph 集群之上。
| 内容类型 | 映像格式 | 是否共享 | 快照 | 克隆 |
|---|---|---|---|---|
vztmpl iso backup snippets |
none |
是 |
是 [1] |
否 |
[1] 虽然不存在已知的错误,但是快照还不能保证稳定,因为它们缺乏足够的测试。
存储池类型:btrfs
从表面上看,这种存储类型与目录存储类型非常相似,常规概述请参阅目录后端部分。
主要区别在于,对于这种存储类型,raw 格式的磁盘将被放置在一个子卷中,以便允许生成快照并支持离线存储迁移时保留快照。
|
|
BTRFS 在打开文件时会接受 O_DIRECT 标志,这意味着 VM 不应使用缓存模式 none,否则将出现校验和(checksum)错误。 |
该后端的配置类似于目录存储。请注意,当添加目录作为 BTRFS 存储时,它本身不是挂载点,强烈建议通过 is_mountpoint 选项指定实际的挂载点。
例如,如果 BTRFS 文件系统已挂载为 /mnt/data2,并且它的子目录 pve-storage/(这可能是快照,推荐作法)要添加为存储池(名为 data2),您可以使用以下条目:
btrfs: data2
path /mnt/data2/pve-storage
content rootdir,images
is_mountpoint /mnt/data2当生成子卷或 raw 文件的快照时,快照将创建为只读子卷,其路径相同,后跟 @ 和快照的名称。
存储池类型:zfs
该后端通过 ssh 访问具有使用 ZFS 池作为存储和 iSCSI 目标(target)实现的远程机器。它为每个来宾磁盘创建一个 ZVOL,并将其导出为 iSCSI LUN 。Proxmox VE 将此 LUN 用于来宾磁盘。
下列支持 iSCSI 目标(target)的实现:
LIO (Linux)
IET (Linux)
ISTGT (FreeBSD)
Comstar (Solaris)
|
|
此插件需要支持 ZFS 的远程存储设备,您不能使用它在常规存储设备/SAN 上创建 ZFS 池。 |
为了使用基于 iSCSI 的 ZFS 的插件,您需要配置远程机器(目标,target),接受来自 Proxmox VE 节点的 ssh 连接。Proxmox VE 连接到目标以创建 ZVOL 并通过 iSCSI 导出它们。通过存储在 /etc/pve/priv/zfs/<target_ip>_id_rsa 的 ssh-key(无密码保护)完成身份验证。
通过以下步骤,将创建一个 ssh-key 并将其分发到 IP 为 192.0.2.1 的存储机器:
mkdir /etc/pve/priv/zfs ssh-keygen -f /etc/pve/priv/zfs/192.0.2.1_id_rsa ssh-copy-id -i /etc/pve/priv/zfs/192.0.2.1_id_rsa.pub root@192.0.2.1 ssh -i /etc/pve/priv/zfs/192.0.2.1_id_rsa root@192.0.2.1
该后端支持常见的存储属性(如 content(内容)、nodes(节点)、disable(禁用)),以及下列基于 iSCSI 的 ZFS 的专用属性:
位于 iSCSI 目标(target)上的 ZFS 池/文件系统。所有分配都在该池中完成。
iSCSI 网络端口(portal)(可选端口的 IP 或者 DNS 名称)。
iSCSI 目标(target)。
用于远程机器上的 iSCSI 目标(target)的实现
comstar 视图的目标组。
comstar 视图的主机组。
Linux LIO 目标的目标网络端口(portal)组
禁用目标上的写缓存
设置 ZFS 块大小参数。
使用 ZFS 自动精简配置(thin-provisioning)。稀疏卷是其不等于卷大小的预留卷。
zfs: lio blocksize 4k iscsiprovider LIO pool tank portal 192.0.2.111 target iqn.2003-01.org.linux-iscsi.lio.x8664:sn.xxxxxxxxxxxx content images lio_tpg tpg1 sparse 1 zfs: solaris blocksize 4k target iqn.2010-08.org.illumos:02:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx:tank1 pool tank iscsiprovider comstar portal 192.0.2.112 content images zfs: freebsd blocksize 4k target iqn.2007-09.jp.ne.peach.istgt:tank1 pool tank iscsiprovider istgt portal 192.0.2.113 content images zfs: iet blocksize 4k target iqn.2001-04.com.example:tank1 pool tank iscsiprovider iet portal 192.0.2.114 content images
基于 iSCSI 的 ZFS 的插件提供了一个共享存储,并支持快照。您需要确保 ZFS 设备不会成为部署中的单点故障。
| 内容类型 | 映像格式 | 是否共享 | 快照 | 克隆 |
|---|---|---|---|---|
images |
raw |
是 |
是 |
否 |
Proxmox VE 统一了您的计算和存储系统,也就是说,您可以在集群内使用相同的物理节点进行计算(处理 VM 和容器)和复制存储。传统的计算孤岛和存储资源可以封装到单个超融合设备中。独立的存储网络(SAN)和通过网络附加的存储(NAS)的连接不复存在了。通过集成开源软件定义存储平台 Ceph,Proxmox VE 能够直接在虚拟机管理程序上直接运行和管理 Ceph 存储。
Ceph 是一个分布式对象存储和文件系统,旨在提供卓越的性能、可靠性和可扩展性。
通过 CLI 和 GUI 轻松设置和管理
自动精简配置
快照支持
自我修复
可扩展到 EB 级别
设置具有不同性能和冗余特征的资源
数据可再生且具容错性
运行在普通硬件上
无须硬件 RAID 控制器
开源
对于中小型部署,可以直接在 Proxmox VE 集群节点上为 Ceph RADOS 块设备(RADOS Block Devices,简称 RBD)安装 Ceph 服务器(请参阅 Ceph RADOS 块设备(RADOS Block Devices,简称 RBD))。新近的硬件具有充足的 CPU 性能和内存,因此可以在同一节点上运行存储服务和 VM 。
为了简化管理,我们提供了 pveceph - 用于在 Proxmox VE 节点上安装和管理 Ceph 服务的一种工具。
Ceph 监视器 (ceph-mon)
Ceph 管理员(ceph-mgr)
Ceph OSD(ceph-osd; Object Storage Daemon,对象存储守护进程,简称 OSD)
|
|
我们强烈建议您熟悉 Ceph [Ceph 简介 https://docs.ceph.com/en/nautilus/start/intro/] 及其架构 [Ceph 架构 https://docs.ceph.com/en/nautilus/architecture/] 和词汇 [Ceph 术语汇编 https://docs.ceph.com/en/nautilus/glossary] 。 |
要建立一个 Proxmox + Ceph 超融合集群,必须使用至少三台(最好)相同的服务器进行设置。
还可以从 Ceph 的网站 查看建议。
优先选用高频率的 CPU 核心,可以减少延迟。作为一个简单的经验法则,您应该为每个 Ceph 服务分配一个 CPU 核心(或线程),为实现稳定且持久的 Ceph 性能提供足够的资源。
特别是在超融合设置中,需要仔细监控内存的消耗。除了预计虚拟机和容器的内存使用量之外,您还必须考虑是否有足够的可用内存,保证 Ceph 能够提供出色且稳定的性能。
根据经验,对于大约 1TB 的数据 ,OSD 将使用 1GB 的内存。特别是在恢复、再平衡或回填期间。
守护进程本身将使用额外的内存。守护进程的 Bluestore 后端默认需要 3-5GB 的内存(可调整)。相比之下,旧式的 Filestore 后端使用 OS 页面缓存,内存消耗通常与 OSD 守护进程的 PG 有关。
我们建议网络带宽至少 10Gb 或更高,专供 Ceph 使用。如果没有可用的 10Gb 交换机,网状网络设置
[用于 Ceph 的全网状网络 https://pve.proxmox.com/wiki/Full_Mesh_Network_for_Ceph_Server]
也是一种选择。
数据通信量(特别是在恢复期间)会干扰同一网络上的其他服务,甚至可能会破坏 Proxmox VE 集群堆栈。
此外,您应该估计您的带宽需求。虽然一个 HDD 可能不会让 1Gb 链接饱和,但是每个节点的多个 HDD 的 OSD 可以,而且现代的 NVMe SSD 甚至会很快使 10Gb 的带宽饱和。部署能够提供更多带宽的网络将确保这不是您的瓶颈,也不会很快成为瓶颈。25、40 甚至 100 Gb 都是可能的。
在规划 Ceph 集群的大小时,重要的是要考虑恢复时间。特别是对于小型集群,恢复可能需要很长时间。建议您在小型设置中使用 SSD 而不是 HDD 以减少恢复时间,从而最大限度地减少恢复过程中发生后续故障事件的可能性。
一般来说,SSD 将提供比机械磁盘更多的 IOPS 。考虑到这一点,除了更高的成本之外,实现 基于设备类别 的存储池(pools)的分离可能是有意义的。另一种加速 OSD 的方法是使用更快的磁盘作为日志或 DB / Write-Ahead-Log(WAL,预写式日志)设备,请参阅 创建 Ceph OSD 。如果一个更快的磁盘用于多个 OSD,则必须在 OSD 和 WAL / DB(或日志)磁盘之间选择适当的平衡,否则更快的磁盘将成为所有链接 OSD 的瓶颈。
除了磁盘类型之外,Ceph 在每个节点的磁盘大小和分布数量均匀的情况下表现佳。例如,每个节点内的 4 x 500GB 磁盘优于具有单个 1TB 和三个 250GB 磁盘的混合设置。
您还需要平衡 OSD 数量和单个 OSD 容量。更多容量可以让您提高存储密度,但这也意味着单个 OSD 故障会迫使 Ceph 一次恢复更多的数据。
由于 Ceph 自行处理数据对象冗余和多次并行写入磁盘(OSD),因此使用 RAID 控制器通常不会提高性能或可用性。相反,Ceph 旨在自行处理整个磁盘,之间没有任何抽象。RAID 控制器不是设计用于 Ceph 的工作负载,可能会使情况复杂化,有时甚至会降低性能,因为它们的写入和缓存算法可能会干扰 Ceph 的算法。
|
|
避免使用 RAID 控制器。请改用主机总线适配器(HBA)。 |
|
|
以上建议应视为选择硬件的大致指导。因此,使其适应您的特定需求仍然是必不可少的。您应该测试您的设置,并持续监视健康状态和性能。 |
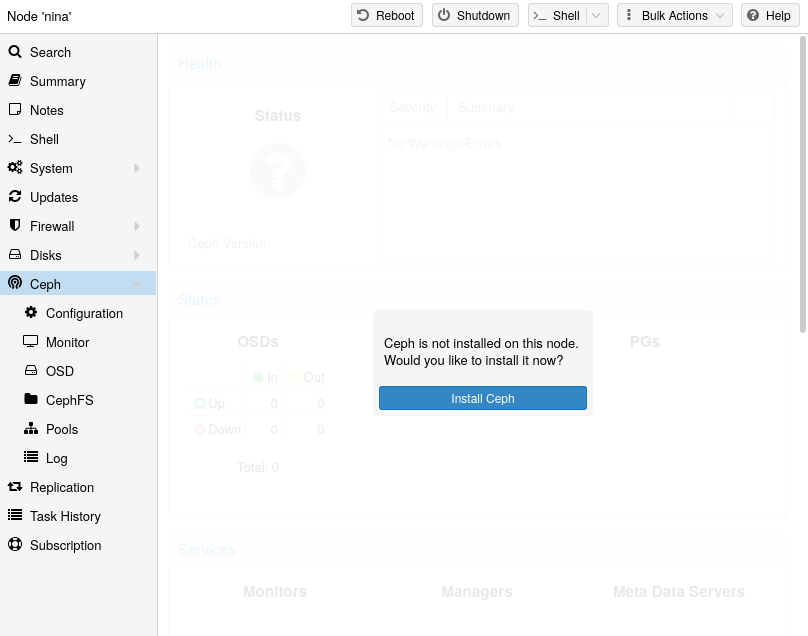
通过 Proxmox VE,您将具有易于使用的 Ceph 安装向导。单击您的集群节点之一并导航到菜单树中的 Ceph 部分。如果尚未安装 Ceph,您会看到到一个安装 Ceph 的提示。
该向导分为多个部分,每个部分都需要成功完成,才能使用 Ceph。
首先,您需要选择要安装的 Ceph 版本。首选其他节点中的一个,如果这是您安装 Ceph 的第一个节点,则选择最新的一个。
开始安装后,向导将从 Proxmox VE 的 Ceph 存储库下载并安装所有必需的软件包。
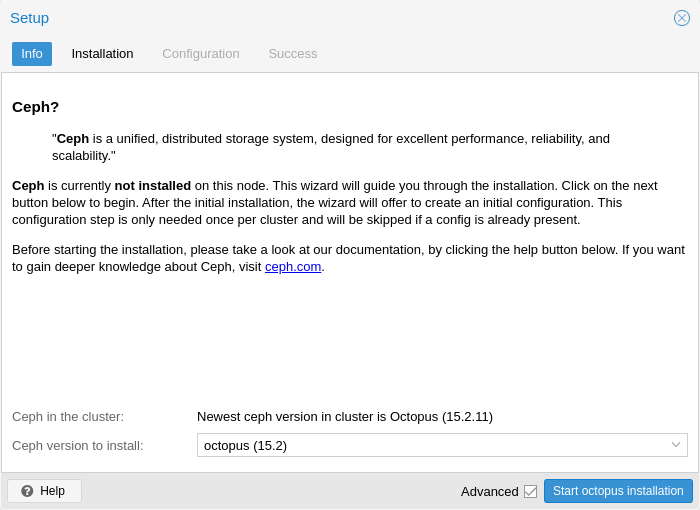
完成安装步骤后,您将需要创建一个配置。每个集群只需执行一次此步骤,因为此配置会通过 Proxmox VE 的 集群配置文件系统(pmxcfs) 自动分发到所有剩余的集群成员。
配置步骤包括以下设置:
公共网络:您可以为 Ceph 设置专用网络。该设置是必需的。强烈建议分离您的 Ceph 流量。否则,它可能会给其他依赖延迟的服务带来问题,例如:集群通信可能降低 Ceph 的性能。
集群网络:作为可选步骤,您还可以进一步分离 OSD 复制和心跳流量。这将减轻公共网络的负担,并可以导致显著的性能改善,尤其是在大型集群中。
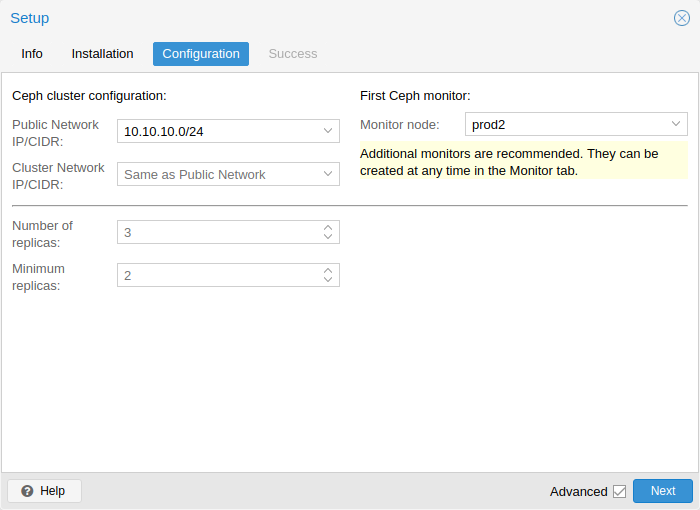
您还有两个被认为是高级的选项,因此只有在您知道自己在做什么时才应该更改。
副本数量:定义对象的复制频率
最小副本:定义要标记为完成的 I/O 所需的最小副本数。
此外,您需要选择第一个监控节点。此步骤是必需的。
就是这样,您现在应该可以看到一个成功页面作为最后一步,以及有关如何继续的进一步说明。您的系统现在已经准备好了开始使用 Ceph。首先,您需要创建一些额外的 监视器、 OSD 和至少一个 pool(存储池)。
本章的其余部分将指导您充分利用基于 Proxmox VE 的 Ceph 设置。这包括前面提到的更多技术,例如 CephFS,这是对新 Ceph 集群的有益补充。
除了 Web 界面中推荐的 Proxmox VE Ceph 安装向导之外,您还可以在每个节点上使用以下 CLI 命令:
pveceph install
这会在 /etc/apt/sources.list.d/ceph.list 中设置一个 apt 软件包存储库,并安装所需的软件。
使用 Proxmox VE Ceph 安装向导(推荐)或在一个节点运行以下命令:
pveceph init --network 10.10.10.0/24
这会在 /etc/pve/ceph.conf 中创建一个初始配置,并为 Ceph 建立一个专用的网络。该文件使用 pmxcfs 自动分发到所有 Proxmox VE 节点。命令还在 /etc/ceph/ceph.conf 中创建了一个符号链接,指向该文件。因此,您可以简单地运行 Ceph 命令而无需指定配置文件。
Ceph 监视器 (MON)
[Ceph 监视器 https://docs.ceph.com/en/nautilus/start/intro/]
维护集群映射的主副本。为实现高可用性,您至少需要 3 个监视器。如果使用安装向导,则已经安装了一个监视器。只要您的集群是中小型的,您就不需要超过 3 个监视器,仅非常大型的集群才会需要更多监视器。
在要放置监视器的每个节点上(推荐三个监视器),使用 GUI 界面中的 Ceph → 监视器 选项卡创建一个或运行:
pveceph mon create
要通过 GUI 删除 Ceph 监视器,首先在树视图中选择一个节点,然后转到 Ceph → 监视器 面板。选择要删除的监视器并单击 销毁 按钮。
要通过 CLI 删除 Ceph 监视器,首先连接到正在运行监视器的节点。然后执行以下命令:
pveceph mon destroy
|
|
仲裁(quorum)至少需要三个监视器。 |
管理员守护进程与监视器一起运行。它提供了一个界面用于监视集群。自 Ceph luminous 发布以来,至少需要一个 ceph-mgr
[Ceph 管理员 https://docs.ceph.com/en/nautilus/mgr/]
守护进程。
可以安装多个管理员,但在任何给定时间仅有一个管理员处于活动状态。
pveceph mgr create
|
|
建议在监视器的节点上安装 Ceph 管理员。要获得高可用性,请安装多个管理员。 |
要通过 GUI 删除 Ceph 管理员,首先在树视图中选择一个节点,然后转到 Ceph → 监视器 面板。选择要删除的管理员并单击 销毁 按钮。
要通过 CLI 删除 Ceph 管理员,首先连接到正在运行管理员的节点。然后执行以下命令:
pveceph mgr destroy
|
|
虽然管理员不是硬依赖,但是它对于 Ceph 集群至关重要,毕竟它可以处理 PG-autoscaling 、设备健康监视、遥测等重要功能。 |
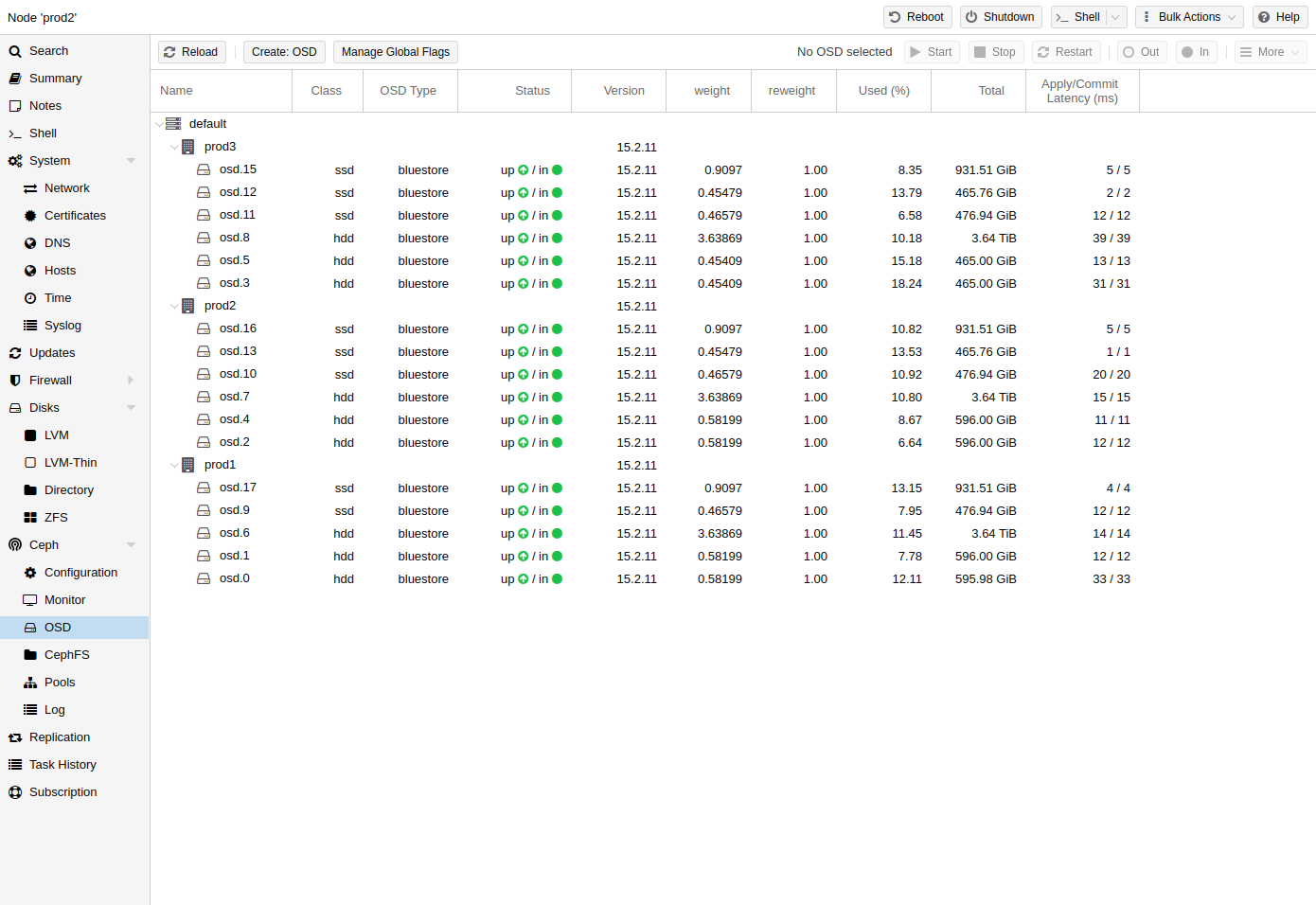
Ceph 对象存储守护进程(Object Storage Daemons,简称 OSD)通过网络为 Ceph 存储对象。建议每个物理磁盘上使用一个 OSD 。
您可以通过 Proxmox VE Web 界面或者通过 CLI 使用 pveceph 命令创建 OSD。例如:
pveceph osd create /dev/sd[X]
|
|
我们建议 Ceph 集群至少有三个节点和至少 12 个 OSD,均匀分布在节点之间。 |
如果磁盘已被使用过(例如,用于 ZFS 或作为 OSD),您首先需要清除所有使用的痕迹。要删除分区表、引导扇区和任何其他 OSD 的残留内容,您可以使用以下命令:
ceph-volume lvm zap /dev/sd[X] --destroy
|
|
上面的命令会销毁磁盘上的所有数据! |
自 Ceph Karken 版本开始,引入了一种新的 Ceph OSD 存储类型,称为 Bluestoe
[Ceph Bluestore https://ceph.com/community/new-luminous-bluestore/]
。这是自 Ceph Luminous 以来创建 OSD 的默认设置。
pveceph osd create /dev/sd[X]
如果您想为您的 OSD 使用单独的 DB/WAL 设备,您可以通过指定 -db_dev 和 -wal_dev 选项。如果未单独指定,则 WAL 和 DB 一起放置。
pveceph osd create /dev/sd[X] -db_dev /dev/sd[Y] -wal_dev /dev/sd[Z]
您可以分别使用 -db_size 和 -wal_size 参数来直接选择那些的大小。如果未给出,将使用以下值(按顺序):
bluestore_block_{db,wal}_size from Ceph configuration…
… database, section osd
… database, section global
… file, section osd
… file, section global
10% (DB)/1% (WAL) of OSD size
|
|
DB 用于存储 BlueStore 的内部数据,而 WAL 是 BlueStore 的内部日志或预写式日志。建议使用快速 SSD 或 NVRAM 以获得更好的性能。 |
在 Ceph Luminous 之前,Filestore 是 Ceph OSD 使用的默认存储类型。从 Ceph Nautilus 开始,Proxmox VE 不再支持使用 pveceph 创建此类 OSD。如果您仍想创建 filestore 类型的 OSD,请直接使用 ceph-volume 。
ceph-volume lvm create --filestore --data /dev/sd[X] --journal /dev/sd[Y]
要通过 GUI 删除 OSD ,首先在树视图中选择 Proxmox VE 节点,然后转到 Ceph → OSD 面板。接着选择要删除的 OSD 并单击 OUT 按钮。一旦 OSD 的状态从 in 变为 out,单击 停止 按钮。最后,它的状态将从 up 变为 down,从 更多 下拉菜单中选择 销毁 。
要通过 CLI 删除 OSD,请运行以下命令:
ceph osd out <ID> systemctl stop ceph-osd@<ID>.service
|
|
第一个命令告知 Ceph 在数据分发中不包括 OSD 。第二个命令停止 OSD 服务。此刻,数据还未丢失。 |
以下命令将销毁 OSD,指定 -cleanup 选项可额外销毁分区表。
pveceph osd destroy <ID>
|
|
上面的命令会销毁磁盘上的所有数据! |
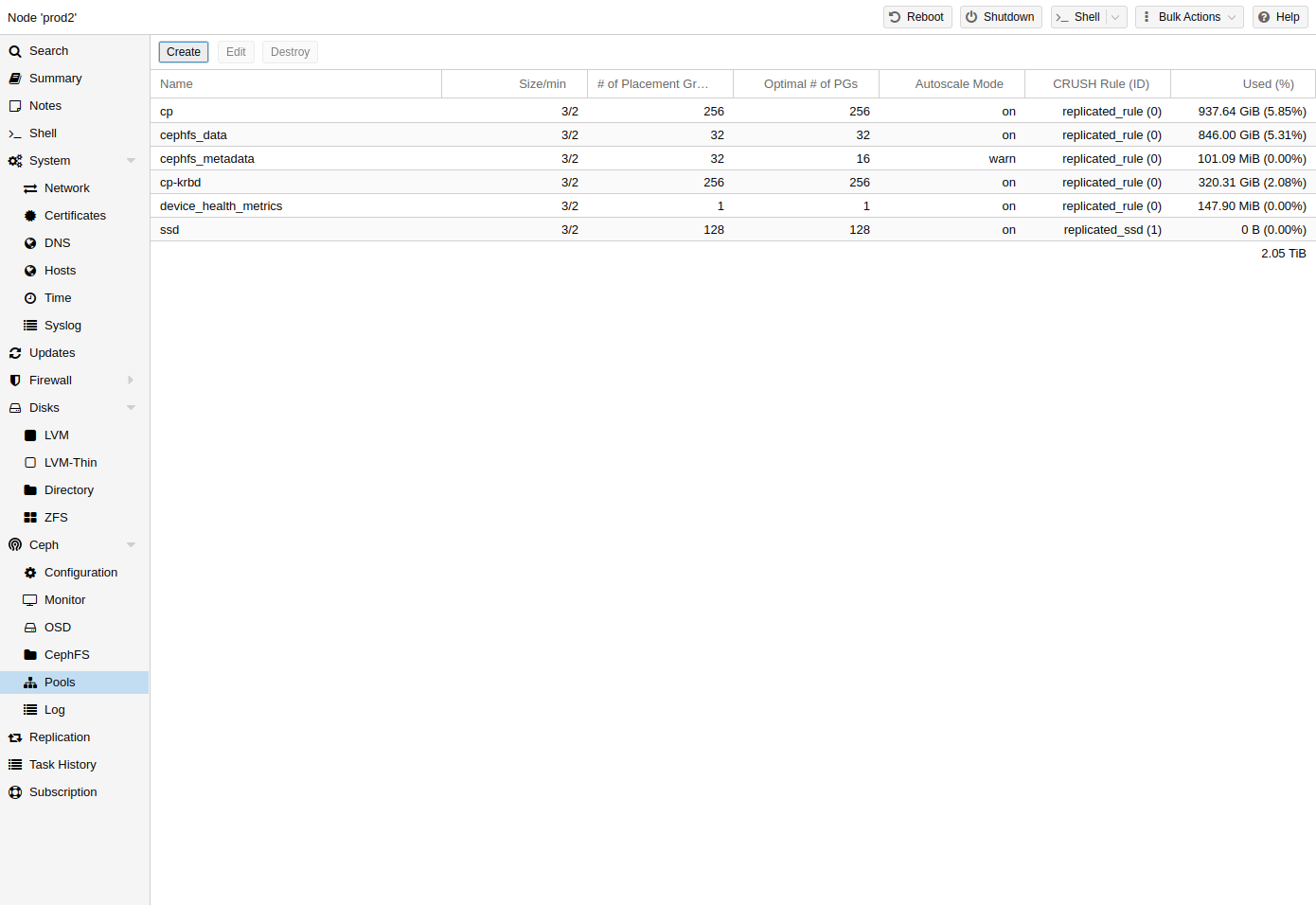
存储池(Pool,也称为 池 或者 资源池等)是一个用于存储对象的逻辑组。它包含一个对象合集,被称为归置组(Placement Groups,简称 PG,pg_num)。
您可以从命令行或任何 Proxmox VE 主机的 Web 界面的Ceph → Pools 下创建和编辑 pools(存储池)。
当未给予选项时,我们默认设置了 PGs 为 128,副本的大小为 3 和 副本的最小尺寸(min_size)为 2,以确保在任何 OSD 故障时不会发生数据丢失。
|
|
不要设置最小尺寸为 1 。使用最小尺寸为 1 的副本池允许对只有 1 个副本的对象进行 I/O 时,这可能导致数据丢失、不完整的 PGs 或找不到对象。 |
建议您启用 PG-Autoscaler 或者根据您的设置计算 PG 的数字。您可以在线找到公式和 PG 计算器
[PG 计算器 https://web.archive.org/web/20210301111112/http://ceph.com/pgcalc/]
。从 Ceph Nautilus 开始,您可以在设置后更改 PGs
[归置组 https://docs.ceph.com/en/nautilus/rados/operations/placement-groups/]
的数值。
PG autoscaler
[自动缩放 https://docs.ceph.com/en/nautilus/rados/operations/placement-groups/#automated-scaling]
可以在后台自动缩放存储池的 PG 数量。设置 目标大小 或 目标比率 高级参数有助于 PG-Autoscaler 做出更好的决策。
pveceph pool create <name> --add_storages
|
|
如果还想把您的存储池自动定义为存储,请在 Web 界面中选中 ‘添加存储’ 复选框,或在创建存储池时使用命令行选项 --add_storages。 |
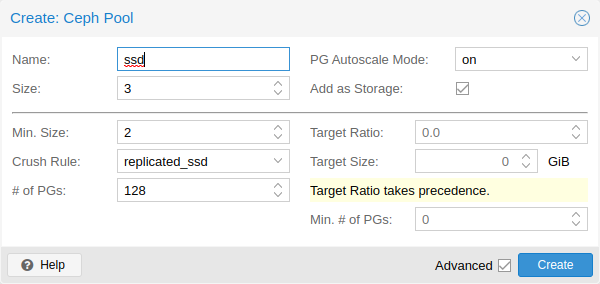
以下选项可用于创建存储池时,部分也可用于编辑存储池时。
存储池的名称。这必须是唯一且不能更改。
每个对象的副本数。Ceph 始终尝试拥有一个对象的更多副本。默认值:3 。
该存储池的自动 PG 缩放模式
[autoscaler]
。如果设置为 warn(警告),则当存储池具有非最佳 PG 数量时会生成警告消息。默认值:warn 。
将新存储池配置为 VM 或容器的存储。默认值:true(仅在创建时可见)。
每个对象的最小副本数。如果 PG 的副本数少于此数量,Ceph 将拒绝存储池上的 I/O 操作。默认值:2 。
用于映射集群中对象归置的规则。这些规则定义了数据在集群内如何放置。了解有关基于设备的规则的信息,请参阅 Ceph CRUSH & 设备类别。
存储池开始时应具有的归置组
[归置组]
的数量。默认值:128 。
存储池中预期的数据比率。PG autoscaler 使用与其他比率设定相对的比率。如果两者都设置,则优先于目标大小。
存储池中预期的预估数据量。PG autoscaler 使用此大小来预估最佳的 PG 数量。
归置组的最小数量。此设置用于微调该池的 PG 数量的下限。PG autoscaler 将不会合并低于此阈值的 PGs 。
关于 Ceph 存储池的更多信息可以在 Ceph 存储池操作手册
[Ceph 存储池操作手册 https://docs.ceph.com/en/nautilus/rados/operations/pools/]
中找到。
要通过 GUI 销毁存储池,在树视图中选择一个节点,然后转到 Ceph → Pools 面板。选择要销毁的存储池并单击 销毁 按钮。您需要输入存储池的名称来确认存储池的销毁。
运行以下命令以销毁存储池。如果同时指定 -remove_storages 参数还可以删除关联的存储。
pveceph pool destroy <name>
|
|
存储池的删除在后台运行,可能需要一些时间。您会注意到在整个过程中集群中的数据使用量在减少。 |
PG autoscaler 允许集群考虑每个存储池中存储的(预估)数据量并自动选择适当的 pg_num 值。它从 Ceph Nautilus 开始可用。
在调整生效之前,您可能需要激活 PG autoscaler 模块。
ceph mgr module enable pg_autoscalerAutoscaler 是在每个存储池的基础上配置的,具有以下模式:
| warn |
如果建议的 pg_num 值与当前值相差太大,则会发出健康警告。 |
| on |
pg_num 会自动调整而无需任何手动交互。 |
| off |
不进行自动 pg_num 调整,即使 PG 数量不是最优的,也不会发出警告。 |
可以通过使用 target_size、target_size_ratio 以及 pg_num_min 选项调整缩放因子以促进将来的数据存储。
|
|
默认情况下,如果存储池的 PG 数量下降了 3 倍,则 autoscaler 会考虑调整该存储池的 PG 数量,这将导致数据归置发生相当大的变化,并可能给集群带来高负载。 |
您可以在 Ceph 的博客上找到对 PG autoscaler 更多的深入介绍 - New in Nautilus: PG merging and autotuning.
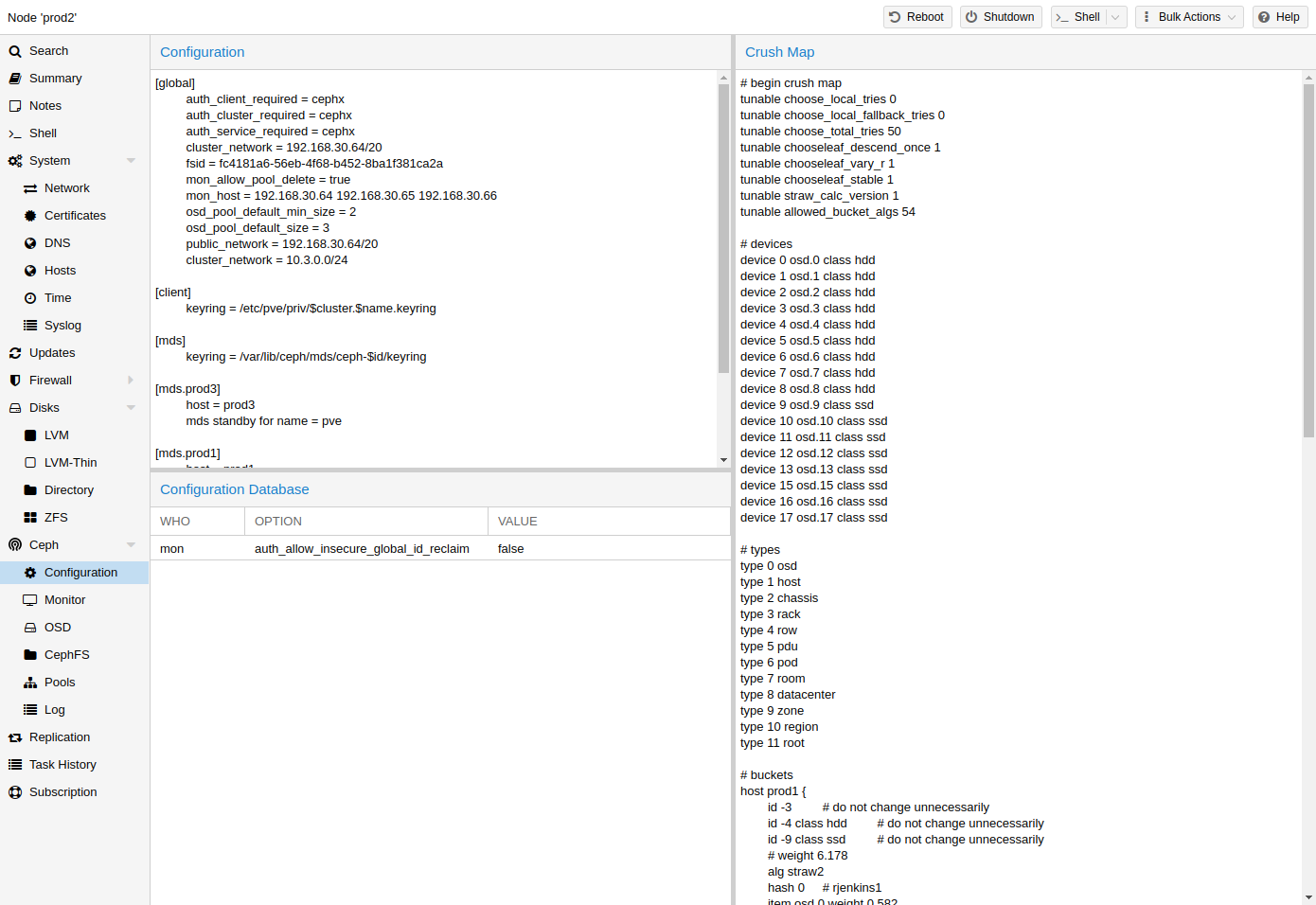
CRUSH
[CRUSH https://ceph.com/wp-content/uploads/2016/08/weil-crush-sc06.pdf]
(Controlled
Replication Under Scalable Hashing 的简称)算法是 Ceph 的基础。
CRUSH 计算存储和检索数据的位置。这具有无需中央索引服务的优点。CRUSH 使用 OSD 地图(map)、桶(buckets)(设备位置)和存储池的规则集(数据复制)来工作。
|
|
更多信息可以在 Ceph 文档中的 CRUSH map 章节 [CRUSH map https://docs.ceph.com/en/nautilus/rados/operations/crush-map/] 下找到。 |
可以修改此地图(map)以反映不同的复制层次结构。对象副本可以分离(例如,故障域),同时保持所需的分布。
一个常见的配置是为不同的 Ceph 存储池使用不同类别的磁盘。出于这个原因,Ceph 在 luminous 版本引入了设备类别,以满足轻松生成规则集的需要。
设备类别可以在 ceph osd tree 的输出中看到。这些类别代表各自的 root 桶(bucket),可以使用以下命令查看。
ceph osd crush tree --show-shadow
上述命令的输出范例:
ID CLASS WEIGHT TYPE NAME -16 nvme 2.18307 root default~nvme -13 nvme 0.72769 host sumi1~nvme 12 nvme 0.72769 osd.12 -14 nvme 0.72769 host sumi2~nvme 13 nvme 0.72769 osd.13 -15 nvme 0.72769 host sumi3~nvme 14 nvme 0.72769 osd.14 -1 7.70544 root default -3 2.56848 host sumi1 12 nvme 0.72769 osd.12 -5 2.56848 host sumi2 13 nvme 0.72769 osd.13 -7 2.56848 host sumi3 14 nvme 0.72769 osd.14
要指示存储池在特定类别的设备上分发对象,您首先需要为此类别的设备创建一个规则集:
ceph osd crush rule create-replicated <rule-name> <root> <failure-domain> <class>
<rule-name> |
用于连接存储池的规则名称(参见 GUI 和 CLI) |
<root> |
它应该属于哪个 crush root(默认 ceph root 是 "default") |
<failure-domain> |
对象应该分布在哪个故障域(通常是主机) |
<class> |
要使用哪种类型的 OSD 后备存储(例如 nvme、ssd、hdd) |
一旦规则出现在 CRUSH map 中,您可以告知存储池使用该规则集。
ceph osd pool set <pool-name> crush_rule <rule-name>
|
|
如果存储池已包含对象,则必须相应地移动这些对象。根据您的设置,这可能会给您的集群产生很大的性能影响。作为替代方案,您可以创建一个新的存储池并单独移动磁盘。 |
按照前面部分的设置,您可以配置 Proxmox VE,使用这些存储池来存储 VM 和容器镜像。只需使用 GUI 添加新的 RBD 存储(请参阅 Ceph RADOS 块设备(RADOS Block Devices,简称 RBD) 部分)。
您还需要将 keyring 文件复制到外部 Ceph 集群的预定义位置。如果 Ceph 安装在当前 Proxmox 节点上,那么这将自动完成。
|
|
该文件名必须为 <storage_id> + .keyring,其中 <storage_id> 所表示的就是在 /etc/pve/storage.cfg 中的 rbd: 之后的值。在以下范例中,my-ceph-storage 是 <storage_id>: |
mkdir /etc/pve/priv/ceph cp /etc/ceph/ceph.client.admin.keyring /etc/pve/priv/ceph/my-ceph-storage.keyring
Ceph 还提供了一个文件系统,它运行在与 RADOS 块设备相同的对象存储上。一个元数据服务器(Metadata Server (简称 MDS) )用于将 RADOS 后备对象映像到文件和目录,允许 Ceph 提供符合 POSIX 的复制文件系统。这让您可以轻松配置一个集群的、高可用的、共享的文件系统。Ceph 的元数据服务器保证文件均匀分布在整个 Ceph 集群中。因此,即使是高负载的情况也不会压倒单个主机,这可能是传统共享文件系统方式的问题(例如 NFS)。
Proxmox VE 既支持创建一个超融合 CephFS,还支持使用现有 CephFS 作为存储来保存备份、ISO 文件和容器模板。
CephFS 至少需要配置并运行一个元数据服务器才能正常工作。您可以通过 Proxmox VE Web GUI 界面的 节点 -> CephFS 面板或从命令行使用以下命令创建 MDS:
pveceph mds create
可以在集群中创建多个元数据服务器,但在默认设置下,一次只能有一个活动的。如果一个 MSD 或它所在节点失去响应(或崩溃),另一个 备用 MSD 将被提升为 活动 状态。您可以在创建时使用 hotstandby 参数选项来加速主备 MDS 之间的切换,或者如果您已经创建了它,您可以在 /etc/pve/ceph.conf 中的相应 MDS 部分设置/添加:
mds standby replay = true
启用此功能后,指定的 MDS 将保持 warm(热机) 状态,轮询活动的 MDS,以便在出现任何问题时可以更快地接管。
|
|
此主动轮询将对您的系统和活动的 MDS 产生额外的性能影响。 |
从 Luminous (12.2.x) 开始,您可以同时运行多个活动的元数据服务器,但这通常只有在您有大量并行的客户端时才有用。否则 MDS 很少成为系统中的瓶颈。如果您想要设置它,请参考 Ceph 文档
[配置多个活动 MDS 守护进程 https://docs.ceph.com/en/nautilus/cephfs/multimds/]
。
CephFS 通过与 Proxmox VE 的集成,您可以使用 Web 界面、CLI 或外部 API 接口轻松创建 CephFS 。要使其工作,需要一些前提条件:
安装 Ceph 软件包 - 如果这已经在前期完成了,您可能需要在最新的系统上重新运行它,并确保所有与 CephFS 相关的软件包都已安装。
完成以后,您只需通过 Web GUI 的 节点 -> CephFS 面板或命令行工具 pveceph 创建一个 CephFS,例如:
pveceph fs create --pg_num 128 --add-storage
这是创建一个名 cephfs 的 CephFS,使用一个名为 cephfs_data 存储池(具有 128 个归置组),以及使用一个名为 cephfs_metadata 的元数据存储池(具有四分之一(32)个数据存储池的归置组)。查看 Proxmox VE 管理 Ceph 存储池章节 或访问 Ceph 文档,以获取有关适合您在设置归置组的数字(pg_num)时的更多信息
[placement_groups]
。此外,附加的 --add-storage 参数将会在成功创建 CephFS 后将其添加到 Proxmox VE 存储配置中。
|
|
销毁一个 CephFS 将使其所有数据无法使用。这无法撤消! |
要完全、优雅地删除一个 CephFS,需要执行以下步骤:
断开所有非 Proxmox VE 客户端的连接(例如,在来宾中卸载 CephFS)。
禁用所有与 CephFS 相关的 Proxmox VE 存储条目(防止它被自动挂载)。
从要销毁的 CephFS 上,移除来宾使用的所有资源(例如 ISO)。
通过以下命令,手动卸载所有集群节点上的 CephFS 存储
umount /mnt/pve/<STORAGE-NAME>
其中 <STORAGE-NAME> 是 Proxmox VE 中 CephFS 存储的名字。
现在通过停止或销毁,来确保该 CephFS 上没有元数据服务器(MDS)正在运行。这可以通过 Web 界面或通过命令行界面完成,对于后者,您可以发出以下命令来停止它们:
pveceph stop --service mds.NAME
或者使用:
pveceph mds destroy NAME
来销毁它们。
请注意,当活动的 MDS 停止或移除,备用服务器将被自动提升为活动状态,因此最好先停止所有备用的服务器。
现在您可以通过以下命令销毁 CephFS
pveceph fs destroy NAME --remove-storages --remove-pools
这将自动销毁底层 ceph 存储池并从 pve 配置中删除该存储。
在这些步骤之后,CephFS 应该被完全删除,如果您有其他 CephFS 实例,可以再次启动停止的元数据服务器作为备用服务器。
Ceph 中最常见的维护任务之一是更换 OSD 的磁盘。如果磁盘已经处于故障状态,那么您可以继续执行 销毁 OSD 中的步骤。如果可能,Ceph 将在剩余的 OSD 上重建这些副本。一旦检测到 OSD 发生故障或 OSD 被主动停止,将会启动这种重平衡。
|
|
存储池使用默认的 size/min_size (3/2),仅当“size + 1”个节点可用时才开始恢复。这样做的原因是该 Ceph 的对象平衡装置 CRUSH 默认将完整节点设置为“故障域”。 |
要通过 GUI 更换功能正常的磁盘,请执行 销毁 OSD 中的步骤。唯一的补充是等到集群显示 HEALTH_OK 后再停止 OSD 来销毁它。
在命令行中使用以下命令:
ceph osd out osd.<id>
您可以使用以下命令检查 OSD 是否已经安全移除。
ceph osd safe-to-destroy osd.<id>
一旦上述检查告诉您已安全移除 OSD,您可以继续执行以下命令:
systemctl stop ceph-osd@<id>.service pveceph osd destroy <id>
使用新磁盘替换旧磁盘,并使用与 创建 OSD 中所述的相同过程。
在 VM 和容器上定期运行 fstrim(discard)是一个很好的习惯。这会释放文件系统中不再使用的数据块。它减少了数据的使用和资源的负载。大多数现代操作系统会定期向它们的磁盘发出此类丢弃(discard)命令。您只需要确保虚拟机中启用了 磁盘的丢弃(discard)选项 。
Ceph 通过 清理(scrubbing) 归置组来确保数据的完整性。Ceph 检查 PG 中的每个对象的健康状况。有两种形式的清理,日常简易的元数据检查和每周的深度数据检查。每周的深度清理是通过读取对象并使用校验来确保数据的完整性。如果正在运行的清理干扰了业务(性能)需求,您可以调整执行清理
[Ceph 数据清理 https://docs.ceph.com/en/nautilus/rados/configuration/osd-config-ref/#scrubbing]
的时间。
从一开始就持续监视 Ceph 部署的健康状态非常重要,可以通过使用 Ceph 工具或通过 Proxmox VE 的 API 访问其状态。
下面的 Ceph 的命令可用于查看集群是否健康(HEALTH_OK),是否有警告(HEALTH_WARN),甚至是错误(HEALTH_ERR)。如果集群处于不健康状态,下面的状态命令还将为您提供当前事件和要采取操作的概述。
# single time output pve# ceph -s # continuously output status changes (press CTRL+C to stop) pve# ceph -w
为了获得更多详细的视图,每个 Ceph 服务在 /var/log/ceph/ 下都有一个日志文件。如果需要更多的细节,还可以调整日志
[Ceph 日志与调试 https://docs.ceph.com/en/nautilus/rados/troubleshooting/log-and-debug/]
的级别。
您可以在官方网站上找到有关 Ceph 集群故障排除
[Ceph 故障排除 https://docs.ceph.com/en/nautilus/rados/troubleshooting/]
的更多信息。
pvesr 命令行工具管理 Proxmox VE 存储复制框架。存储复制为使用本地存储的来宾提供冗余,并减少迁移时间
它将来宾卷复制到另一个节点,以便在不使用共享存储时可以使用所有数据。复制使用快照来最小化通过网络发送的流量。因此,新的数据仅在初始完全同步后以增量方式发送。在节点发生故障的情况下,您的来宾数据在已复制节点上仍然使用。
复制在可配置的时间间隔内自动完成。最小复制间隔为一分钟,最大复制间隔为每周一次。用于指定这些间隔的格式是 systemd 日历事件的一个子集,请参阅 日程格式 部分:
可以将一个来宾复制到多个目标节点,但是不能复制两次到同一个目标节点。
可以限制每个复制的带宽,以避免存储或服务器过载。
启用复制的来宾目前只能离线迁移。如果来宾迁移到它已经复制到的节点,则只需要传输自上次复制以来的更改(所谓的增量)。这大大减少了所需的时间。如果您将来宾迁移到复制目标节点,复制方向将自动切换。
例如:VM100 当前在 nodeA 上并被复制到 nodeB 。您将迁移到 nodeB,因此现在它会自动从 nodeB 复制回 nodeA 。
如果迁移到未复制来宾的节点,则必须发送整个磁盘数据,迁移之后,复制任务继续将此来宾复制到配置的节点。
|
|
允许将高可用性与存储复制结合使用,但在上次同步时间和节点故障时间之间可能会丢失一些数据。 |
| 描述 | PVE 类型 | 快照 | 稳定性 |
|---|---|---|---|
ZFS (local) |
zfspool |
yes |
yes |
复制使用 日历事件 来配置日程。
如果复制任务遇到问题,它会将处于错误状态。在此状态下,配置的复制间隔会暂时挂起,失败的复制会在 30 分钟的时间间隔内重复尝试。一旦成功,原来的日程将再次激活。
以下列表中列出了一些最常见的问题。根据您的设置,可能还有其他原因。
网络不工作。
复制目标存储上没有剩余可用空间。
目标节点上可用的具有相同存储 ID 的存储
|
|
您始终可以使用复制日志来找出导致问题的原因。 |
在出现严重错误的情况下,虚拟来宾可能会卡在故障节点上,然后,您需要再次手动将其移动到工作中的节点。
让我们假设有两个来宾(VM 100 和 CT 200)运行在节点 A 上,并复制到节点 B 。节点 A 发生故障并且无法重新联机。现在您必须手动迁移来宾到节点 B 。
通过 ssh 连接节点 B或者通过 WebUI 打开自带的 shell 。
检查集群是否合规
# pvecm status
如果没有的达到规定数量,我们强烈建议您首先解决此问题,并让节点再次可操作。仅当目前无法执行此操作时,您才可以使用以下命令强制执行仲裁:
# pvecm expected 1
|
|
如果不惜一切代价设置了 预期投票(例如添加/删除节点、存储、虚拟来宾),请避免影响到集群的更改。仅使用它来让重要的来宾重新启动并运行,或用于解决仲裁问题本身。 |
将两个来宾的配置文件从源节点 A 移动到节点 B:
# mv /etc/pve/nodes/A/qemu-server/100.conf /etc/pve/nodes/B/qemu-server/100.conf # mv /etc/pve/nodes/A/lxc/200.conf /etc/pve/nodes/B/lxc/200.conf
现在您可以再次启动来宾:
# qm start 100 # pct start 200
记住用各自的值替换 VMID 和节点名称。
您可以使用 web GUI 轻松地创建、修改和删除复制任务。此外,还可以使用命令行界面 (CLI) 工具 pvesr 来执行此操作。
您可以在 WEB GUI 中找到所有级别(数据中心、节点、虚拟来宾)的复制面板。它们的不同之处在于显示的任务:所有、特定的节点或来宾的任务。
添加新任务时,如果尚未选择,您需要指定来宾以及目标节点。如果不需要 所有 15 分钟 的默认值,则可以设置复制计划 。您可以对复制任务施加速度限制。速度限制有助手保持可接受的存储负载。
复制任务由集群范围内的唯一 ID 进行标识。除了任务编号之外,此 ID 还由 VMID 组成。如果使用 CLI 工具,则只能手动指定此 ID 。
给 ID 为 100 的客户机创建一个每 5 分钟运行的复制任务,带宽限制为 10Mbps(兆字节/每秒)。
# pvesr create-local-job 100-0 pve1 --schedule "*/5" --rate 10
禁用 ID 为 100-0 的活动任务。
# pvesr disable 100-0
启用 ID 为 100-0 的已停用任务。
# pvesr enable 100-0
将 ID 为 100-0 的任务的计划间隔更改为每小时一次。
# pvesr update 100-0 --schedule '*/00'
Qemu(Quick Emulator 的缩写)是一个模拟物理计算机的开源虚拟机管理程序。从运行 Qemu 的主机系统的角度来看,Qemu 是一个用户程序,它可以访问大量本地资源,像分区、文件、网卡等,然后将这些资源传递给模拟计算机,模拟计算机则将这些资源视为真实的设备。
运行在模拟计算机里的来宾操作系统,在访问这些设备时就像运行在真实硬件上一样。例如,您可以将 ISO 映像作为参数传递给 Qemu,在模拟计算机中运行的操作系统,将会看到一个真正的 CD-ROM 光盘插入到 CD 驱动器中。
Qemu 可以模拟从 ARM 到 Sparc 的各种硬件,但是,Proxmox VE 仅涉及 32位 和 64 位 PC 的克隆模拟,因为它代表了绝大多数的服务器硬件。由于处理器扩展的可用性,PC 克隆的模拟也是最快的,当模拟的架构与主机架构相同时,也极大的加速了 Qemu 。
|
|
您有时可能会遇到术语 KVM(即:Kernel-based Virtual Machine,基于内核的虚拟机)。这意味着 Qemu 是通过 Linux KVM 模块在虚拟化处理器扩展的支持下运行的。在 Proxmox VE 的运行环境中,Qemu 和 KVM 可以互换使用,因为 Proxmox VE 中的 Qemu 将始终尝试加载 KVM 模块。 |
Proxmox VE 内的 Qemu 运行在 root 进程上,这是访问块(block)与 PCI 设备所必需的。
Qemu 模拟的 PC 硬件包括主板、网络控制器、SCSI、IDE 和 SATA 控制器、串口(完整列表可以详见 kvm(1) 手册页),所以这些均可在软件中进行模拟。所有这些设备都与现有硬件设备使用完全相同的软件,如果在来宾系统中运行的操作系统使用恰当的驱动程序,它将像运行在真实硬件上一样使用这些设备。这允许 Qemu 运行 无须修改 的操作系统。
然而这仍会有性能损失,毕竟使用软件运行本应在硬件中运行的内容会给主机 CPU 增加很多额外的工作。为了缓解这种情况,Qemu 可以向来宾操作系统呈现 半虚拟化设备,让对应的来宾操作系统识别到它正在 Qemnu 内部运行,并与虚拟机管理器协作。
Qemu 依赖于 virtio 虚拟化标准,因此能够提供半虚拟化的 virtio 设置,包括半虚拟化的通用磁盘控制器、半虚拟化的网卡、半虚拟化的串口、半虚拟化的 SCSI 控制器等等。
强烈建议您尽可能使用 virtio 设备,因为它们提供了很大的性能改善。使用 virtio 通用磁盘控制器与模拟的 IDE 控制器相比,顺序写入吞吐量将增加一倍,使用 bonnie++(8) 所测得的。使用 virtio 网络接口可以提供比模拟的 Intel E1000 网卡高达三倍的吞吐量,使用 iperf(1)
[在 KVM wiki 上查看此基准测试 https://www.linux-kvm.org/page/Using_VirtIO_NIC]
所测得的。
一般说来,Proxmox VE 尝试为虚拟机 (VM) 选择合理的默认值。请确保您理解所更改设置的含义,这可能会导致性能下降,或让您的数据面临风险。
虚拟机 (VM) 的常规设置包括:
节点:运行 VM 的物理服务器
VM ID:用于标识在此 Proxmox VE 中安装的 VM 的唯一编号
名称:用于描述 VM 的任意格式的文本
资源池: VM 的逻辑群组
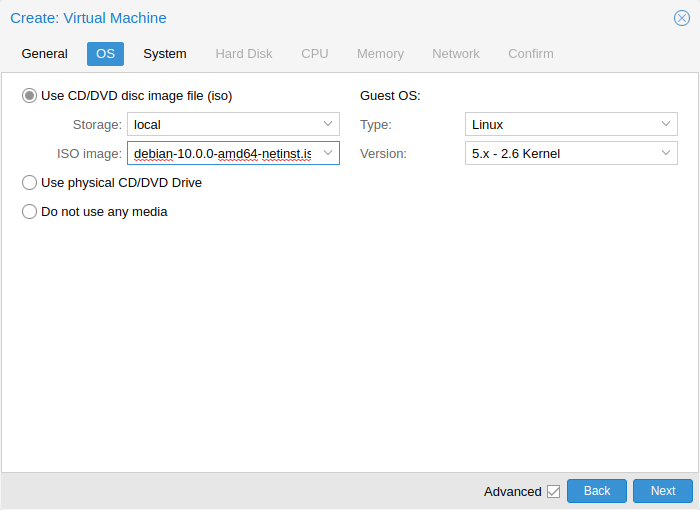
创建虚拟机(VM)时,允许 Proxmox VE 通过优化部分底层参数来设置适当的操作系统(OS)。例如,Windows 操作系统要求 BIOS 时钟使用本地时间,而基于 Unix 的操作系统要求 BIOS 时钟使用 UTC 时间。
在创建 VM 时,您可以更改新的 VM 的一些基本系统组件。可以指定要使用的的显示类型。
此外,还可以更改 SCSI 控制器 。如果您计划安装 QEMU Guest Agent(来宾代理),或如果您所选的 ISO 映像已装入并自动安装,您可能需要勾选 Qemu Agent 选项框,让 Proxmox VE 知道它可以使用其功能来显示更多信息,并更智能地完成某些操作(例如,关机或快照)。
Proxmox VE 允许使用不同的固件和机器类型(即 SeaBIOS 和 OVMF)启动 VM 。在多数情况下,仅当您计划使用 PCIe 直通 时,才需要从默认的 SeaBIOS 切换到 OVMF 。VM 的 机器类型 定义了 VM 的虚拟主板的硬件布局。您可以在默认的 Intel 440FX 或 Q35 芯片组之间进行选择,Q35 芯片组还提供了虚拟 PCIe 总线,因此,如果需要直通 PCIe 硬件,则可能需要该总线。
Qemu 可以模拟多种存储控制器:
IDE 控制器,其设计可追溯到 1984 年的 PC/AT 磁盘控制器。即使这个控制器已经被最新的设计所取代,您可以想到的每一个操作系统都支持它,如果您想运行 2003 年之前发布的操作系统,它也是一个不错的选择。此控制器上最多可以连接 4 个设备。
SATA (串行 ATA) 控制器,始于 2003 年,具有更现代的设计,允许更高的吞吐量和更多的设备连接。此控制器上最多可以连接 6 个设备。
SCSI 控制器,1985 年设计,常见于服务器级别硬件上,最多可连接 14 个存储设备。Proxmox VE 默认模拟 LSI 53C895A 控制器。
如果您以性能为目标,从 Proxmox VE 4.3 开始为新建的 Linux VM 自动选择 VirtIO SCSI 类型的 SCSI 控制器(推荐设置)。Linux 发行版从 2012 年开始支持该控制器,而 FreeBSD 从 2014 年开始。对于 Windows 操作系统,您需要在安装过程中额外提供包含驱动程序的 ISO 。如果您以最大性能为目标,则可以选择 VirtIO SCSI single 类型的SCSI控制器,该控制器允许您选择 IO Thread 选项。当选择 VirtIO SCSI single 时,Qemu 将为每个磁盘创建一个新的控制器,而不是将所有磁盘添加到同一个控制器。
VirtIO Block 控制器,通常称为 VirtIO 或 virtio-blk,是一种较旧的半虚拟化控制器。就功能而言,它已被 VirtIO SCSI 控制器取代。
在每个控制器上,您连接了许多模拟的硬盘,这些硬盘由驻留在已配置存储中的文件或块设备支持。存储类型的选择将决定了硬盘映像的格式。目前块设备(LVM、ZFS、Ceph)的存储需要 raw 磁盘映像格式,而基于文件的存储(Ext4、NFS、CIFS、GlusterFS)将允许您选择 raw 磁盘映像格式 或者 QEMU 映像格式 。
QEMU 映像格式 是一种写时复制格式,它允许快照和磁盘映像的自动精简配置。
raw 磁盘映像 是一种硬盘的逐位(bit-to-bit)映像,类似于在 Linux 系统中的块设备上执行 dd 命令时得到的映像。这种格式自身不支持自动精简配置或快照,需要存储层的配合才能完成这些任务。然而,它可能比 QEMU 映像格式 快10%
[更多细节请参阅该基准测试 https://events.static.linuxfound.org/sites/events/files/slides/CloudOpen2013_Khoa_Huynh_v3.pdf]
。
VMware 映像格式 仅在您打算将磁盘映像导入/导出到其他虚拟机管理程序时才有意义。
设置硬盘驱动器的 缓存 模式将影响到主机系统如何通知块写入完成的来宾系统。无缓存 意味着默认情况下,当每个块忽略主机的页面缓存而到达物理存储的写入队列时,来宾系统将会收到写入完成的通知。这在安全性和速度之间提供了良好的平衡。
如果您希望 Proxmox VE 备份管理器在备份 VM 时跳过磁盘,您可以在该磁盘上设定 不备份 选项。
如果您希望 Proxmox VE 存储复制机制在启动复制作业时跳过磁盘,您可以在该磁盘上设定 跳过复制 选项。从 Proxmox VE 5.0 开始,复制要求磁盘映像位于 zfspool 类型的存储上,因此,当 VM 配置了复制时,将磁盘映像添加到其他存储需要跳过此磁盘映像的复制。
如果您的存储支持 自动精简配置(thin provisioning)(请参阅 Proxmox VE 指南中的存储章节),您可以激活驱动器上的 丢弃(Discard) 选项。使用 丢弃(Discard) 设定和启用 TRIM 的来宾操作系统
[TRIM、UNMAP 和 discard https://en.wikipedia.org/wiki/Trim_%28computing%29]
,当 VM 的文件系统在删除文件后将块标记为未使用时,控制器会将信息转发给存储,然后存储会相应地收缩磁盘映像。为了让来宾能够发出 TRIM 命令,您必须在驱动器上启用 丢弃(Discard) 选项。某些来宾操作系统可能还需要设定 SSD 仿真 标志。请注意,只有使用 Linux 内核 5.0 或更高版本的来宾上支持 VirtIO Block 驱动器使用 丢弃(Discard) 选项。
如果您希望呈现给来宾的驱动器是固态驱动器,而不是机械硬盘,您可以在该驱动器上设定 SSD 仿真 选项。不要求底层存储实际上是否有 SSD 支持;此功能可用于任何类型的物理媒体。请注意,VirtIO Block 驱动器不支持 SSD 仿真。
IO Thread(IO 线程) 选项只能用于使用带有 VirtIO 控制器的磁盘,或者在模拟的控制器类型为 VirtIO SCSI single 时,使用带有 SCSI 控制器的磁盘。启用此选项后,Qemu 会为每个存储控制器创建一个 I/O 线程,而不是为所以 I/O 创建单个线程。当多个磁盘都使用每个磁盘自己的存储控制器时,可以提高性能。
CPU 插槽 是 PC 主板上的一个可以用来插入 CPU 的物理插槽。然后,该 CPU 包含一个或多个 核心,这些核心都是独立的处理单元。从性能的角度来看,无论是单个 4 核心的 CPU 插槽,还是两个 2 核心的 CPU 插槽,几乎都无关紧要。但是,某些软件的许可证取决于机器拥有的插槽数,在这种情况下,将插槽数量设置为许可证允许的数量是有意义的。
增加虚拟 CPU(核心和插槽)的数量通常会提高性能,尽管这在很大程度上取决于 VM 的使用。当然,多线程应用程序会受益于大量的虚拟 CPU,对于您添加的每个虚拟 CPU,Qemu 将在主机系统上创建一个新的执行线程。如果您不确定您的 VM 的工作负载,通常将 核心总数 的数量设置为 2 是个保险的设定。
|
|
如果所以 VM 上的核心的总数大于服务器上的核心数(例如,在只有 8 个核心的机器上,有 4 台 VM ,每个 VM 都有 4 个核心),这是完全安全的。在这种情况下,主机系统将会平衡服务器核心之间的 Qemu 执行线程,就像您在运行标准的多线程应用程序一样。但是,Proxmox VE 会阻止您启动虚拟 CPU 核心数多于物理可用核心数的 VM ,由于环境切换的代价,这只会降低性能。 |
除了虚拟核心的数量之外,您还可以根据主机 CPU 时间和其他虚拟机的关系来配置一台 VM 可以获得多少资源。通过使用 CPU 限制(cpulimit) (“主机 CPU 时间”)选项,您可以限制整个 VM 在主机上可以使用的 CPU 时间。它是一个以百分比表示 CPU 时间的浮点值,因此 1.0 等于 100%,2.5 等于 250%,以此类推。如果单个进程想要完全使用一个单核心,则 CPU 时间的使用率为 100% 。如果有四个核心的 VM 充分利用所有核心,则理论上将使用 400% 。实际上,使用率甚至可能更高一些,因为除了 vCPU 核心线程之外,Qemu 还为 VM 的外围设备提供了额外的线程。如果一个 VM 可以有多个 vCPU,则此设置很有用,因为它可以并行运行几个进程,但整个 VM 不可能在同一时间以 100% 运行所有的 vCPU。举一个具体的范例:假设我们有一个 VM ,它可以从拥有的 8 个 vCPU 中受益,但是这 8 个核心在任何时间都不应该全负载运行——因为这会导致服务器过载,以至于其他 VM 和 CT 的 CPU 都会更少。因此,我们将 CPU 限制(cpulimit) 限制设定为 4.0 (=400%)。如果所有核心执行繁重的工作,它们都将获得 50% 的真实主机核心的 CPU 时间。但是,如果只有 4 个可以工作,它们每个仍然可以获得几乎 100% 的真实核心。
|
|
VM 可以根据它们的配置,使用额外的线程,例如用于网络或 IO 操作以及实时迁移。因此,VM 看起来可能比它的虚拟 CPU 要使用更多的 CPU 时间。要确保 VM 使用的 CPU 时间永远不会超过分配的虚拟 CPU,请将 CPU 限制(cpulimit) 设定的值设置为与核心总数相同的值。 |
这第二个 CPU 资源限制设置 CPU 权重(cpuunits)(现在通常称为 CPU 份额或者 CPU 权重),用于控制 VM 相对于其他正在运行的 VM 获得的 CPU 时间。它是一个相对的权重,默认值为 1024,如果您增加一台 VM 的权重,与其他权重较低的 VM 相比,调度程序将优先处理该 VM 。例如,如果 VM 100 设置了默认的 1024 并且 VM 更改为 2048,则后面的 VM 200 将获得两倍于第一个 VM 100 的 CPU 宽带。
了解更多信息请参阅 man systemd.resource-control,这里的 CPUQuota 对应 CPU 限制(cpulimit),而 CPUShares 对应于我们的 CPU 权重(cpuunits)设置,请访问其注释部分以获取参考和实现细节。
Qemu 可以模拟从 486 到最新的 Xeon 处理器的多种不同 CPU 类别。每代新处理器都会增加新特性,例如硬件 3D 渲染、随机数生成、内存保护等等。通常,您应该为您的 VM 选择与主机系统的 CPU 非常匹配的处理器类别,这意味着主机 CPU 的特性(也称为 CPU flags(标志))也可用于您的 VM 。如果您要完全匹配,您可以将 CPU 类型设置为 host(主机),在这种情况下,VM 将具有与您的主机系统完全相同的 CPU flags(标志)。
但这也有不利的一面,如果您想要在不同的主机之间实时迁移 VM ,那么您的 VM 可能最后会出现在不同 CPU 类别的新系统上。如果传递给来宾的 CPU flags 丢失,qemu 进程将会停止。为了解决这个问题,Qemu 也有自己的 CPU 类别 kvm64,Proxmox VE 默认使用它。kvm64 是与 Pentium 4 看起来很相似的 CPU 类别,它被设置为减少 CPU flags,但保证可以在任何地方工作。
简而言之,如果您关心节点之间的实时迁移和移动 VM ,请保留 kvm64 为默认。如果您不关心实时迁移,或者拥有一个所有节点具有相同 CPU的同构集群,请将 CPU 类别设置为 host(主机),从理论上说,这将为您的来宾提供最大的性能。
您可以使用一组可配置的特性来指定自定义的 CPU 类别。这些由管理员在配置文件 /etc/pve/virtual-guest/cpu-models.conf 中维护。了解格式详细信息,请参阅 man cpu-models.conf 。
任何在 /nodes 上具有 Sys.Audit 权限的用户都可以选择特定的自定义类型。当通过 CLI 或 API 为 VM 配置一个自定义 CPU 类别时,名称需要以 custom- 作为前缀。
有几个与Meltdown(熔断)和 Spectre(幽灵)漏洞
[熔断攻击 https://meltdownattack.com/]
相关的 CPU flags 需要手动设置,除非您的虚拟机所选择的 CPU 类别已经默认启用它们。
要使用这些 CPU flags,需要满足两个要求:
主机的 CPU 必须支持此特性并将其传播到来宾的虚拟 CPU
来宾的操作系统必须更新到可以缓和攻击并能够利用 CPU 特性的版本
否则,您需要通过在 Web 界面中编辑 CPU 选项,或者通过在 VM 配置文件中设置 cpu 选项的 flags 属性,来设置虚拟 CPU 所需的 CPU flag 。
针对 Spectre v1、v2、v4 的修复,您的 CPU 或系统供应商也需要为您的 CPU 提供所谓的“微代码更新(microcode update)”
[如果供应商不提供此类更新,您可以使用 Debian non-free 的“intel-microcode”/“amd-microcode”。请注意,并非所有受影响的 CPU 都能更新以支持 spec-ctrl。]
。
要检查 Proxmox VE 主机是否易受攻击,以 root 身份运行以下命令:
for f in /sys/devices/system/cpu/vulnerabilities/*; do echo "${f##*/} -" $(cat "$f"); done
社区脚本也可用于检测主机是否仍然易受攻击。
[spectre-meltdown-checker https://meltdown.ovh/]
pcid
这降低了称为 内核页表隔离(KPTI) 的 Meltdown (CVE-2017-5754) 缓解措施对性能的影响,它有效地对用户空间隐藏了内核内存。没有 PCID,KPTI 是一种相当昂贵的机制
[PCID 现在是 x86 上的一项关键性能/安全特性 https://groups.google.com/forum/m/#!topic/mechanical-sympathy/L9mHTbeQLNU]
。
要检查 Proxmox VE 主机是否支持 PCID,以 root 身份执行以下命令:
# grep ' pcid ' /proc/cpuinfo
如果返回不为空,则说明您的主机的 CPU 支持 pcid 。
spec-ctrl
在 retpolines 不够用的情况下,需要启用 Spectre v1 (CVE-2017-5753) 和 Spectre v2 (CVE-2017-5715) 修复。默认已经包含在型号中带有 -IBRS 后缀的 Intel CPU 中。必须为型号中没有带 -IBRS 后缀的 Intel CPU 显式开启。需要更新主机 CPU 微代码(intel-microcode >= 20180425)。
ssbd
需要启用 Spectre V4 (CVE-2018-3639) 修复。默认情况下未包含在任何型号的 Intel CPU 中。必须为所有型号的 Intel CPU 显式开启。需要更新主机 CPU 的微代码(intel-microcode >= 20180703)。
ibpb
在 retpolines 不够用的情况下,需要启用 Spectre v1 (CVE-2017-5753) 和 Spectre v2 (CVE-2017-5715) 修复。默认已包含在型号中带有 -IBPB 后缀的 AMD CPU 中。必须为型号中没有带 -IBPB 后缀的 AMD CPU 显式开启。需要主机 CPU 的微代码支持该特性,它才能用于来宾 CPU 。
virt-ssbd
需要启用 Spectre v4 (CVE-2018-3639) 修复。默认情况下未包含在任何型号的 AMD CPU 中。必须为所有型号的 AMD CPU 显式开启。即使提供了 amd-ssbd,也应该将该特性提供给来宾,以实现最大的来宾兼容性。请注意,当使用的 CPU 类型为“host”时必须显式启用该特性,因为物理 CPU 中不存在此虚拟特性。
amd-ssbd
需要启用 Spectre v4 (CVE-2018-3639) 修复。默认情况下未包含在任何型号的 AMD CPU 中。必须为所有型号的 AMD CPU 显式开启。这提供了比 virt-ssbd 更高的性能,如有可能,支持该特性的主机应该始终将其公开给来宾。virt-ssbd 也应该公开以获得最大的来宾兼容性,因为部分内核只知道 amd-ssbd。
amd-no-ssb
建议指示主机不易受到 Spectre V4 (CVE-2018-3639) 的攻击。默认情况下未包含在任何型号的 AMD CPU 中。未来硬件迭代的 CPU 将不会受到 CVE-2018-3639 的攻击,因此应告知来宾不要通过暴露 amd-no-ssb 来启用其缓解措施。这与 virt-ssbd 和 amd-ssbd 是互斥的。
您还可以选择在 VM 中模拟 NUMA
[https://en.wikipedia.org/wiki/Non-uniform_memory_access]
架构。NUMA 架构的基本原理是,不是让所有核心都可以使用全局内存池,而是将内存分布到靠近每个插槽的本地存储区中。这可以带来速度提升,因为内存总线不再是瓶颈。如果您的系统具有 NUMA 架构
[如果命令 numactl --hardware | grep available 返回不止一个节点,则您的主机系统具有 NUMA 架构]
,我们建议激活该选项,因为这将允许在主机系统上正确分配 VM 资源。在 VM 中热插拔核心或内存时也需要该选项。
如果已使用 NUMA 选项,建议将插槽的数字设定为主机系统的节点数。
现代操作系统引入了热插拔功能,并在一定程度上可以在运行的系统中热拔出 CPU。虚拟化允许我们避免在这种情况下真实硬件可能导致的许多(物理)问题。尽管如此,这是一个相当新的且复杂的特性,因此它的使用应仅限于绝对需要的情况。大多数功能可以与其他经过良好测试且不太复杂的特性一起复制,请参阅 资源限制 。
在 Proxmox VE 中,插入的 CPU 的最大数量总是 核心数 * 插槽数。要启动少于此 CPU 的核心总数的 VM ,您可以使用 vpus 设置,它表示在 VM 启动时应插入多少个 vCPU 。
目前仅 Linux 支持此功能,需要 3.10 以上的内核,推荐 4.7 以上的内核。
您可以使用以下 udev 规则,在来宾中以在线方式自动设置新 CPU:
SUBSYSTEM=="cpu", ACTION=="add", TEST=="online", ATTR{online}=="0", ATTR{online}="1"将其保存在 /etc/udev/rules.d/ 下,以 .rules 结尾的文件。
注意:CPU 热移除(hot-remove)依赖于机器并需要来宾配合。此删除命令不保证 CPU 可以真正移除,通常使用目标依赖机制转发它的请求给来宾,例如 x86/amd64 上的 ACPI 。
对于每台 VM ,您可以设置为固定大小的内存,或要求 Proxmox VE 根据主机当前内存的使用情况动态分配内存。
当设置的内存和最小内存为相同的数量时,Proxmox VE 将指定的内存直接分配给您的 VM 。
即使使用固定内存大小,Ballooning 设备(一种虚拟设备)也会被添加到 VM ,因为它提供有用的信息,例如来宾实际使用了多少内存。通常情况下,您应该保持 ballooning 为启用状态,但是如果您想要禁用它(例如,用于调试),只需取消选中 Ballooning 设备 或在配置中设置:
balloon: 0
当设置的最小内存低于内存时,Proxmox VE 将确保您为 VM 指定的最小数量始终可用,并且如果在当前主机上的内存使用率低于 80%,将为来宾动态添加内存,直到指定的最大内存。
当主机的运行内存不足时,VM 将释放一些内存回主机,在需要时交换正在运行的进程,最后采取 oom killer 机制。主机和来宾之间的内存传递是通过来宾内部运行的特殊 balloon 内核驱动程序完成的,该驱动程序将从主机获取或释放内存页。
[可以在这里找到对 balloon 驱动程序内部工作原理的一个很好的解释 https://rwmj.wordpress.com/2010/07/17/virtio-balloon/]
当多个 VM 使用自动分配功能时,可以设置一个 共享 系数,该系数指示每个 VM 应占用的可用主机内存的相对值。例如,假设您有 4 个 VM ,其中 3 个运行 HTTP 服务器,最后一个是数据库服务器。为了在数据库服务器的内存中缓存更多的数据块,您希望空闲的内存在可用时优先考虑数据库 VM 。为此,您将给数据库 VM 分配一个 3000 的共享属性,将其他 VM 的共享保留为 1000 的默认设置。主机服务器有 32GB 的内存,目前正在使用 16GB,剩下 32 * 80/100 - 16 = 9GB 的内存分配给 VM 。数据库 VM 将获得 9 * 3000 / (3000 + 1000 + 1000 + 1000) = 4.5GB 额外内存,每个 HTTP 服务器将获得 1.5GB 。
2010 年以后发布的所有 Linux 发行版都包含 balloon 内核驱动。对于 Windows 操作系统,Balloon 驱动需要手动添加,并可能会导致来宾速度变慢,因此我们不推荐在关键系统上使用它。
为您的 VM 分配内存时,一个好的经验法则是始终为主机保留 1GB 的可用内存。
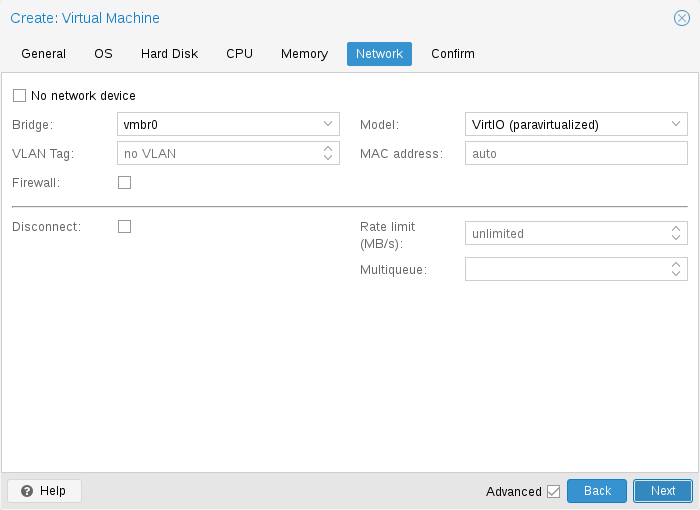
每个 VM 可以有四种不同类型的 网络接口控制器 (NIC):
Intel E1000 是默认值,模拟的是 Intel 千兆网卡。
如果您的目标是获得最高性能,则应该使用 VirtIO 半虚拟化网卡。像所有 VirtIO 设备一样,来宾操作系统应该安装了正确的驱动程序。
Realtek 8139 模拟较旧的 100MB/s(百兆)网卡,仅在模拟较旧的操作系统(2002年前发布的)时使用。
vmxnet3 是另一种半虚拟化的设备,仅在从另一个虚拟机管理程序导入 VM 时使用。
Proxmox VE 将为每个网卡生成一个随机的 MAC 地址,以便您的虚拟机可在以太网网络上寻址。
您添加到 VM 的网卡可以选择以下两种不同的模式中的一种:
在默认的 桥接模式(Bridged mode)下,每个虚拟网卡都由主机上的 tap 设备(模拟以太网网卡的软件环回设备)提供支持。这个 tap 设备被添加到一个网桥,在 Proxmox VE 中默认为 vmbr0 。在这种模式下,VM 可以直接访问主机所在的以太网局域网。
在备用的 NAT 模式下,每个虚拟网卡将仅与 Qemu 用户网络堆栈通信,其中内置的路由器和 DHCP 服务器可以提供网络访问。此内置的 DHCP 将为私有 10.0.2.0/24 网段内的地址提供服务。NAT 模式比桥接模式慢得多,只能用于测试。此模式仅可通过 CLI 或 API 使用,而不能通过 Web 界面使用。
您还可以在创建 VM 时通过选择 无网络设备 跳过添加网络设备。
如果您使用 VirtIO 驱动程序,您可以选择激活 Multiqueue 选项。此选项允许来宾操作系统使用多个虚拟 CPU 处理网络数据包,从而增加传输的数据包总数。
在 Proxmox VE 中使用 VirtIO 驱动程序时,每个网卡网络队列都将传递到主机内核,在主机内核中,队列将由 vhost 驱动程序产生的内核线程处理。激活此选项后,可以将 多个 网络队列传递给每个网卡的主机内核。
使用 Multiqueue 时,建议将其的值设置与来宾的核心总数相等的数字。您还需要使用 ethtool 命令在 VM 中设置每个 VirtIO 网卡上的多用途通道数:
ethtool -L ens1 combined X
其中 X 是 VM 的 vcpus 数量。
您应该注意,将 Multiqueue 参数设置为大于 1 的值,会随着数据流量的增加而增加主机和来宾系统上的 CPU 负载。我们建议仅当 VM 必须处理大量传入连接时才设置此选项,例如当 VM 作为路由器、反向代理或繁忙的 HTTP 服务器执行长轮询时。
QEMU 可以虚拟化多种类型的 VGA 硬件。部分范例是:
std,默认情况下,模拟带有 Bochs VBE 扩展的卡。
cirrus,这曾经是默认设置,它模拟了一个非常旧的硬件模块及其所有问题。只有在真正需要
[https://www.kraxel.org/blog/2014/10/qemu-using-cirrus-considered-harmful/ qemu: using cirrus considered harmful]
时才应该使用此显示类型,例如,如果使用 Windows XP 或更早版本。
vmware,是一个兼容 VMWare SVGA-II 的适配器。
qxl,是 QXL 半虚拟化的显卡。选择此项还会为 VM 启用 SPICE(一种远程查看器协议)。
您可以通过设置 内存 选项来编辑分配给虚拟 GPU 的内存数量。这可以在 VM 内实现更高的分辨率,尤其是使用 SPICE 或 QXL 。
由于内存是由显示设备保留的,因此为 SPICE(例如,用于双显示器的 qxl2)选择多显示器模式有一些影响:
Windows 需要为每个显示器配备一个设备,因此如果您的 OS 类型 是某个版本的 Windows,Proxmox VE 会为 VM 提供一个额外的设备,每个设备都获得指定数量的内存。
Linux VM 始终可以启用更多的虚拟显示器,但是选择一个多显示器模式会将提供给设备的内存乘以显示器的数量。
选择 serialX 作为显示 类型 会禁用 VGA 输出,并将 Web 控制台重定向到选定的串口。在这种情况下,配置的显示 内存 设定将被忽略。
有两种不同类型的 USB 直通设备:
主机 USB 直通
SPICE USB 直通
主机 USB 直通的作用是为 VM 提供主机的 USB 设备。这可以通过供应商和产品 ID 完成,也可以通过主机总线和端口完成。
供应商/产品 ID 类似于:0123:abcd,其中 0123 是供应商的 ID,abcd 是产品的 ID,这意味着同一个 USB 设备的两个部件有相同的 ID 。
总线/端口类似于:1-2.3.4,其中 1 是总线,2.3.4 是端口路径。这代表主机的物理端口(取决于 USB 控制器的内部顺序)。
如果 VM 启动一个 VM 配置中存在的设备时,但是主机中不存在该设备,则 VM 可以毫无问题地启动。一旦该设备/端口在主机中可用,它就会传递直通过去。
|
|
使用这种 USB 直通意味着您无法在线移动一台 VM 到另一个主机,因为硬件仅在 VM 当前所在的主机上可用。 |
SPICE USB 直通作为直通的第二类型,如果您使用支持它的 SPICE 客户端,这将非常有用。比如可以通过 SPICE 客户端,为 VM 添加一个 SPICE USB 端口,把所在位置的 USB 设备(例如,输入设备或硬件加密狗)直通到虚拟机。
为了正确的模拟计算机,QEMU 需要使用固件,在那些普通 PC 上则是众所周知的 BIOS 或 (U)EFI。这是启动 VM 的第一步,它负责进行基本的硬件初始化,并为操作系统提供固件和硬件的接口。默认情况下,QEMU 使用 SeaBIOS,它是一个开源的 x86 BIOS 实现。SeaBIOS 是大多数标准设置的不错选择。
某些操作系统(例如 Windows 11)可能需要使用 UEFI 兼容实现代替,在这种情况下,您必须使用 OVMF,这是一个开源 UEFI 实现。
[查看 OVMF 项目 https://github.com/tianocore/tianocore.github.io/wiki/OVMF]
在其他情况下,BIOS 并不是一个好的启动固件,例如,如果您要做 VGA 直通。
[关于这些的 Alex Williamson 博客 https://vfio.blogspot.co.at/2014/08/primary-graphics-assignment-without-vga.html]
如果要使用 OVMF,需要考虑以下几点:
为了保存像 引导顺序 之类的内容,需要有一个 EFI 磁盘。该磁盘将包含在备份和快照中,并且只能有一个。
您可以使用以下命令创建这样的磁盘:
# qm set <vmid> -efidisk0 <storage>:1,format=<format>,efitype=4m,pre-enrolled-keys=1
其中 <storage> 是要放置磁盘的存储,<format> 是存储支持的格式。或者,您可以通过 Web 界面,硬件 部分的 添加 → EFI 磁盘,创建这样的磁盘。
efitype 选项指定应该使用哪个版本的 OVMF 固件。对于新的 VM ,这应该始终是 4m,因为它支持安全启动,并且分配了更多空间来支持未来的开发(这是 GUI 中的默认值)。
pre-enroll-keys(预注册密钥)指定 efidisk(EFI 磁盘)是否应该预加载特定于发行版的密钥和 Microsoft 标准安全启动密钥。它默认还启用安全启动(尽管它仍然可以在虚拟机的 OVMF 菜单中禁用)。
|
|
如果要在现有 VM (仍使用 2m efidisk)中开始使用安全启动,则需要重新创建 efidisk。为此,删除旧的(qm set <vmid> -delete efidisk0)并添加一个新的如上所述的 EFI 磁盘。这将重置您在 OVMF 菜单中所做的任何自定义配置! |
当 OVMF 与虚拟显示器 (无 VGA 直通)一起使用时,您需要在 OVMF 菜单中设置客户端分辨率(在引导过程中按下 ESC 按钮即可完成),或您必须选择 SPICE 作为显示类型。
可信平台模块(TPM)是一种可安全存储机密数据(例如加密密钥),同时为验证系统启动提供防篡改功能的设备。
某些操作系统(例如 Windows 11)要求将此类设置连接到机器(无论是物理的还虚拟的)。
通过指定 tpmstate(TPM 状态)卷来添加 TPM 。这与 efidisk 的工作原理类似,因为它一旦创建就无法更改(只能删除)。您可以通过以下命令添加一个:
# qm set <vmid> -tpmstate0 <storage>:1,version=<version>
其中 <storage> 是您想要将状态置于其上的存储,<version>可以是 v1.2 或 v2.0 。您还可以通过 Web 界面添加一个,方法是在 VM 的 硬件 部分中选择 添加 → TPM 状态 。
TPM v2.0 的规范更新并且得到更好的支持,因此,除非您有特定的实现需要 TPM v1.2,否则应该首先 TPM v2.0 。
|
|
对比物理 TPM,模拟的 TPM 不提供 任何真正的安全优势。TPM 的重点是其上的数据不能轻易修改,除非通过 TPM 规范指定的部分命令。由于使用模拟设备,数据存储发生在常规卷上,因此任何有权访问它的人都可能对其进行编辑。 |
您可以添加一个虚拟机间(Inter-VM)共享内存设备(ivshmem),它允许在一个主机和一个来宾之间,或者和多个来宾之间共享内存。
要添加此类设备,您可以使用 qm:
# qm set <vmid> -ivshmem size=32,name=foo
其中的 size 单位是 MB ,该文件将位于 /dev/shm/pve-shm-$name(name 默认是 vmid)。
|
|
目前,只要使用该设备的任何 VM 关机或停止,它就会被删除。打开的连接将仍然存在,但是无法再与完全相同的设备建立新的连接。 |
这种设备的一个用例是 Looking Glass 项目
[Looking Glass: https://looking-glass.io/]
,它可以在主机和来宾之间实现高性能、低延迟的显示镜像。
运行以下命令添加音频设备:
qm set <vmid> -audio0 device=<device>
支持的音频设备包括:
ich9-intel-hda:Intel HD 音频控制器,模拟 ICH9
intel-hda:Intel HD 音频控制器,模拟 ICH6
AC97:音频编解码器(AC'97),适用于 Windows XP 等较旧的操作系统
有两个后端可用:
spice
none(无,虚拟设备)
RNG(Random Number Generator,随机数生成器)是一种为系统提供熵(随机性)的设备 。虚拟的 RNG 硬件可用于从主机系统向来宾 VM 提供此类熵。这有助于避免来宾中的熵饥饿(entropy starvation)问题(一种没有足够的熵可用并且系统可能变慢或遇到问题的情况),尤其是在来宾引导过程中。
要添加基于 VirtIO 的模拟 RNG,请运行以下命令:
qm set <vmid> -rng0 source=<source>[,max_bytes=X,period=Y]
source 指定从主机上读取熵的位置,并且必须是以下之一:
/dev/urandom:非阻塞内核熵源(首选)
/dev/random:阻塞内核源(不推荐,会导致主机系统熵饥饿(entropy starvation))
/dev/hwrng:连接到直通主机的硬件 RNG(如果有多个可用,将在 /sys/devices/virtual/misc/hw_random/rng_current 中选一个使用)
可以通过 max_bytes(最大字节) 和 period(周期)参数指定限制,它们以毫秒为单位在每个 period(周期)读取的 max_bytes(最大字节)(翻译注:字节/周期)。然而,它并不代表一种线性关系:1024B/1000ms 意味着在 1 秒的计时器上有最多 1KB 的数据可用,而不到是在 1 秒钟内将 1KB 流动到来宾。因此,减少 period(周期)可用于以更快的速度向来宾增加熵。
默认情况下,该限制是设定为每 1000 毫秒 1024 字节(即 1KB/s)。建议始终使用限制器,以避免来宾使用过多的主机资源。如果需要,max_bytes 的值为 0 可用于禁用所有限制。
QEMU 可以告知来宾它应该从哪些设备引导,以及按照什么顺序引导。这可以通过在配置中的 boot 属性进行指定,例如:
boot: order=scsi0;net0;hostpci0
这样,来宾将首先尝试从磁盘 scsi0 引导,如果失败,它将继续尝试从net0 进行网络引导,如果也失败,最后尝试从直通的 PCIe 设备引导(如果是 NVMe 则视作磁盘,否则尝试启动到选项 ROM)。
在 GUI 界面,您可以使用拖放编辑器来指定引导顺序,并为完全引导而使用复制框启用或禁用某些设备。
|
|
如果您的来宾使用多个磁盘来引导操作系统或加载 bootloader(引导加载程序),则必须将所有磁盘都标记为 bootable(可引导)(即是它们必须选中复制框启用或出现在配置列表中),以便来宾进行引导。这是因为新近的 SeaBIOS 和 OVMF 版本只会初始化被标记为 bootable(可引导) 的磁盘。 |
在任何情况下,一旦操作系统启动并初始化它们,即使未出现在列表中或者具有禁用复合标记的设备仍然可以在来宾中使用。bootable(可引导) 标志仅影响来宾的 BIOS 和 bootloader(引导加载程序)。
创建 VM 以后,您可能希望它们在主机系统启动时自动启动。为此,您需要从 Web 界面中的虚拟机的 选项 选项卡中选择 开机自启动 选项,或使用以下命令进行设置:
# qm set <vmid> -onboot 1
在某些情况下,您希望能够微调 VM 的启动顺序,例如,如果您的其中一个 VM 向其他来宾系统提供防火墙或 DHCP。为此,您可以使用以下参数:
启动/关机顺序:定义启动顺序的优先级。例如,如果您希望 VM 首先启动,请把它设置为 1(我们使用与启动顺序相反的关机顺序,因此启动顺序为 1 的机器将最后关机)。如果主机上的多个 VM 具有相同的启动顺序,它们将另外按照 VMID 升序排列的顺序。
启动延迟:定义此 VM 启动和后续 VM 启动之间的间隔。例如,如果您想在启动其他 VM 之前等待 240 秒,请将它设置为 240 。
关机超时:定义 Proxmox VE 在发出关机命令后等待 VM 离线的持续时间(以秒为单位)。默认情况下,这个值设置为 180,意味着 Proxmox VE 将发出关机请求并等待 180 秒让机器离线。如果超时以后机器仍然在线,它将被强制停止。
|
|
由 HA 堆栈(stack)管理的 VM 当前不遵循 开机自启动 和 引导顺序 选项。这些 VM 将跳过启动和关机算法,而由 HA 管理器自身来确保 VM 启动和停止。 |
请注意,没有 启动/关机顺序 参数的机器将始终在设置该参数的机器之后启动。此外,该参数仅在同一主机运行的虚拟机之间强制执行,而非集群范围。
如果您需要在主机的引导和首台 VM 的引导之间有一个延迟,请参阅 Proxmox VE 节点管理 。
Qemu Guest Agent(来宾代理)是一个运行在 VM 内部的服务,提供主机和来宾之间的通信通道。它用于交换信息和允许主机向来宾发送命令。
例如,VM 摘要面板中的 IP 地址是通过来宾代理获取的。
或者在开始备份时,通过来宾代理告知来宾通过 fs-freeze 和 fs-thaw 命令同步未完成的写入。
为了使来宾代理正常工作,必须采取以下步骤:
在来宾中安装代理(agent)并确保已运行
启用通过 Proxmox VE 中的代理(agent)进行通信
对于大多数 Linux 发行版,来宾代理(guest agent)是可用的,该软件包通常命名为 qemu-guest-agent。
对于 Windows,它可以从 Fedora VirtIO driver ISO(驱动) 下载并安装。
可以在 VM 的 选项 面板中启用 Proxmox VE 与来宾代理的通信。必须重启 VM 才能使更改生效。
如果可以启用 Run guest-trim 选项。启用此功能后,Proxmox VE 将在以下操作后向来宾发出修剪(trim)命令,这些操作有可能将零写入存储:
移动一个磁盘到其它存储
将 VM 实时迁移到具有本地存储的另一个节点
在自动精简配置的存储上,这有助于释放未使用的空间。
确保 guest agent(来宾代理)已经安装并运行。
启用 guest agent(来宾代理)后,Proxmox VE 将通过 guest agent(来宾代理)发送 关机 等电源命令。如果 guest agent(来宾代理)未运行,则无法正确执行命令,并且关机命令将运行超时。
SPICE 增强是可以改善远程查看器体验的可选功能。
通过 GUI 启用它们 ,请转到虚拟机的 选项 面板。或者通过 CLI 运行以下命令启用它们:
qm set <vmid> -spice_enhancements foldersharing=1,videostreaming=all
|
|
要使用这些功能,虚拟机的 显示 必须设置为 SPICE(qxl)。 |
为来宾共享本地文件夹。spice-webdavd 守护进程需要安装在来宾中,它通过位于 http://localhost:9843 的本地 WebDAV 服务器创建一个可用的共享文件夹。
对于 Windows 来宾,可以从 官方 SPICE 网站 下载 Spice WebDAV daemon 的安装程序。
大多数 Linux 发行版都有一个可以安装的名为 spice-webdavd 的软件包。
要在 Virt-Viewer(远程查看器)中共享文件夹,请转到 文件 → 首选项。选择要共享的文件夹,然后启用复选框。
|
|
文件夹共享目前仅适用于 Linux 版本的 Virt Viewer 。 |
|
|
试验!当前该功能无法可靠地工作。 |
快速刷新区域被编码为视频流。有两种选择:
all:任何快速刷新区域都将被编码为视频流。
filter:附加过滤器用于决定是否应使用视频流(当前仅跳过小的窗体表层)。
无法给出是否应启用视频流以及从哪个选项中进行选择的常规建议。您的情况可能会因具体情况而定。
确保 WebDAV 服务已启用并在来宾中运行。在 Windows 上,它称为 Spice webdav proxy 。在 Linux 中的名称是 spice-webdavd,但可能因发行版而异。
如果服务正在运行,通过在来宾的浏览器打开 http://localhost:9843 来检查 WebDAV 服务器。
它可以帮助重启 SPICE 会话。
如果您有一个集群,您可以通过以下命令迁移您的 VM 到其它主机:
# qm migrate <vmid> <target>
通常有两种机制
在线迁移 (亦称 实时迁移)
离线迁移
当您的 VM 正在运行且未定义本地资源(如本地存储上的磁盘,直通的设备等)时,您可以使用 -online 标志启动实时迁移。
这在目标主机上启动一个带有 传入(incoming) 标志的 Qemu 进程,这意味着该进程启动并等待来自源虚拟机的内存数据和设备状态(因为所其他资源(例如磁盘)都是共享的,仅有内存内容和设备状态需要传输)。
一旦建立了这个连接,源就开始异步发送内存内容给目标。如果源上的内存发生变化,这些部分将被标记为过期(dirty),并将再次发送数据。直到发送的数据量非常小,以至于它可以暂停源上的 VM ,将剩余的数据发送给目标,并在一秒钟内启动目标上的 VM 后,这种情况才会发生。
为让实时迁移可正常工作,需要满足一些条件:
该 VM 没有本地资源(如直通的设备、本地磁盘等)
该主机处于相同的 Proxmox VE 集群。
该主机具有活动(且可靠)的网络连接。
目标主机须有相同或更高版本的 Proxmox VE 软件包。(它可能以另一种方式工作,但这永远无法保证)
如果您有本地资源,您仍可离线迁移您的 VM ,只要所有磁盘均在两台主机定义的存储上。然后,迁移将会通过网络将磁盘复制到目标主机。
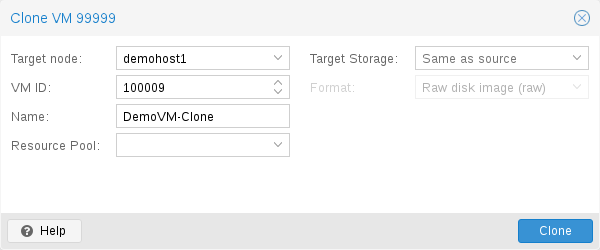
VM 的安装通常使用操作系统供应商提供的安装介质(CD-ROM)。根据不同的操作系统,这可以是一个需要避免的耗时任务。
部署相同类型的多个 VM 的一种简单的方式是复制现在的 VM 。我们把这样的副本称为 克隆,并区分为 链接 和 完整 克隆。
这种复制的结果是一个独立的 VM 。新的虚拟机不与原来的虚拟机共享任何存储资源。
它可以选择一个 目标存储,因此可以用它来将 VM 迁移到一个完全不同的存储。如果该存储驱动程序支持多种格式,您还可以更改磁盘映像的 格式 。
|
|
完整克隆需要读取并复制所有 VM 的映像数据。这通常比创建链接克隆慢得多 |
某些类型的存储允许复制指定的 快照,默认为 当前 VM 的数据。这也意味着最终的副本从不包含来自原始 VM 的任何其他快照。
现代存储驱动程序支持一种生成快速链接克隆的方法。这种克隆是一个可写副本,其初始内容与原始数据相同。创建链接克隆几乎是即时的,并且最初不占用额外空间。
它们被称为 链接 是因为新的映像仍然是引用原始映像。从原始的映像读取未修改的数据块,但在新的位置写入修改(然后读取)的数据块。这种技术称为 写时复制。
这需要该原始卷为只读。使用 Proxmox VE 可以将任何 VM 转换为只读 模板。之后可以用这些模板高效地创建链接克隆。
|
|
不能删除存在链接克隆的原始模板。 |
无法更改链接克隆的 目标存储,因为这是一个存储内部特性。
目标节点 选项允许您在不同的节点上创建新的 VM 。唯一的限制是该 VM 位于共享存储上,且该存储在目标节点上也可用。
为避免资源冲突,随机生成所有网络接口 MAC 地址,我们为 VM 的 BIOS (smbios1) 设置生成一个新的 UUID 。
可以将 VM 转换为模板。此类模板是只读的,您可以使用它们创建链接克隆。
|
|
无法启动模板,因为这会修改磁盘映像。如果要更改模板,请创建链接克隆并进行修改。 |
Proxmox VE 支持虚拟机的 VM Generation ID(vmgenid)
[官方 vmgenid 规范 https://docs.microsoft.com/en-us/windows/desktop/hyperv_v2/virtual-machine-generation-identifier]
。来宾操作系统可以使用它来检测导致时移事件的任何事件,例如,恢复备份或快照回滚。
创建新的虚拟机时,将自动生成 vmgenid 并保存到它的配置文件中。
要创建并添加一个 vmgenid 到现有的虚拟机,可以传递指定值‘1’让 Proxmox VE 自动生成一个或手动设置 UUID
[在线 GUID 生成器 http://guid.one/]
作为值,例如:
# qm set VMID -vmgenid 1 # qm set VMID -vmgenid 00000000-0000-0000-0000-000000000000
|
|
一个 vmgenid 设备在最初添加到现有 VM 时,可能会产生类似快照回滚、备份恢复等变化相同的效果,因为 VM 将此解释为换代。 |
在极少数情况下,不需要 vmgenid 机制,可以在创建 VM 时给它传递‘0’值,或者使用以下命令追溯删除配置中的属性:
# qm set VMID -delete vmgenid
最突出的用例是较新的 Microsoft Windows 操作系统使用 vmgenid 来避免在快照回滚、备份恢复或整个 VM 克隆操作中的时间敏感或复制服务(例如,数据库、域控制器
[https://docs.microsoft.com/en-us/windows-server/identity/ad-ds/get-started/virtual-dc/virtualized-domain-controller-architecture]
)时出现问题。
从外部虚拟机管理程序导出的 VM 通常采用一个或多个磁盘映像的形式,带有描述 VM 设置(内存、核心数量)的配置文件。
如果磁盘来自 VMware 或 VirtualBox,则磁盘映像可以采用 vmdk 格式;如果磁盘来自 KVM 虚拟机管理程序,则可以采用 qcow2 格式。用于 VM 导出的最流行的配置格式是 OVF 标准,但实际上互操作受到限制,因为很多设置并未在标准本身中实现,并且虚拟机管理程序会导出非标准扩展中的补充信息。
除了格式问题之外,如果模拟的硬件从一个虚拟机管理程序更改为另一个虚拟机管理程序时变化过大,从其他管理程序导入磁盘映像可能会失败。Windows VM 尤其关注这个方面,因为操作系统对硬件的任何变动都非常挑剔。也许可以在导出之前通过安装 Internet 上提供的 MergeIDE.zip 实用程序,并在导入的 Windows VM 启动之前选择使用 IDE 类型的硬盘来解决此问题。
最后是半虚拟化驱动程序的问题,它提高了模拟系统的速度并且特定于虚拟机管理程序。GNU/Linux 和其他免费的 Unix 操作系统默认安装了所有必需的驱动程序,您可以在导入 VM 后立刻切换到半虚拟化驱动程序。对于 Windows VM ,您需要自行安装 Windows 半虚拟化驱动程序。
GNU/Linux 和其他免费的 Unix 通常可以轻松导入。请注意,由于上述问题,我们无法保证在所有情况下都能成功导入/导出 Windows VM 。
Microsoft 提供的用于 Windows 开发的 虚拟机下载 ,我们将使用其中之一来演示 OVF 导入功能。
了解用户协议后,选择适用于 VMware 平台的 Windows 10 Enterprise (Evaluation - Build),然后下载 zip 压缩文件。
使用 unzip 实用工具或您选择的任何归档程序,解压 zip 压缩包,并通过 ssh/scp 将 ovf 和 vmdk 文件复制到 Proxmox VE 主机。
将从 OVF 清单中读取包含处理器、内存、和虚拟机名称信息的内容,以此来创建一个新的虚拟机,并将磁盘导入到 local-lvm 存储。您需要手动配置网络。
# qm importovf 999 WinDev1709Eval.ovf local-lvm
该 VM 已经准备就绪了。
您还可以添加现有磁盘映像到 VM ,它可以来自外部的管理器,也可以是您自己的管理器创建的。
假设您使用 vmdebootstrap 工具创建一个 Debian/Ubuntu 的磁盘映像:
vmdebootstrap --verbose \ --size 10GiB --serial-console \ --grub --no-extlinux \ --package openssh-server \ --package avahi-daemon \ --package qemu-guest-agent \ --hostname vm600 --enable-dhcp \ --customize=./copy_pub_ssh.sh \ --sparse --image vm600.raw
您现在可以为此映像创建新的目标 VM 。
# qm create 600 --net0 virtio,bridge=vmbr0 --name vm600 --serial0 socket \ --bootdisk scsi0 --scsihw virtio-scsi-pci --ostype l26
将该磁盘映像作为 unused0 添加到 VM ,存放在存储 pvedir:
# qm importdisk 600 vm600.raw pvedir
最后将未使用的磁盘附加到 VM 的 SCSI 控制器:
# qm set 600 --scsi0 pvedir:600/vm-600-disk-1.raw
该 VM 已准备好启动。
Cloud-Init 事实上是用于处理虚拟机实例的早期初始化的多元软件包。使用 Cloud-Init,可以在虚拟机管理程序端配置网络设备和 ssh 密钥,当首次启动 VM 时,VM 内的 Cloud-Init 软件将会应用这些设置。
许多 Linux 发行版提供即用型(ready-to-use)的 Cloud-Init 映像,主要是为 OpenStack 设计的。这些映像也适用于 Proxmox VE 。虽然获取这些即用型的映像似乎很方便,但是我们通常建议您自行准备映像。优点是您将确切知道您安装了什么,这有助于您稍后根据需要轻松自定义映像。
一旦您创建了这样的 Cloud-Init 映像,我们建议将其转换为 VM 模板。从 VM 模板可以快速创建链接克隆,因此这是一种快速推出新的 VM 实例的方法。您只需要在启动新的 VM 之前配置网络(可能还有 ssh 密钥)。
我们建议使用基于 SSH 密钥的身份验证登录到 Cloud-Init 提供的 VM 。也可以设置密码,但是不如使用基于 SSH 密钥的身份验证安全,因为 Proxmox VE 需要在 Cloud-Init 数据中存储该密码的加密版本。
Proxmox VE 生成一个 ISO 映像,将 Cloud-Init 数据传递给 VM 。为此,所有 Cloud-Init VM 都需要分配一个 CD-ROM 驱动器。此外,许多 Cloud-Init 映像假定拥有一个串行控制台,因此建议添加一个串行控制台并将其作为这些 VM 的显示器。
第一是准备 VM 。基本上您可以使用任何虚拟机。只需在您想要准备的 VM 内安装 Cloud-Init 软件包。在基于 Debian/Ubuntu 的系统上,这非常简单:
apt-get install cloud-init
已经有许多发行版提供了现成的 Cloud-Init 映像(提供为 .qcow2 文件),因此,您也可以简单地下载和导入这些映像。在下面的例子中,我们将使用由 Ubuntu 在 https://cloud-images.ubuntu.com 上提供的云映像。
# 下载映像 wget https://cloud-images.ubuntu.com/bionic/current/bionic-server-cloudimg-amd64.img # 创建新的 VM qm create 9000 --memory 2048 --net0 virtio,bridge=vmbr0 # 将下载的磁盘导入到 local-lvm 存储 qm importdisk 9000 bionic-server-cloudimg-amd64.img local-lvm # 最后将新磁盘做为 scsi 驱动器连接到虚拟机的(VM) qm set 9000 --scsihw virtio-scsi-pci --scsi0 local-lvm:vm-9000-disk-1
|
|
Ubuntu 的 Cloud-Init 映像需要控制器类型为 virtio-scsi-pci 的 SCSI 驱动器。 |
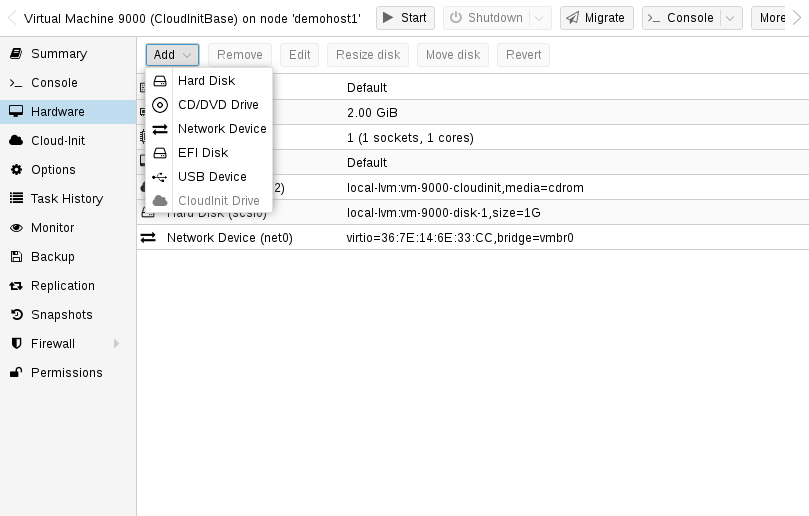
下一步是配置一个 CD-ROM 驱动器,它将用于将 Cloud-Init 数据传递给 VM 。
qm set 9000 --ide2 local-lvm:cloudinit
为了能够直接从 Cloud-Init 映像启动,请将 bootdisk 参数设置为 scsi0,并将 BIOS 限制为仅从磁盘启动。这将加快启动速度,因为 VM 的 BIOS 会跳过可启动 CD-ROM 的测试。
qm set 9000 --boot c --bootdisk scsi0
还要配置一个串行控制台并将其用作显示器。许多 Cloud-Init 映像依赖于此,因为这是 OpenStack 映像的要求。
qm set 9000 --serial0 socket --vga serial0
在最后一步,将 VM 转换为模板会很有帮助。然后,您可以从该模板快速创建链接克隆。从 VM 模板进行部署比创建完整克隆(副本)快得多。
qm template 9000
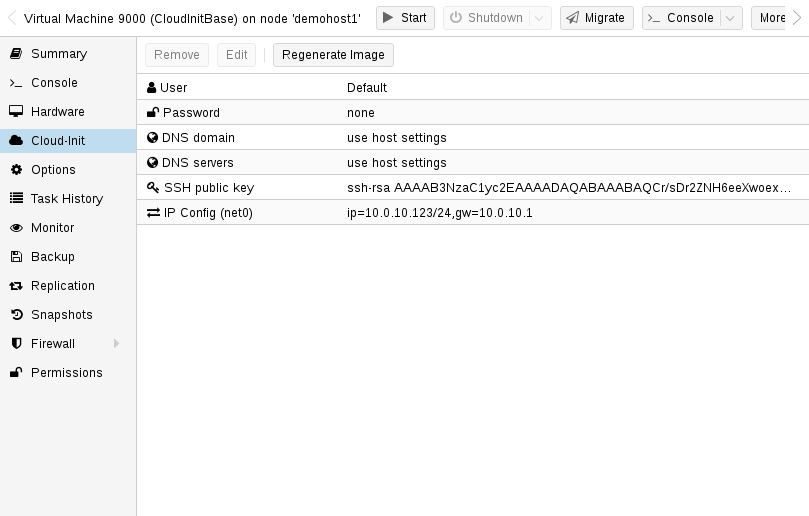
您可以通过克隆轻松部署这样的模板:
qm clone 9000 123 --name ubuntu2
然后配置用于身份验证的 SSH 公钥,并配置 IP 设置:
qm set 123 --sshkey ~/.ssh/id_rsa.pub qm set 123 --ipconfig0 ip=10.0.10.123/24,gw=10.0.10.1
您还可以仅使用单个命令配置所有 Cloud-Init 选项。我们简单地拆分了上面的范例,分离命令以减少行长度。还要确保采用适合您的特定环境的 IP 设置。
Cloud-Init 集成还允许使用自定义配置文件而不是自动生成的配置。这可以通过在命令行上的 cicustom 选项来完成:
qm set 9000 --cicustom "user=<volume>,network=<volume>,meta=<volume>"
自定义配置文件必须在支持片段的存储上,并且必须在 VM 将要迁移到的所有节点上可用。否则 VM 将无法启动。例如:
qm set 9000 --cicustom "user=local:snippets/userconfig.yaml"
Cloud-Init 有三种类型的配置。第一个是 user(用户)配置,如上面的范例所示。第二个是 network(网络)配置,第三个是 meta(元)配置。它们既可以一起指定,也可以根据需要混合和匹配指定。任何没有指定自定义配置的都将使用自动生成的配置。
生成的配置可以转储作为自定义配置的基础:
qm cloudinit dump 9000 user
network(网络)和 meta(元)也有相同的命令。
指定自定义文件以替换在开始时自动生成的文件。
指定一个自定义文件,其中包含通过 Cloud-Init 传递给 VM 的所有 meta 数据。这是提供商特定的,意味着 configdrive2 与 nocloud 有所不同。
指定一个自定义文件,其中包含通过 Cloud-Init 传递给 VM 的所有 network 数据
指定一个自定义文件,其中包含通过 Cloud-Init 传递给 VM 的所有 user 数据。
指定一个自定义文件,其中包含通过 Cloud-Init 传递给 VM 的所有 vendor 的数据。
分配用户的密码。通常不推荐使用它,请改用 ssh 密钥。另请注意,较旧版本的 Cloud-Init 不支持哈希的密码。
指定 cloud-init 配置格式。默认取决于配置的操作系统类型(ostype)。我们对于 Linux 使用 nocloud 格式,对于 Windows 使用 configdrive2 。
更改 ssh 密钥和密码的用户名,而不是映像的配置的默认用户。
为相应的接口指定 IP 地址和网关。
IP 地址使用 CIDR 表示法,网关为可选的,但需要指定相同类型的 IP 。
特殊字符串 dhcp 可用于使用 DHCP 获取 IP 地址,在这种情况下不提供显式网关。对于 IPv6 ,特殊字符串 auto 可用于无状态自动配置。这需要 cloud-init 19.4 或更高版本。
如果启用了 cloud-init 且同时未指定 IPv4 和 IPv6 地址,它默认在 IPv4 上使用 dhcp 。
用于 IPv4 通信的默认网关。
|
|
需要选项:ip |
用于 IPv6 通信的默认网关。
|
|
需要选项:ip6 |
CIDR 格式的 IPv4 地址。
CIDR 格式的 IPv6 地址。
为容器设置 DNS 服务器 IP 地址。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
为容器设置 DNS 搜索域。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
设置公共 SSH 密钥(每行一个密钥,OpenSSH 格式)。
PCI(e) 直通是一种让虚拟机从主机控制一个 PCI 设备的机制。这比使用虚拟化的硬件多一些优势,例如更低的延迟、更高的性能或更多特性(例如分流)。
但是,如果将设备直通给虚拟机,则不能在主机或任何其他 VM 中使用该设备。
由于直通也是一个需要硬件支持的功能,因此需要进行一些检查和准备工作才能使其工作。
您的硬件必须支持 IOMMU (输入输出内存管理单元:I/O Memory Management Unit 的简称)中断重映射(Interrupt Remapping),这是 CPU 和主板的功能之一。
通常,采用 VT-d 的 Intel 体系和采用 AMD-Vi 的 AMD 体系都支持这个功能,但由于硬件质量问题、缺少或低质量的驱动程序,无法保证一切都能开箱即用。
此外,服务器级硬件通常比消费级硬件具有更好的支持,即使如此,许多现代硬件系统同样支持该功能。
请咨询您的硬件供应商,对于您的特定设置,检查它们在 Linux 下是否支持这些功能。
一旦确保您的硬件支持直通,您需要进行一些配置来启用 PCI(e) 直通。
首先,必须在您的 BIOS/UEFI 中启用 IOMMU 支持。大多数情况下,该选项被命名为 IOMMU 或 VT-d,但是,请查看您的主板手册以了解您需要启用的确切选项。
然后,必须 内核命令行 上激活 IOMMU 。
命令行参数为:
对于 Intel CPU:
intel_iommu=on
对于 AMD CPU,它应该自动启用。
您必须确保加载了以下模块。这可以通过将它们添加到‘/etc/modules’来实现。
vfio vfio_iommu_type1 vfio_pci vfio_virqfd
完成任何相关的更改后,您需要刷新 initramfs 。在 Proxmox VE 上,这可以通过执行以下命令来完成:
# update-initramfs -u -k all
最后重启让更改生效,并检查它是否确实已启用。
# dmesg | grep -e DMAR -e IOMMU -e AMD-Vi
应该显示 IOMMU、Directed I/O 或 Interrupt Remapping 已启用,具体取决于硬件和内核,确切的消息可能会有所不同。
您要直通的设备位于一个 单独(separate) 的 IOMMU 组中也很重要。这可以通过以下方式检查:
# find /sys/kernel/iommu_groups/ -type l
要不然,除非设备与其自带功能(例如带有 HDMI 音频设备的 GPU)或它的根端口或 PCI(e) 桥接器共同位于 IOMMU 组中。
|
|
PCI(e) 插槽
部分平台以不同方式处理它们的物理 PCI(e) 插槽。因此,如果您无法获取所需的 IOMMU 组分离,有时需要将板卡放入另一个 PCI(e) 插槽会有所帮助。 |
|
|
不安全的中断
对于部分平台,它可以需要允许不安全的中断。为此,在 /etc/modprobe.d/ 下的‘.conf’文件结尾的文件中,添加以下行: options vfio_iommu_type1 allow_unsafe_interrupts=1 请注意,此选项可能会使您的系统不稳定。 |
无法在 Proxmox VE 的 Web 界面上通过 NoVNC 或 SPICE 显示 GPU 的帧缓冲区。
当直通的整个 GPU 或 vGPU 需要图形输出时,必须将显示器物理连接到板卡,或者在来宾内部配置远程桌面软件(例如,VNC 或 RDP)。
如果您想将 GPU 用作硬件加速器,例如,对于使用 OpenCL 或 CUDA 的程序,这不是必要的。
PCI(e) 直通最常用的是直通各种的 PCI(e) 板卡,例如 GPU 或网卡。
在这种情况下,主机不得使用该板卡。有两种方法可以实现这一点:
通过添加到 /etc/modprobe.d/ 中的 .conf 文件,将设备 ID 传递给 vfio-pci 的 options 模块:
options vfio-pci ids=1234:5678,4321:8765
其中 1234:5678 和 4321:8765 是通过以下方式获得的供应商和设备 ID:
# lspci -nn
确保板卡可以无障碍的用于直通绑定,通过在 /etc/modprobe.d/ 的 .conf 文件中使用
blacklist DRIVERNAME
将主机上的驱动程序完全列入黑名单。
对于这两种方法,您都需要再次 更新 initramfs 并在此之后重新启动。
要检查您的更改是否成功,您可以使用
# lspci -nnk
并检查您的设备条目,如果显示
Kernel driver in use: vfio-pci
或 in use 行完全丢失,则该设备已准备好用于直通。
要直通设备,您需要在 VM 中设置 hostpciX 选项,例如通过执行:
# qm set VMID -hostpci0 00:02.0
如果您的设备具有多个功能(例如,‘00:02.0’和‘00:02.1’),您可以使用缩短的语法“00:02”将它们一起传递。这等同于在 Web 界面中选中“所有功能(All Functions)”复选框。
根据设备和来宾操作系统,部分选项有可能是必要的:
x-vga=on|off 将 PCI(e) 设备标记为 VM 的主 GPU 。启用此选项后,将忽略 vga 配置选项。
pcie=on|off 告诉 Proxmox VE 使用 PCIe 或 PCI 端口。某些来宾/设备组合需要 PCIe 而不是 PCI。PCIe 仅适用于 q35 类型的机器。
rombar=on|off 让固件 ROM 对来宾可见。默认是 on(开启)。某些 PCI(e) 设备需要禁用此功能。
romfile=<path>,是供设备使用的 ROM 文件的可选路径。这是 /usr/share/kvm/ 的相对路径。
设置 GPU 为主 GPU 的 PCIe 直通范例:
# qm set VMID -hostpci0 02:00,pcie=on,x-vga=on
在直通 GPU 时,使用 q35 作为机器类型,OVMF(用于虚拟机的 EFI)代替 SeaBIOS 以及 PCIe 代替 PCI ,可达到最佳的兼容性。请注意,如果您想要使用 OVMF 用于 GPU 直通,GPU需要有支持 EFI 的 ROM,否则使用 SeaBIOS 代替。
直通 PCI(e) 设备的另一种方式,是使用设备的硬件虚拟化功能(如果可用)。
SR-IOV(Single-Root Input/Output Virtualization)使单个设备能够为系统提供多个 VF(Virtual Functions,虚拟功能的简称)。这些 VF 中的每一个都可以在不同的 VM 中使用。每个都有完整的硬件特性,以及比软件虚拟化的设备更好的性能和更低的延迟。
目前,最常见的用例是支持 SR-IOV 的 NIC(Network Interface Card,网络接口卡,或网卡),它可以为每个物理端口提供多个 VF 。还允许在 VM 内使用诸如校验与分流等功能,以减少(主机)CPU 的开销。
通常,在设备上启用虚拟功能有两种方法。
有时,驱动程序模块里有这样的一个选项,例如,对于某些英特尔驱动程序
max_vfs=4
可以将其放在 /etc/modprobe.d/ 下的以 .conf 结尾的文件中。(之后不要忘记更新您的 initramfs)
有关确切的参数和选项,请参阅您的驱动程序模块文档。
更通用的第二种方法是使用 sysfs 。如果设备和驱动程序支持此功能,您可以动态更改 VF 的数量。例如,要在设备 0000:01:00.0 上设置 4 个 VF,请执行:
# echo 4 > /sys/bus/pci/devices/0000:01:00.0/sriov_numvfs
要使此更改持久化,您可以使用 Debian 的“sysfsutils”软件包。安装后通过 /etc/sysfs.conf 或 /etc/sysfs.d/ 下的“FILE.conf”配置它。
创建 VF 后,使用 lspci 命令输出它们时,您应该将它们视为单独的 PCI(e) 设备。获取它们的 ID 并像 常规 PCI(e) 设备 一样直通它们。
对于此功能,平台支持尤为重要。可能需要先在 BIOS/EFI 中启用此功能,或者使用指定的 PCI(e) 端口才能使其工作。如有疑问,请查阅平台手册或联系供应商。
中介设备(Mediated devices)是另一种为虚拟化硬件重复利用物理硬件的功能和性能的方法。这些在虚拟化 GPU 设置中最为常见,例如在 GRID 技术中使用的 Intel 的 GVT-g 和 NVIDIA 的 vGPU 。
这样,物理板卡就可以创建虚拟板卡,类似于 SR-IOV。不同之处在于,中介设备不会在主机中显示为 PCI(e) 设备,并且仅适用于在虚拟机使用。
一般来说,您的板卡的驱动程序必须支持该功能,否则将无法正常工作。因此,请向您的供应商咨询兼容的驱动程序以及如何配置它们。
Intel 的 GVT-g 驱动程序已集成在内核中,应与第五、第六和第七代的 Intel 酷睿处理器以及 E3 v4、E3 v5 和 E3 v6 至强处理器配合使用。
要为 Intel 显卡启用它,您必须确保加载 kvmgt 模块(例如,通过/etc/modules),并在 内核命令行 中通过添加以下参数来启用它:
i915.enable_gvt=1
之后记得 更新 initramfs ,并重启您的主机。
要使用中介设备,只需在 VM 的配置选项 hostpciX 上指定 mdev 属性。
您可以通过 sysfs 获取支持的设备。例如,列出设备 0000:00:02.0 支持的类型,您只需执行:
# ls /sys/bus/pci/devices/0000:00:02.0/mdev_supported_types
每个条目都是一个目录,其中包含以下重要文件:
available_instances 包含此类型仍然可用的实例的数量,VM 中每次使用 mdev 都会减少此数量。
description 包含有关此类型功能的简短描述
create 是创建此类设备的端点,如果配置了带有 mdev 属性的 hostpciX 选项,Proxmox VE 会自动为您执行此操作。
使用 Intel GVT-g vGPU(Intel Skylake 6700k)的范例配置:
# qm set VMID -hostpci0 00:02.0,mdev=i915-GVTg_V5_4
有了这个设置,Proxmox VE 会在 VM 启动时自动创建这样一个设备,并在 VM 停止时再次清理它。
您可以通过配置属性 hookscript 向 VM 添加挂钩脚本。
# qm set 100 --hookscript local:snippets/hookscript.pl
它将在来宾生命周期的各个阶段进行调用。有关范例和文档,请参阅范例脚本 /usr/share/pve-docs/examples/guest-example-hookscript.pl 。
要将 VM 挂起到磁盘,您可以使用 GUI 的 休眠(Hibernate) 选项或者使用
# qm suspend ID --todisk
这意味着当前内存中的内容将被保存到磁盘上,并且 VM 将停止。下次启动时,内存的内容将被加载并且 VM 可以从上次停止的地方继续运行。
如果未给内存提供目标存储,它将自动选择,第一个:
来自 VM 配置的存储 vmstatestorage 。
来自任何 VM 磁盘的第一个共享存储。
来自任何 VM 磁盘的第一个非共享存储。
存储 local 作为后备。
qm 是在 Proxmox VE 上管理 Qemu/Kvm 虚拟机的工具。您可以创建和销毁虚拟机,并控制执行(启动/停止/挂起/恢复)。除此之外,您可以在关联的配置文件中使用 qm 设置参数,还可以创建和删除虚拟磁盘。
使用上传到 local 存储的 ISO 文件,在 local-lvm 存储上创建一个带有 4GB 的 IDE 磁盘的 VM 。
# qm create 300 -ide0 local-lvm:4 -net0 e1000 -cdrom local:iso/proxmox-mailgateway_2.1.iso
启动新的 VM
# qm start 300
发送关机请求,然后等待该 VM 停止。
# qm shutdown 300 && qm wait 300
同上,但只等待 40 秒。
# qm shutdown 300 && qm wait 300 -timeout 40
销毁 VM ,始终会将它从访问控制列表中删除,并且始终会删除 VM 的防火墙配置。如果您想额外从复制作业、备份作业和 HA 资源配置中删除 VM ,则必须激活 --purge 参数 。
# qm destroy 300 --purge
移动磁盘映像到不同存储。
# qm move-disk 300 scsi0 other-storage
将磁盘映像重新分配给不同的 VM 。这将从源 VM 删除 scsi1 ,并将其为 scsi3 附加到目标 VM 。在后台,磁盘映像正在被重命名,以便名称与新的所有者相匹配。
# qm move-disk 300 scsi1 --target-vmid 400 --target-disk scsi3
VM 的配置文件存储在 Proxmox 集群文件系统中,可以在 /etc/pve/qemu-server/<VMID>.conf 中访问。与存储在 /etc/pve/ 中的其他文件一样,它们会自动复制到所有其他集群节点。
|
|
小于 100 的 VMID 是保留用于内部用途,并且 VMID 需要在集群范围内是唯一的。 |
boot: order=virtio0;net0 cores: 1 sockets: 1 memory: 512 name: webmail ostype: l26 net0: e1000=EE:D2:28:5F:B6:3E,bridge=vmbr0 virtio0: local:vm-100-disk-1,size=32G
这些配置文件是简单的文本文件,您可以使用普通的文本编辑器(vi、nano等)编辑它们。这有时对做些小修改很有用,但请记住,您需要重启 VM 才能应用此类更改。
出于这个原因,通常最好使用 qm 命令来生成和修改这些文件,或者使用 GUI 完成整个操作。我们的工具箱足够智能,可以立即将大多数更改应用到正在运行的 VM 。这一特性称为“热插拔”,在这种情况下无需重启 VM 。
VM 配置文件使用简单的格式,键和值使用冒号分隔(如 key:value)。每行有以下的格式:
# this is a comment OPTION: value
这些文件中的空白行被忽略,以 # 字符开头的行被视为注释,也同样被忽略。
当您创建快照,qm 在生成快照时将配置存储到具有相同配置文件的单独快照部分中。例如,创建一个名为“testsnapshot”的快照后,您的配置文件将如下所示::
memory: 512 swap: 512 parent: testsnaphot ... [testsnaphot] memory: 512 swap: 512 snaptime: 1457170803 ...
有一些与快照相关的属性,例如 parent 和 snaptime。parent 属性用于存储快照之间的父/子关系。snaptime 是快照创建的时间戳(Unix 纪元)。
启用/禁用 ACPI 。
启用/禁用与 Qemu 来宾代理(Guest Agent)及其属性的通信
启用/禁用与在 VM 中运行的 Qemu 来宾代理(Guest Agent)(简称 QGA) 的通信。
在移动磁盘或迁移 VM 后运行 fstrim 。
选择代理(agent)类型
虚拟处理器架构。默认为 host 。
传递给 kvm 的任意参数,例如:
args: -no-reboot -no-hpet
|
|
此选项仅供专家使用。 |
配置音频设备,与 QXL/Spice 结合使用。
配置音频设备。
用于音频设备的驱动程序后端。
崩溃后自动重启(目前被忽略)。
VM 的目标内存数量(以 MB 为单位)。使用 0 会禁用 ballon 驱动程序。
选择 BIOS 实现。
指定来宾引导顺序,使用 order= 子属性,因为不推荐使用无密钥或 legacy= 的用法。
在软驱(a)、硬盘(c)、CD-ROM(d)或网络(n)上启动。已弃用,请改用 order= 。
来宾将尝试按照它们在此处显示的顺序从设备引导。
磁盘、光驱和直通的存储 USB 设备将直接启动,网卡将加载 PXE,而 PCIe 设备将表现得像磁盘(例如 NVMe)或加载一个选项 ROM(例如 RAID 控制器、硬件网卡)。
请注意,只有此列表的设备才会标记为可引导,从而通过来宾固件(BIOS/UEFI)加载。如果您需要多个磁盘进行引导(例如,软 RAID),您需要在此处指定所有磁盘。
在给定值时覆盖已弃用的 legacy=[acdn]* 值。
启用从指定磁盘启动。已弃用:改用 boot: order=foo;bar 。
这是选项 -ide2 的别名
cloud-init:指定自定义文件以替换启动时自动生成的文件。
指定一个自定义文件,其中包含通过 Cloud-Init 传递给 VM 的所有 meta 数据。这是提供商特定的,意味着 configdrive2 与 nocloud 有所不同。
指定一个自定义文件,其中包含通过 Cloud-Init 传递给 VM 的所有 network 数据。
指定一个自定义文件,其中包含通过 Cloud-Init 传递给 VM 的所有 user 数据。
指定一个自定义文件,其中包含通过 Cloud-Init 传递给 VM 的所有 vendor 数据。
cloud-init:分配用户的密码。通常不推荐使用它,请改用 ssh 密钥。另请注意,较旧版本的 Cloud-Init 不支持哈希的密码。
指定 cloud-init 配置格式。默认取决于配置的操作系统类型(ostype)。我们对于 Linux 使用 nocloud 格式,对于 Windows 使用 configdrive2 。
cloud-init:更改 ssh 密钥和密码的用户名,而不是映像的配置的默认用户。
每个插槽的核心数。
模拟 CPU 类型。
模拟 CPU 类型。可以默认名称或自定义名称(自定义型号的名称必须以 custom- 为前缀)。
由 ; 分隔的附加 CPU 标志的列表。使用 +FLAG 启用标志,使用 -FLAG 禁用标志。自定义 CPU 型号可以指定 QEMU/KVM 支持的任何标志,出于安全原因,特定于 VM 的标志必须来自以下设置:pcid、spec-ctrl、 ibpb、 ssbd、 virt-ssbd、 amd-ssbd、 amd-no-ssb、 pdpe1gb、 md-clear、 hv-tlbflush、 hv-evmcs、 aes 。
不要识别为 KVM 虚拟机。
Hyper-V 供应商 ID 。Windows 来宾中的某些驱动程序或程序需要特定的 ID 。
报告给来宾操作系统的物理内存地址位,应该小于或等于主机的内存地址位。设置为 host 用于使用来自主机 CPU 的值,但请注意,这样做会中断具有其他值的 CPU 的实时迁移。
向来宾报告 CPU 型号和供应商。必须是 QEMU/KVM 支持的型号。仅对自定义 CPU 型号的定义有效,默认型号仍然始终报告给来宾操作系统。
CPU 使用限制。
|
|
如果计算机有 2 个 CPU,它总共有 2 个 CPU 时间,值为 0 表示没有 CPU 限制。 |
VM 的 CPU 权重。参数是用于内核公平调试程序,这个数字越大,这个 VM 获得的 CPU 时间越多。该数字与所有其它正在运行的 VM 的权重相关。
VM 备注。显示在 Web 界面中的 VM 的摘要中。这被保存为配置文件中的备注。
配置一个磁盘用于存储 EFI 变量。使用特殊的语法 STORAGE_ID:SIZE_IN_GiB 分配新卷,请注意,此处忽略 SIZE_IN_GiB ,而是将默认 EFI 变量复制到卷中。
OVMF EFI 变量的大小和类型。4m 较新,推荐使用,安全启动需要。为了向后兼容,如果没有另外指定,则使用 2m 。
驱动器的备份卷。
驱动器的备份文件的数据格式。
如果与 efitype=4m 一起使用,则使用我们的 EFI 变量模板,其中注册了特定于分发的密钥和 Microsoft 标准密钥。请注意,这将默认启用安全启动,但仍然可以从 VM 中关闭它。
磁盘大小。这纯粹是信息性的,没有任何效果。
启动时冻结 CPU(使用 c monitor 命令开始执行 )。
将在 vms(虚拟内存系统) 生命周期的各个步骤中执行的挂钩脚本。
将主机 PCI 设备映射到来宾。
|
|
此选项允许直接访问主机硬件。因此不再可能迁移此类机器 - 使用时要特别小心。 |
|
|
实验性的!用户报告此选项有问题。 |
直通主机 PCI 设备。主机的 PCI 设备的 PCI ID 或 主机的 PCI 虚拟功能的列表。HOSTPCIID 语法是:
bus:dev.func (十六进制数)
您可以使用 lspci 命令列出现有的 PCI 设备。
在传统 IGD 模式直通此设备,使其成本 VM 中的主要和专用图形设备。需要 pc-i440fx 机器类型和 VGA 设置为 none 。
要使用的中介设备的类型。此类实例将在 VM 启动时创建,并在 VM 停止时清除。
选择 PCI-express 总线(需要 q35 型号的机器)。
指定设备的 ROM 是否在来宾的内存映射中可用。
自定义 pci 设备 rom 的文件名(必须位于 /usr/share/kvm/)。
启用 vfio-vga 设备支持。
有选择地启用热插拔功能。这是逗号分隔的热插拔功能的列表:network, disk, cpu, memory 和 usb。使用 0 完全禁用热插拔。使用 1 作为值等于是默认的 network,disk,usb 。
启用/禁用大页面内存。
将卷用作 IDE 硬盘或 CD-ROM(n 是 0 到 3)。使用特殊语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。
要使用的 AIO 类型。
进行备份时是否应包括驱动器。
最大读/写速度(以 字节数/每秒 为单位)。
I/O 突发的最大长度(以秒为单位)
最大读取速度(以 字节数/每秒 为单位)。
读取 I/O 突发的最大长度(以秒为单位)。
最大写入速度(以 字节数/每秒 为单位)。
写入 I/O 突发的最大长度(以秒为单位)。
驱动器的缓存模式
强制驱动器的物理几何结构具有特定的柱面数。
控制是否检测并尝试优化零写入。
控制是否将丢弃/修剪(discard/trim)请求传递给底层存储。
驱动器的备份卷。
驱动器的备份文件的数据格式。
强制驱动器的物理几何结构具有特定的磁头数。
最大每秒读写操作次数。
最大无阻塞读/写 I/O 池的每秒操作数。
I/O 突发的最大长度(以秒为单位)。
最大读取 I/O 的每秒操作数。
最大无阻塞读取 I/O 池的每秒操作数。
读取 I/O 突发的最大长度(以秒为单位)。
最大写入 I/O 的每秒操作数。
最大无阻塞写入 I/O 池的每秒操作数。
写入 I/O 突发的最大长度(以秒为单位)。
最大读/写速度(以 MB/s 为单位)。
最大无阻塞读/写池(以 MB/s 为单位)。
最大读取速度(以 MB/s 为单位)。
最大无阻塞读取池(以 MB/s 为单位)。
最大写入速度(以 MB/s 为单位)。
最大无阻塞写入池(以 MB/s 为单位)。
驱动器的媒体类型。
驱动器报告的型号名称,url 编码,最长 40 个字节。
是否考虑将驱动器用于复制作业。
读取错误操作。
强制驱动器的物理几何结构具有特定的扇区数。
驱动器报告的序列号,url 编码,最长 20 个字节。
将此本地管理的卷标记为在所有节点上可用。
|
|
此选项不会自动共享卷,它假定它已经共享了! |
磁盘大小。这纯粹是信息性的,没有任何效果。
控制 qemu 的快照模式功能。如果激活,对磁盘所做的更改是临时的且将在 VM 关闭时被丢弃。
是否将此驱动器公开为 SSD,而不是机械硬盘。
强制磁盘几何结构在 BIOS 的转换模式。
写入错误操作。
驱动器的全球名称(WWN),编码为 16 字节的 16 进制字符串,以 0x 作为前缀。
cloud-init:为相应的接口指定 IP 地址和网关。
IP 地址使用 CIDR 表示法,网关为可选的,但需要指定相同类型的 IP 。
特殊字符串 dhcp 可用于使用 DHCP 获取 IP 地址,在这种情况下不提供显式网关。对于 IPv6 ,特殊字符串 auto 可用于无状态自动配置。这需要 cloud-init 19.4 或更高版本。
如果启用了 cloud-init 且同时未指定 IPv4 和 IPv6 地址,它默认在 IPv4 上使用 dhcp 。
用于 IPv4 通信的默认网关。
|
|
需要选项:ip |
用于 IPv6 通信的默认网关。
|
|
需要选项:ip6 |
CIDR 格式的 IPv4 地址。
CIDR 格式的 IPv6 地址。
虚拟机间(Inter-VM)共享内存。用于 VM 之间或与主机的直接通信。
文件的名称。使用 pve-shm- 作为前缀。默认是 VMID 。当 VM 停止时会删除。
文件大小(以 MB 为单位)。
与 hugepages 一起使用。如果启用,VM 关机后大页面将不会被删除,可用于后续启动。
用于 VNC 服务器的键盘布局。默认值是从配置文件 '/etc/pve/datacenter.cfg' 读取。它不是必要设置。
启用/禁用 KVM 硬件虚拟化。
将实时时钟 (RTC) 设置为本地时间。如果 ostype 指示 Microsoft Windows 操作系统,则默认启用此功能。
锁定/解锁 VM 。
指定 Qemu 机器类型。
VM 的内存量(以 MB 为单位)。这是您使用 balloon 设备时的最大可用内存。
设置迁移的最大允许停机时间(以秒为单位)。
设置迁移的最大速度(以 MB/s 为单位)。值为 0 表示没有限制。
设置 VM 的名称。仅在配置 Web 界面上使用。
cloud-init:为容器设置 DNS 服务器 IP 地址。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
指定网络设备。
网桥用于连接网络设备。Proxmox VE 标准的网桥称为 vmbr0 。
如果您未指定网桥,我们会创建一个 kvm 用户(NAT)网络设备,它提供 DHCP 和 DNS 服务。使用以下地址:
10.0.2.2 Gateway 10.0.2.3 DNS Server 10.0.2.4 SMB Server
DHCP 服务器从 10.0.2.15 开始为来宾分配地址。
该接口是否受防火墙保护。
该接口是否应该断开(如拔插头)。
未设置 I/G(Individual/Group)位的通用MAC地址。
网卡型号。virtio 型号以极低的 CPU 开销提供最佳性能。如果来宾不支持此驱动程序,通常最好使用 e1000 。
强制 MTU,仅适用于 VirtIO 。设置 1 为使用网桥的 MTU 。
要在设备上使用的数据包队列数。
以 Mbps(以 MB/s 为单位)为单位的速率限制,作为浮点数。
要应用到此接口上的数据包的 VLAN 标签(tag)。
允许通过此接口的 VLAN(即 Trunk)。
启用/禁用 NUMA 。
NUMA 拓扑。
访问此 NUMA 节点的 CPU 。
要使用的主机 NUMA 节点。
此 NUMA 节点提供的内存量。
NUMA 分配策略。
指定是否在系统启动期间启动 VM 。
指定来宾操作系统。这用于为指定的操作系统启用特殊优化/功能:
| other | 未指定的操作系统 |
| wxp | Microsoft Windows XP |
| w2k |
Microsoft Windows 2000 |
| w2k3 |
Microsoft Windows 2003 |
| w2k8 |
Microsoft Windows 2008 |
| wvista |
Microsoft Windows Vista |
| win7 |
Microsoft Windows 7 |
| win8 |
Microsoft Windows 8/2012/2012r2 |
| win10 |
Microsoft Windows 10/2016/2019 |
| win11 |
Microsoft Windows 11/2022 |
| l24 |
Linux 2.4 Kernel |
| l26 |
Linux 2.6 - 5.X Kernel |
| solaris |
Solaris/OpenSolaris/OpenIndiania kernel |
映射主机并行设备(n 是 0 到 2)。
|
|
此选项允许直接访问主机硬件。因此不再可能迁移此类机器 - 使用时要特别小心。 |
|
|
实验性的!用户报告此选项有问题。 |
设置 VM 的保护标志。这将禁用移除 VM 和移除磁盘操作。
允许重启。如果设置为 0,VM 会在重启时退出。
配置基于 VirtIO 的随机数生成器(VirtIO RNG)。
在每个毫秒数的period(周期)内允许增加到来宾的熵的最大字节数。使用 /dev/random 作为源时,最好使用较低的值。使用 0 禁用限制(潜在危险!)。
每个毫秒数的 period(周期) 会重置熵增配额,允许来宾检索另一个熵的 max_bytes 。
主机上要从中收集熵的文件。在大多数情况下,/dev/urandom 该优先于 /dev/random,以避免主机上的熵饥饿(entropy-starvation)问题。使用 urandom 不会以任何有意义的方式降低安全性,因为它仍然来自真实的熵,并且提供的字节很可能也与来宾上的真实熵混合。/dev/hwrng 可用于从主机传递硬件 RNG。
将卷用作 SATA 硬盘或 CD-ROM(n 为 0 到 5)。使用特殊语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。
要使用的 AIO 类型。
进行备份时是否应包括驱动器。
最大读/写速度(以 字节数/每秒 为单位)。
I/O 突发的最大长度(以秒为单位)。
最大读取速度(以 字节数/每秒 为单位)。
读取 I/O 突发的最大长度(以秒为单位)。
最大写入速度(以 字节数/每秒 为单位)。
写入 I/O 突发的最大长度(以秒为单位)。
驱动器的缓存模式
强制驱动器的物理几何结构具有特定的柱面数。
控制是否检测并尝试优化零写入。
控制是否将丢弃/修剪(discard/trim)请求传递给底层存储。
驱动器的备份卷。
驱动器的备份文件的数据格式。
强制驱动器的物理几何结构具有特定的磁头数。
最大每秒读写操作次数。
最大无阻塞读/写 I/O 池的每秒操作数。
I/O 突发的最大长度(以秒为单位)。
最大读取 I/O 的每秒操作数。
最大无阻塞读取 I/O 池的每秒操作数。
读取 I/O 突发的最大长度(以秒为单位)。
最大写入 I/O 的每秒操作数。
最大无阻塞写入 I/O 池的每秒操作数。
写入 I/O 突发的最大长度(以秒为单位)。
最大读/写速度(以 MB/s 为单位)。
最大无阻塞读/写池(以 MB/s 为单位)。
最大读取速度(以 MB/s 为单位)。
最大无阻塞读取池(以 MB/s 为单位)。
最大写入速度(以 MB/s 为单位)。
最大无阻塞写入池(以 MB/s 为单位)。
驱动器的媒体类型。
是否考虑将驱动器用于复制作业。
读取错误操作。
强制驱动器的物理几何结构具有特定的扇区数。
驱动器报告的序列号,url 编码,最长 20 个字节。
将此本地管理的卷标记为在所有节点上可用。
|
|
此选项不会自动共享卷,它假定它已经共享了! |
磁盘大小。这纯粹是信息性的,没有任何效果。
控制 qemu 的快照模式功能。如果激活,对磁盘所做的更改是临时的且将在 VM 关闭时被丢弃。
是否将此驱动器公开为 SSD,而不是机械硬盘。
强制磁盘几何结构在 BIOS 的转换模式。
写入错误操作。
驱动器的全球名称(WWN),编码为 16 字节的 16 进制字符串,以 0x 作为前缀。
将卷用作 SCSI 硬盘或 CD-ROM(n 为 0 到 30)。使用特殊语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。
要使用的 AIO 类型。
进行备份时是否应包括驱动器。
最大读/写速度(以 字节数/每秒 为单位)。
I/O 突发的最大长度(以秒为单位)。
最大读取速度(以 字节数/每秒 为单位)。
读取 I/O 突发的最大长度(以秒为单位)。
最大写入速度(以 字节数/每秒 为单位)。
写入 I/O 突发的最大长度(以秒为单位)。
驱动器的缓存模式
强制驱动器的物理几何结构具有特定的柱面数。
控制是否检测并尝试优化零写入。
控制是否将丢弃/修剪(discard/trim)请求传递给底层存储。
驱动器的备份卷。
驱动器的备份文件的数据格式。
强制驱动器的物理几何结构具有特定的磁头数。
最大每秒读写操作次数。
最大无阻塞读/写 I/O 池的每秒操作数。
I/O 突发的最大长度(以秒为单位)。
最大读取 I/O 的每秒操作数。
最大无阻塞读取 I/O 池的每秒操作数。
读取 I/O 突发的最大长度(以秒为单位)。
最大写入 I/O 的每秒操作数。
最大无阻塞写入 I/O 池的每秒操作数。
写入 I/O 突发的最大长度(以秒为单位)。
是否为此驱动器使用 IO 线程。
最大读/写速度(以 MB/s 为单位)。
最大无阻塞读/写池(以 MB/s 为单位)。
最大读取速度(以 MB/s 为单位)。
最大无阻塞读取池(以 MB/s 为单位)。
最大写入速度(以 MB/s 为单位)。
最大无阻塞写入池(以 MB/s 为单位)。
驱动器的媒体类型。
队列数量。
是否考虑将驱动器用于复制作业。
读取错误操作。
驱动器是否只读。
是否使用 scsi-block 进行主机块设备的完全直通。
|
|
可能导致主机上的低位内存或高位内存碎片合并的 I/O 错误 |
强制驱动器的物理几何结构具有特定的扇区数。
驱动器报告的序列号,url 编码,最长 20 个字节。
将此本地管理的卷标记为在所有节点上可用。
|
|
此选项不会自动共享卷,它假定它已经共享了! |
磁盘大小。这纯粹是信息性的,没有任何效果。
控制 qemu 的快照模式功能。如果激活,对磁盘所做的更改是临时的且将在 VM 关闭时被丢弃。
是否将此驱动器公开为 SSD,而不是机械硬盘。
强制磁盘几何结构在 BIOS 的转换模式。
写入错误操作。
驱动器的全球名称(WWN),编码为 16 字节的 16 进制字符串,以 0x 作为前缀。
SCSI 控制器型号
cloud-init:为容器设置 DNS 搜索域。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
在 VM 内部创建一个串口设备(n 是 0 到 3),且直通主机的串口设备(例如 /dev/ttyS0),或创建一个 unix socket(使用 qm terminal 打开一个终端连接)。
|
|
如果您直通主机串口设备,则不再可能迁移此类机器 - 使用时要特别小心。 |
|
|
实验性的!用户报告此选项有问题。 |
用于 Auto-ballooning(自动增长)的内存共享量。数字越大,VM 获得的内存越多。数字与所有其他正在运行 VM 的权重有关。使用 0 禁用 Auto-ballooning(自动增长),Auto-ballooning(自动增长)通过 pvestatd 完成的。
指定 SMBIOS 类型 1 字段。
指示 SMBIOS 值是 base64 编码的标志
设置 SMBIOS1 系列字符串。
设置 SMBIOS1 制造商。
设置 SMBIOS1 产品 ID 。
设置 SMBIOS1 序列号。
设置 SMBIOS1 SKU 字符串。
设置 SMBIOS1 UUID 。
设置 SMBIOS1 版本。
CPU 数量。请改用 -sockets 选项。
CPU 插槽的数量。
为 SPICE 配置其他增强功能。
通过 SPICE 启用文件夹共享。需要在 VM 中安装 Spice-WebDAV 守护进程。
启用视频流。压缩检测到的视频流。
cloud-init:设置公共 SSH 密钥(每行一个密钥,OpenSSH 格式)。
设置实时时钟的初始日期。日期的有效格式是:'now' 或 2006-06-17T16:01:21 或 2006-06-17 。
启动和关机行为。Order 是一个定义常规启动顺序的正整数。关机执行相反的顺序。此外,您可以以秒为单位设置 up(增加)或 down(减少)的延迟,它指定在启动或停止下一个 VM 之前的延迟等待。
启用/禁用 USB 平板设备。此设备通常需要允许 VNC 使用绝对定位的鼠标,否则鼠标与普通 VNC 客户端会不同步。如果您在一台主机上运行大量仅控制台的来宾,您可以考虑禁用它来减少后台切换。如果您使用 spice(qm set <vmid> --vga qxl),默认情况下会关闭此功能。
VM 的标签。这只是元信息。
启用/禁用时间漂移修复。
启用/禁用模板。
配置一个用于存储 TPM 状态的磁盘。使用特定语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。请注意,此处忽略 SIZE_IN_GiB,并且将始终使用默认大小 4 MB。格式也固定为 raw 。
驱动器的备份卷。
磁盘大小。这纯粹是信息性的,没有任何效果。
TPM 接口版本。应该首选较新的 v2.0 。请注意,之后无法更改。
引用未使用的卷。这是内部使用的,不应手动修改。
驱动器的备份卷。
配置一个 USB 设备(n 是 0 到 4)。
主机 USB 设备或端口,或值是 spice 。HOSTUSBDEVICE 语法是:
'bus-port(.port)*' (decimal numbers) or 'vendor_id:product_id' (hexadeciaml numbers) or 'spice'
您可以使用 lsusb -t 命令列出现有的 USB 设备。
|
|
此选项允许直接访问主机硬件。因此不再可能迁移此类机器 - 使用时要特别小心。 |
值 spice 可用于为 spice 添加 USB 重定向设备。
指定给定的主机选项是 USB3 设备还是端口。
热插拔 vcpus 的数量。
配置 VGA 硬件。如果您想要使用高分辨率模式(>= 1280x1024x16),您可能需要增加 vga 内存选项。从 QEMU 2.9 开始,除了一些使用 cirrus 的 Windows 版本(XP 或更早版本),所有操作系统的默认 VGA 显示类型都是 std 。qxl 选项启用 SPICE 显示服务器。对于 win* 操作系统,您可以选择所需的独立显示器,Linux 来宾也可以自行添加显示器。您还可以在无任何显卡的情况下运行,使用一个串行设备作为终端。
设置 VGA 内存(以 MB 为单位)。对串行显示没有影响。
选择 VGA 类型。
使用卷作为 VIRTIO 硬盘(n 为 0 到 15)。使用特殊语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。
要使用的 AIO 类型。
进行备份时是否应包括驱动器。
最大读/写速度(以 字节数/每秒 为单位)。
I/O 突发的最大长度(以秒为单位)。
最大读取速度(以 字节数/每秒 为单位)。
读取 I/O 突发的最大长度(以秒为单位)。
最大写入速度(以 字节数/每秒 为单位)。
写入 I/O 突发的最大长度(以秒为单位)。
驱动器的缓存模式
强制驱动器的物理几何结构具有特定的柱面数。
控制是否检测并尝试优化零写入。
控制是否将丢弃/修剪(discard/trim)请求传递给底层存储。
驱动器的备份卷。
驱动器的备份文件的数据格式。
强制驱动器的物理几何结构具有特定的磁头数。
最大每秒读写操作次数。
最大无阻塞读/写 I/O 池的每秒操作数。
I/O 突发的最大长度(以秒为单位)。
最大读取 I/O 的每秒操作数。
最大无阻塞读取 I/O 池的每秒操作数。
读取 I/O 突发的最大长度(以秒为单位)。
最大写入 I/O 的每秒操作数。
最大无阻塞写入 I/O 池的每秒操作数。
写入 I/O 突发的最大长度(以秒为单位)。
是否为此驱动器使用 IO 线程。
最大读/写速度(以 MB/s 为单位)。
最大无阻塞读/写池(以 MB/s 为单位)。
最大读取速度(以 MB/s 为单位)。
最大无阻塞读取池(以 MB/s 为单位)。
最大写入速度(以 MB/s 为单位)。
最大无阻塞写入池(以 MB/s 为单位)。
驱动器的媒体类型。
是否考虑将驱动器用于复制作业。
读取错误操作。
驱动器是否只读。
强制驱动器的物理几何结构具有特定的扇区数。
驱动器报告的序列号,url 编码,最长 20 个字节。
将此本地管理的卷标记为在所有节点上可用。
|
|
此选项不会自动共享卷,它假定它已经共享了! |
磁盘大小。这纯粹是信息性的,没有任何效果。
控制 qemu 的快照模式功能。如果激活,对磁盘所做的更改是临时的且将在 VM 关闭时被丢弃。
强制磁盘几何结构在 BIOS 的转换模式。
写入错误操作。
VM generation ID (vmgenid) 设备向来宾操作系统公开一个 128 位整数值标识符。这允许在虚拟机以不同的配置执行(例如执行快照或从模板创建)时通知来宾操作系统。来宾操作系统注意到变化,然后能够通过将其分布式数据库副本标记为过期(dirty)、重新初始化它的随机数生成器等来做出适当的反应。请注意,自动创建仅在通过 API/CLI 创建或更新方式完成时有效,但在手动编辑配置文件时无效。
VM 状态卷/文件的默认存储。
创建一个虚拟硬件监控设备(watchdog)。一旦启用(通过来宾操作),监控设备(watchdog)必须由来宾内部的代理定期轮询,否则监控设备(watchdog)将重置来宾(或执行指定的相关操作)。
如果激活后访客未能及时轮询监控设备(watchdog),则要执行的操作。
要模拟的监控设备(watchdog)类型。
在线迁移、快照和备份(vzdump)设置为锁定,以防止受影响 VM 上的不兼容并发操作。有时您需要手动移除这样的锁定(例如,在电源故障后)。
# qm unlock <vmid>
|
|
仅当您确定设置锁定的操作不再运行时才执行此操作。 |
容器是完全虚拟化机器(VM)的轻量级替代品。它们使用运行它们的主机系统的内核,而不是模拟完整的操作系统(OS)。这意味着容器可以直接访问主机系统上的资源。
容器的运行成本很低,通常可以忽略不计。但是,有一些缺点需要考虑:
Proxmox 容器中只能运行 Linux 发行版。无法在容器中运行其它操作系统,例如 FreeBSD 或者 Microsoft Windows。
出于安全原因,需要限制对主机资源的访问。因此,容器在它们自己独立的命名空间中运行。此外,容器内不允许某些系统调用(对 Linux 内核的用户空间请求)。
Proxmox VE 使用 Linux Containers (LXC) 作为它的底层容器技术。“Proxmox Container Toolkit(Proxmox 容器工具箱,简称 pct)”通过一个分离复杂任务的接口,来简化 LXC 的使用与管理。
容器与 Proxmox VE 紧密集成。这意味着它们可以感知到集群的设置,并且可以使用与虚拟机相同的网络和存储资源。您还可以使用 Proxmox VE 防火墙,或使用 HA 框架管理容器。
我们的主要目标是提供一个可以发挥 VM 优势的环境,但不需要额外的开销。这意味着 Proxmox 容器可以归类为“系统容器”,而不是“应用程序容器”。
|
|
如果要运行应用程序容器,例如 Docker 镜像,建议在 Proxmox Qemu VM 内运行它们。这将为您提供应用程序容器化的所有优势,同时还提供 VM 可以提供的好处,例如与主机的强隔离和实时迁移的能力,除了容器之外是不可能实现的。 |
官方支持的发行版列表可以在下面找到。
以下发行版的模板可通过我们的存储库获得。您可以使用 pveam 工具或者图形用户界面下载它们。
Alpine Linux 是一个基于 musl libc 和 busybox 的面向安全的轻量级 Linux 发行版。
有关当前支持的版本,请参阅:
Arch Linux,一个试图保持简单、轻量级且灵活的 Linux® 发行版。
Arch Linux 正在使用滚动发布模型,请参阅其 wiki 了解更多详细信息:
CentOS Linux 发行版是一个稳定、可预测、可管理和可复制的平台,源自 Red Hat Enterprise Linux (RHEL)
有关当前支持的版本,请参阅:
一个开源、社区拥有和治理、永久免费的企业 Linux 发行版,专注于长期稳定性,提供强大的生产级平台。AlmaLinux 操作系统与 RHEL® 和 pre-Stream CentOS 1:1 二进制兼容。
有关当前支持的版本,请参阅:
Rocky Linux是一款社区企业操作系统,其设计目的是在其下游合作伙伴已经改变方向的情况下,与美国顶级企业Linux发行版完全兼容。
有关当前支持的版本,请参阅:
Debian 是一个免费的操作系统,由 Debian 项目开发和维护。一个免费的 Linux 发行版,包含数以千计的应用程序来满足我们用户的需求。
有关当前支持的版本,请参阅:
Devuan GNU+Linux 是 Debian 的一个分支,没有 systemd,它允许用户通过避免不必要的纠缠和确保 Init Freedom 来重新控制他们的系统。
有关当前支持的版本,请参阅:
Fedora 为硬件、云和容器创建了一个创新、免费和开源的平台,使软件开发人员和社区成员能够为其用户构建量身定制的解决方案。
有关当前支持的版本,请参阅:
制造商为系统管理员、开发人员和桌面用户提供的选择。
有关当前支持的版本,请参阅:
Ubuntu 是 Linux上用于企业服务器、桌面、云和物联网的现代开源操作系统。
有关当前支持的版本,请参阅:
Container 镜像,有时也被称为“模板”或“器具”,是包含运行容器的所有内容的 tar 归档文件。
Proxmox VE 本身为最常见的 Linux 发行版提供了各种基本的模板。它们可以使用 GUI 或 pveam(Proxmox VE Appliance Manager 的缩写)命令行实用程序下载。 此外,TurnKey Linux 的容器模板也可以下载。
可用模板列表每天通过 pve-daily-update 计时器定时更新。您也可以通过执行以下操作手动触发更新:
# pveam update
要查看可用镜像的列表,请运行:
# pveam available
您可以通过指定您感兴趣的内容(--section)来限制这个大列表,例如基本系统镜像:
# pveam available --section system system alpine-3.12-default_20200823_amd64.tar.xz system alpine-3.13-default_20210419_amd64.tar.xz system alpine-3.14-default_20210623_amd64.tar.xz system archlinux-base_20210420-1_amd64.tar.gz system centos-7-default_20190926_amd64.tar.xz system centos-8-default_20201210_amd64.tar.xz system debian-9.0-standard_9.7-1_amd64.tar.gz system debian-10-standard_10.7-1_amd64.tar.gz system devuan-3.0-standard_3.0_amd64.tar.gz system fedora-33-default_20201115_amd64.tar.xz system fedora-34-default_20210427_amd64.tar.xz system gentoo-current-default_20200310_amd64.tar.xz system opensuse-15.2-default_20200824_amd64.tar.xz system ubuntu-16.04-standard_16.04.5-1_amd64.tar.gz system ubuntu-18.04-standard_18.04.1-1_amd64.tar.gz system ubuntu-20.04-standard_20.04-1_amd64.tar.gz system ubuntu-20.10-standard_20.10-1_amd64.tar.gz system ubuntu-21.04-standard_21.04-1_amd64.tar.gz
在您可以使用这样的模板之前,您需要将它们下载到您的一个存储中。如果您不确定是哪一个,您可以简单的使用以 local 命名的存储。对于集群安装,最好使用共享存储,以便所有节点都可以访问这些镜像。
# pveam download local debian-10.0-standard_10.0-1_amd64.tar.gz
您现在已准备好使用该镜像创建容器,可以使用以下命令列出 local 存储上的所有下载镜像:
# pveam list local local:vztmpl/debian-10.0-standard_10.0-1_amd64.tar.gz 219.95MB
|
|
您还可以使用 Proxmox VE Web 界面 GUI 来下载、列出和删除容器模板。 |
pct 使用它们来创建一个新的容器,例如:
# pct create 999 local:vztmpl/debian-10.0-standard_10.0-1_amd64.tar.gz
上面的命令显示了完整的 Proxmox VE 卷标识符。它们包括存储名称,大多数其他 Proxmox VE 命令可以使用它们。例如,您可以稍后删除该镜像:
# pveam remove local:vztmpl/debian-10.0-standard_10.0-1_amd64.tar.gz
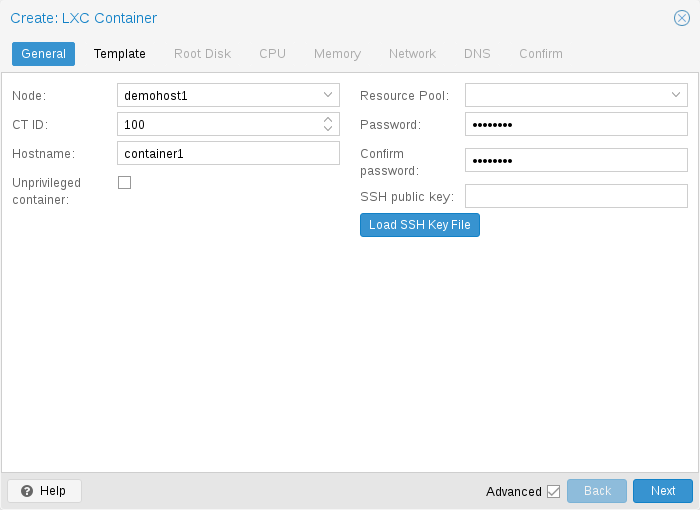
容器的常规设置包括:
节点:将要运行容器的物理服务器
CT ID:这是 Proxmox VE 安装中的唯一编号,用于识别您的容器。
主机名:容器的主机名
资源池:容器和 VM 的逻辑组
密码:容器的 root 密码
SSH 公钥:用于通过 SSH 连接到 root 帐户的公钥
无特权的容器:此选项允许在创建时选择是否要创建特权或非特权的容器。
无特权的容器使用称为用户命名空间的新内核功能。容器内的 root UID 0 映射至容器外的无特权用户。这意味着这些容器中的大多数安全问题(容器逃逸、资源滥用等)都会影响一个随机的无特权用户,并且这是一个通用的内核安全缺陷,而不是 LXC 的问题。LXC 团队认为无特权的容器在设计上是安全的。
这是创建新容器时的默认选项。
|
|
如果使用 systemd 做为容器的 init 系统程序,请注意容器内运行的 systemd 版本应等于或大于 220。 |
通过使用强制访问控制 AppArmor 限制、seccomp 过滤器和 Linux 内核命名空间来实现容器中的安全。LXC 团队认为这种容器是不安全的,他们不认为新的容器逃逸漏洞是值得 CVE(通用漏洞披露,Common Vulnerabilities and Exposures 的英文缩写) 和快速修复的安全问题。这就是为什么特权的容器应该只在受信任的环境中使用的原因。
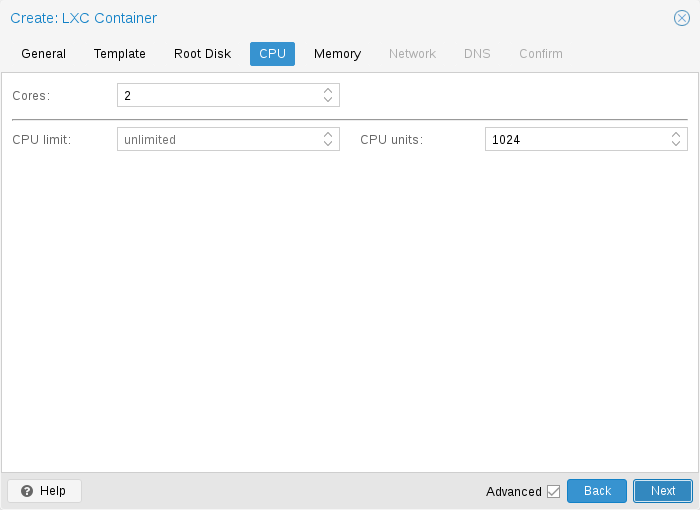
您可以通过使用 核心 选项限制容器内可见 CPU 的数量。这是使用 Linux 的 cpuset cgroup(control group,控制组)实现的。pvestatd 的一项特殊任务是尝试定期在可用 CPU 之间分配正在运行的容器。要查看分配的 CPU,请运行以下命令:
# pct cpusets --------------------- 102: 6 7 105: 2 3 4 5 108: 0 1 ---------------------
容器直接使用主机核心。容器内的所有任务都由主机 CPU 调度程序处理。Proxmox VE 使用 Linux CFS(Completely Fair Scheduler,完全公平调度程序)作为默认的调度程序,它有额外的带宽控制选项。
|
CPU 限制: |
您可以使用此选项进一步限制分配的 CPU 时间。请注意,这是一个浮点数,因此将两个核心分配给一个容器是非常合理的,只是 CPU 的整体消耗量将被限制为半个核心。例如下列的设定: 核心:2 # 说明容器的核心分配 2 个。 CPU 限制:0.5 # 即 CPU 整体的一半。 |
|
CPU 权重: |
这是传递给内核调度程序的相对权重。数字越大,此容器获得的 CPU 时间越多。数字是相对于所有其它正运行的容器的权重。默认值为 1024,您可以使用此设置来调整某些容器的优先级。 |
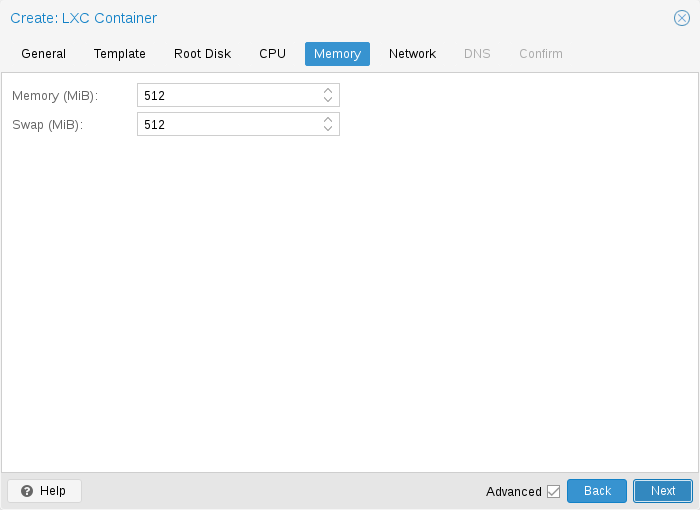
容器内存使用 cgroup 内存控制器进行控制。
|
内存: | 限制整体内存使用。这对应于 cgroup 设置的 memory.limit_in_bytes。 |
| swap 交换分区: |
允许容器使用额外的来自主机 swap 交换空间的 swap(交换)内存,这相当于 cgroup 设置的 memory.memsw.limit_in_bytes,它设定为两个值的总和(内存 + swap(交换空间))。 |
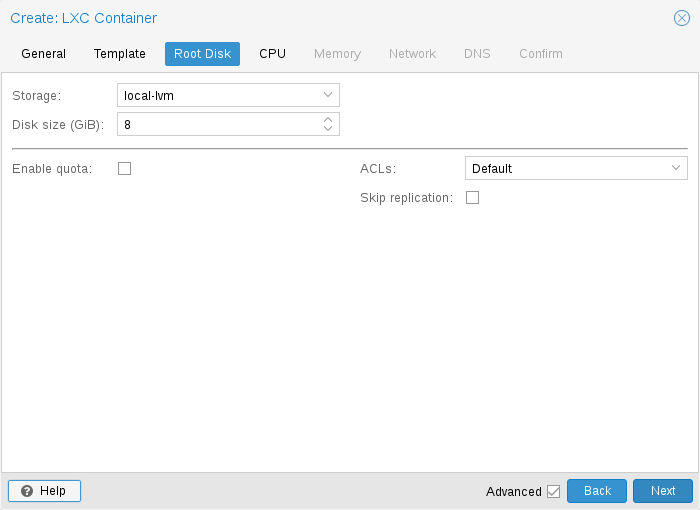
root 的挂载点是通过 rootfs 属性配置的。您最多可以配置 256 个附加的挂载点。这相应的选项的名称为从 mp0 到 mp255。它们包含以下设定:
使用卷作为容器 root ,有关所有选项的详细说明,请参见下文。
使用卷作为容器挂载点,要对分配的新卷使用特殊的语法 STORAGE_ID:SIZE_IN_GiB 。
明确地启用或禁用 ACL 支持。
是否在备份中包含挂载点(仅用于卷挂载点)。
rootfs/mps 的额外挂载选项。
从容器内部看到的挂载点路径。
|
|
出于安全原因,不得包含任何符号链接。 |
在容器内启用用户配额(quota)(zfs子卷不支持)
将此卷包含到存储复制任务中。
只读挂载点。
将此非卷挂载点标记为在所有节点上可用。
|
|
该选项不会自动共享挂载点,它假设它已经共享了! |
卷大小(只读值)。
要挂载到容器中的卷、设备或目录
目前有三种类型的挂载点:存储支持的挂载点、绑定挂载和设备挂载。
rootfs: thin1:base-100-disk-1,size=8G
存储支持的挂载点由 Proxmox VE 存储子系统管理,分为三种不同的风格:
基于映像:这些是包含单个 ext4 格式文件系统的 raw 映像。
ZFS 子卷:这些在技术上是绑定挂载,但具有托管存储,因此允许调整大小和快照。
目录:传递 size=0 会触发一个特殊情况,即创建目录而不是 raw 映像。
|
|
为存储支持的挂载点卷使用特殊的选项语法 STORAGE_ID:SIZE_IN_GB,将自动在指定的存储上分配指定大小的卷。例如,调用以下命令: |
pct set 100 -mp0 thin1:10,mp=/path/in/container
将在存储 thin1 上分配一个 10GB 的卷,并用分配的卷 ID 替换卷 ID 占位符 10,并在 /path/in/container 的容器中设置挂载点。
绑定挂载允许从您 Proxmox VE 主机内的容器访问任意目录,一些可能的实例如:
在来宾(容器)中访问您的 home 目录。
在来宾(容器)中访问一个 USB 设备。
在来宾(容器)中访问一个来自主机的 NFS 挂载
绑定挂载被认为不是由存储子系统管理的,因此您无法从容器内部创建快照或处理配额。对于非特权的容器,您可能会遇到因用户映射引起的权限问题和无法使用 ACL。
|
|
使用 vzdump 时不会备份绑定挂载点的内容。 |
|
|
出于安全原因,用于绑定挂载的源目录,确认仅能使用为此目的而保留的目录(例如,位于 /mnt/bindmounts 下的目录结构)。切勿绑定挂载系统目录(如 /、/var 或 /etc)到容器中 - 这会带来很大的安全风险。 |
|
|
绑定挂载的源路径不得包含任何符号链接。 |
例如,想要让 ID 为 100 的容器下的路径 /shared 可以访问目录 /mnt/bindmounts/shared,在 /etc/pve/lxc/100.conf 里使用配置一行 mp0: /mnt/bindmounts/shared,mp=/shared ,或者,使用 pct set 100 -mp0 /mnt/bindmounts/shared,mp=/shared 来获得相同的结果。
设备挂载点允许直接挂载主机的块设备到容器中。与绑定挂载类似,设备挂载不由 Proxmox VE 的存储子系统管理,但需要遵循 quota 和 acl 选项。
|
|
设备挂载点只能在特殊情况下使用。在大多数情况下,存储支持的挂载点提供相同的性能和更多的功能。 |
|
| 使用 vzdump 时不备份设备挂载点的内容。 |
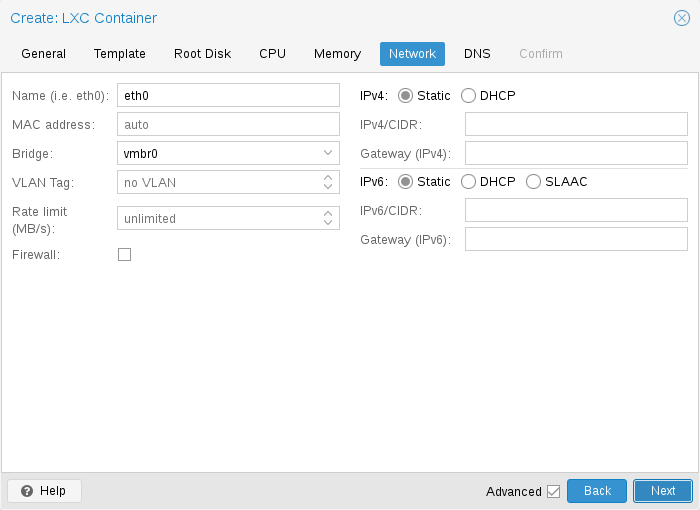
您最多可以为单个容器配置 10 个网络接口,相应的选项的名称从 net0 到 net9,且它们可以包含以下设置:
为容器指定网络接口。
指定用于连接网络设备的网桥(Bridge)。
控制是否此使用此接口的防火墙规则。
用于 IPv4 通信的默认网关。
用于 IPv6 通信的默认网关。
未设置 I/G(Individual/Group)位的通用MAC地址。
CIDR 格式的 IPv4 地址。
CIDR 格式的 IPv6 地址。
接口的最大传输单位(MTU)。( lxc.network.mtu )
从容器内部看到的网络设备的名称。( lxc.network.name )
对接口应用速率限制
此接口的 VLAN 标签(tag)。
通过接口的 VLAN ID
网络接口类型。
要在主机系统启动时自动启动容器,请在 Web 界面中对应容器的 选项 面板,选择 开机自启动 选项或运行以下命令:
# pct set CTID -onboot 1
如果您想要调整容器的启动顺序,您可以使用以下参数:
启动/关机顺序:定义启动顺序的优先级。例如,如果您想要此 CT 第一个启动,则将其设置为 1 。(我们为关机使用与启动 相反 的顺序,因此启动顺序为 1 的容器会 最后 关机。)
启动延时:定义启动当前容器与启动后续容器之间的间隔。例如,如果需要在启动其它容器前等待 240 秒,则将其设置为 240。
关机超时:定义 Proxmox VE 在发出关机命令后等待容器离线的持续时间(以秒为单位)。默认情况下,该值设定为 60,这意味着 Proxmox VE 会发出关机请求,等待 60 秒让机器离线,如果 60 秒后机器仍然在线,会通知关机动作失败。
请注意,没有设置启动/关机顺序参数的容器将始终在那些设置了该参数的容器之后启动,并且此参数仅作用于在主机上本地运行的机器之间,而不是作用于集群范围。
I如果您需要设定主机启动和第一个容器启动之间的延时,请参阅 Proxmox VE 节点管理 部分。
您可以通过配置 hookscript 属性,添加一个挂钩脚本到 CT 。
# pct set 100 -hookscript local:snippets/hookscript.pl
它将在来宾(容器)生命周期的各个阶段调用。有关范例和文档,请参阅 /usr/share/pve-docs/examples/guest-example-hookscript.pl 下的范例脚本。
容器使用主机系统的内核,这为恶意用户暴露了攻击面。一般来说,完整的虚拟机提供更好的隔离。如果将容器提供给未知或不受信任的人,则应考虑这一点。
为了减少攻击面,LXC 使用了许多安全功能,如 AppArmor、CGroups 和内核命名空间。
AppArmor 配置文件用于限制对可能的危险动作的访问。禁止执行部分系统调用,比如 mount。
要跟踪 AppArmor 活动,请使用:
# dmesg | grep apparmor
尽管不建议这样做,但是可以为容器禁用 AppArmor,这会带来安全风险。如果系统配置错误,或者如果存在 LXC 或 Linux 内核漏洞,则某些系统调用在容器内执行时可能会导致权限提升。
要禁用容器的 AppArmor,请添加以下行到容器的配置文件 /etc/pve/lxc/CTID.conf 中:
lxc.apparmor.profile = unconfined
|
|
请注意,不建议将其用于生产用途。 |
cgroup 是一种内核机制,用于层级化组织进程和分配系统资源。
通过 cgroups 控制的主要资源是 CPU 时间、内存和交换限制以及对设备节点的访问。 cgroups 还可以用于生成快照前“冻结”容器。
从 Proxmox VE 7.0 开始,默认就是纯 cgroupv2 环境。以前使用的是“混合”设置,其中资源控制主要在 cgroupv1 中完成,并带有一个额外的 cgroupv2 控制器,它可以通过 cgroup_no_v1 内核命令行参数接管一些子系统。(有关详细信息,请参阅 内核参数文档。)
至于 Proxmox VE 的纯 cgroupv2 和旧版的混合环境之间的主要区别在于 cgroupv2 是独立控制内存和交换空间的。容器的内存和交换空间设定可以直接映射到这些值,而之前仅能限制 内存限制 与 内存和交换空间总和的限制。
另一个重要的区别是 设备 控制器的配置方式完全不同。因此,目前在纯 cgroupv2 环境中不支持文件系统配额。
在纯 cgroupv2 环境中运行需要容器的操作系统支持 cgroupv2。运行 systemd 231 或更新版本的容器均支持 cgroupv2
[这包括 Proxmox VE 提供的所有最新主要版本的容器模板]
,不使用 systemd 作为 init 系统程序
[例如 Alpine Linux]
的容器也是如此。
|
|
CentOS 7 和 Ubuntu 16.10 是两个著名的 Linux 发行版,它们的 systemd 版本太旧而无法在 cgroupv2 环境中运行,您可以
|
|
|
如果不需要文件系统配额并且所有容器都支持 cgroupv2,则建议坚持使用新的默认值。 |
要切换回以前的版本,可以使用以下内核命令行参数:
systemd.unified_cgroup_hierarchy=0
有关在何处添加参数的编辑内核引导命令行,请参阅 此章节 。
Proxmox VE 尝试检测容器内的 Linux 发行版,并修改一些文件。以下是容器启动时所做工作的简短列表:
设置容器的名称
允许查找本地主机名
将完整的网络设置传递给容器
传递有关 DNS 服务器的信息
例如,修复生成的 getty 进程的数量
在创建容器时
这样每个容器都有唯一的密钥
以便 cron 不会在所有容器上同时启动
Proxmox VE 所做的更改包含在注释标记中:
# --- BEGIN PVE --- <data> # --- END PVE ---
这些标记将插入文件中的合理位置。如果这样的部分已经存在,它将就地更新并且不会被移动。
通过为它添加 .pve-ignore. 文件来防止文件被修改。例如,如果存在 /etc/.pve-ignore.hosts 文件,则 /etc/hosts 文件不可被修改,这可以通过以下方式简单的创建一个空文件:
# touch /etc/.pve-ignore.hosts
大多数修改都依赖于操作系统,因此它们在不同的发行版和版本之间有所不同。您可以通过手动设置 OS 类型(ostype) 为 unmanaged (非托管) 来完全禁用修改。
操作系统类型检测是通过测试容器内的某些文件来完成的。Proxmox VE 首先检查 /etc/os-release 文件
[/etc/os-release 取代了每个发行版本的 release 文件 https://manpages.debian.org/stable/systemd/os-release.5.en.html]
。如果该文件不存在,或者它不包含清楚识别的分发标识符,则会检查以下特定的 release 文件。
检查 /etc/lsb-release (DISTRIB_ID=Ubuntu)
测试 /etc/debian_version
测试 /etc/fedora-release
测试 /etc/redhat-release
测试 /etc/arch-release
测试 /etc/alpine-release
测试 /etc/gentoo-release
|
|
如果配置的 OS 类型(ostype) 与自动检测的类型不同,则容器启动失败。 |
Proxmox VE LXC 容器存模型比传统容器存储模型更加灵活。一个容器可以有多个挂载点。这将可以为每个应用程序使用最合适的存储。
例如容器的 root 文件系统可以放在缓慢且廉价的存储上,而数据库可以通过第二个挂载点放在快速且分布式存储上。了解更多详细信息,请参阅 挂载点 章节。
可以使用 Proxmox VE 存储库支持的任何存储类型。这意味着容器可以存储在本地(例如 lvm、zfs 或目录)、外部共享(如 iSCSI、NFS)甚至是分布式存储系统(如 Ceph)上。如果底层存储支持,它们还可以使用快照或克隆等高级存储功能。备份工具 vzdump 可以使用快照为容器提供持续的备份。
此外,可以使用 bind mounts(绑定挂载) 直接挂载本地设备或本地目录,这使得在容器内访问本地资源几乎零开销。Bind mounts(绑定挂载)可以作为在容器之间共享数据的简单方法。
|
|
由于 Linux 内核的 freezer 子系统中存在问题,强烈建议不要在容器内使用 FUSE 挂载,因为进行挂起或快照模式备份时需要冻结容器。 |
如果 FUSE 挂载不能被其他挂载机制或存储技术替代,则可以在 Proxmox 主机上建立 FUSE 挂载,并使用绑定挂载点使其在容器内可访问。
配额允许在容器内为每个用户可以使用的磁盘空间量设置限制。
|
|
当前这需要使用旧版 cgroups 。 |
|
|
这仅适用于基于 ext4 映像的存储类型,目前仅适用于有特权的容器。 |
激活 quota(配额) 选项会导致以下挂载选项被用于挂载点: usrjquota=aquota.user,grpjquota=aquota.group,jqfmt=vfsv0
这允许像在任何其他系统上一样使用配额,您可以通过运行以下命令来初始化 /aquota.user 和 /aquota.group 文件:
# quotacheck -cmug / # quotaon /
然后使用 edquota 命令编辑配额。有关详细信息,请参阅容器内运行的分发的文档。
|
|
您需要通过传递挂载点的路径为每个挂载点运行上述命令,而不是仅用 /代替。 |
标准的 Posix ACL(Access Control Lists,访问控制列表)也可在容器内使用。ACL 允许您设置比传统的用户/组/其他模型更详细的文件所有权。
要在备份中包含挂载点,请在容器配置中为其启用 备份 选项。对于现有的挂载点 mp0
mp0: guests:subvol-100-disk-1,mp=/root/files,size=8G
添加 backup=1 以启用它。
mp0: guests:subvol-100-disk-1,mp=/root/files,size=8G,backup=1
|
|
在 GUI 中创建新的挂载点时,默认情况下启用此选项。 |
要禁用挂载点的备份,请按上述方式添加 backup=0,或者取消选中在 GUI 上的 备份 复选框。
默认情况下,当复制 Root 磁盘时会同时复制附加的挂载点。如果您希望 Proxmox VE 存储复制机制跳过一个挂载点,您可以为此挂载点设定 跳过复制 选项。从 Proxmox VE 5.0 开始,复制需要 zfspool 类型的存储。当容器配置了复制时,将挂载点添加到不同类型的存储需要为该挂载点启用 跳过复制 选项。
可以为容器备份使用 vzdump 工具。有关详细信息,请参阅 vzdump 手册页。
可以使用 pct restore 命令还原使用 vzdump 制作的容器备份。默认情况下,pct restore 将尝试尽可能多的恢复备份的容器配置。可以通过在命令行上手动设置容器选项来覆盖备份的配置(有关详细信息,请参阅 pct 手册页)。
|
|
pvesm extractconfig 可用于查看 vzdump 存档中包含的备份配置。 |
有两种基本的恢复模式,区别仅在于它们对挂载点的处理:
如果未明确设定 rootfs 参数,也没有任何可选的 mpX 参数,则使用下列步骤从备份的配置文件中恢复挂载点的配置:
从备份中提取挂载点及其选项
在 存储 参数提供的存储上为存储备份挂载点创建卷(默认值:local)。
从备份存档中提取文件
将绑定和设备挂载点添加到恢复的配置(仅限于 root 用户)
|
|
由于从不备份绑定点和设备挂载点,因此在最后一步中不会恢复任何文件,只会恢复配置选项。假设是这样的挂载点要么用另一种机制备份(例如,绑定挂载到许多容器中的 NFS 空间),要么根本不打算备份。 |
在 Web 界面中的容器恢复操作也是使用这个简单模式。
通过设置 rootfs 参数(以及可选的 mpX 参数的任意组合),pct restore 命令将自动切换到高级模式。高级模式完成忽略备份存档中包含的 rootfs 和 mpX 配置选项,且只能使用明文规定的作为参数的选项。
This mode allows flexible configuration of mount point settings at restore time, for example:
分别为每个挂载点设置目标存储、卷大小和其他选项
根据新的挂载点方案重新分发备份文件
恢复到设备和(或)绑定挂载点(仅限于 root 用户)
pct (“Proxmox Container Toolkit”,Proxmox 容器工具箱 ) 是用于管理 Proxmox VE 容器的命令行工具。它使您能够创建或销毁容器,以及控制容器的执行(启动、停止、重启、迁移等)。它可用于在容器的配置文件中设置参数,例如网络配置或内存限制。
创建基于 Debian 模板的容器(前提是您已经通过 Web 界面下载了模板)
# pct create 100 /var/lib/vz/template/cache/debian-10.0-standard_10.0-1_amd64.tar.gz
启动 ID 为 100 的容器
# pct start 100
通过 getty 启动登录会话
# pct console 100
进入 LXC 命名空间并以 root 用户身份运行 shell
# pct enter 100
显示配置
# pct config 100
在它运行时,添加一个名为 eth0 的网络接口,桥接到主机网桥 vmbr0,并设置地址和网关。
# pct set 100 -net0 name=eth0,bridge=vmbr0,ip=192.168.15.147/24,gw=192.168.15.1
将容器的内存减少到 512MB
# pct set 100 -memory 512
销毁容器始终会将其从访问控制列表 ACL 中删除,并且始终会删除容器的防火墙配置。如果您同时想从复制任务、备份任务和 HA 资源配置中移除容器,您必须激活 --purge 。
# pct destroy 100 --purge
将挂载点卷移动到不同的存储。
# pct move-volume 100 mp0 other-storage
将卷重新分配给不同的 CT。这将从源 CT 中删除卷 mp0,并将其作为 mp1 附加到目标 CT。在后台,重命名卷的名称以便其与新的所有者相匹配。
# pct move-volume 100 mp0 --target-vmid 200 --target-volume mp1
如果 pct start 无法启动特定的容器,通过传递 --debug 标志(使用容器的 CTID 替换以下命令中的 CTID),可能会对收集调试输出有所帮助:
# pct start CTID --debug
或者,您可以使用以下 lxc-start 命令,它将调试日志保存到 -o 输出选项指定的文件中:
# lxc-start -n CTID -F -l DEBUG -o /tmp/lxc-CTID.log
此命令将尝试以前台模式启动容器,在第二个终端中运行 pct shutdown CTID 或 pct stop CTID 命令来停止容器。
收集的调试日志写入 /tmp/lxc-CTID.log。
|
|
如果自上次使用 pct start 尝试启动后更改了容器的配置,则需要至少运行一次 pct start 以更新 lxc-start 使用的配置。 |
如果您有集群,则可以使用以下命令迁移容器
# pct migrate <ctid> <target>
只要在您的容器处于离线状态时就会起作用,如果它定义了本地卷或挂载点,且目标主机定义了相同的存储,迁移将会通过网络将内容复制到目标主机。
运行中的容器由于技术限制而无法实时迁移,您可以执行 重启迁移,它会关闭、移动,然后在目标节点中再次启动容器。由于容器非常轻量级,这通常只会导致数百毫秒的停机时间。
重启迁移 可以通过 Web 界面或使用带有 --restart 标志的 pct migrate 命令来完成。
重启迁移 将关闭容器并在指定的超时(默认值是 180 秒)后结束(kill)它。然后它将像离线迁移一样迁移容器,完成后,它会目标节点上启动容器。
The /etc/pve/lxc/<CTID>.conf 文件用于存储容器配置,其中 <CTID> 是特定容器的数字 ID 。与存储在 /etc/pve/ 中的所有其他文件一样,它们会自动复制到所有其他集群节点。
|
|
小于 100 的 CTID 是保留用于内部用途,且 CTID 需要在集群范围内是唯一的。 |
ostype: debian arch: amd64 hostname: www memory: 512 swap: 512 net0: bridge=vmbr0,hwaddr=66:64:66:64:64:36,ip=dhcp,name=eth0,type=veth rootfs: local:107/vm-107-disk-1.raw,size=7G
配置文件是简单的文本文件。您可以使用普通的文本编辑器编辑它们,例如,vi 或 nano。这有时对做些小修改很有用,但请记住,您需要重新启动容器才能应用此类更改。
出于这个原因,通常最好使用 pct 命令来生成和修改这些文件,或者使用 GUI 完成整个操作。我们的工具足够智能,可以立即将大部分更改应用于正在运行的容器。这个功能被称为“热插拔”,这种情况下不需要重启容器。
在无法热插拔更改的情况下,它将被登记为挂起的更改(在 GUI 中以红色显示)。它们只会在重新启动容器后应用。
容器配置文件使用简单的格式,键和值使用冒号分隔(如 key:value)。每行有以下的格式:
# 这是一个注释 OPTION: value
这些文件中的空白行被忽略,以 # 字符开头的行被视为注释,也同样被忽略。
可以直接添加初级(low-level) LXC 样式的配置,例如:
lxc.init_cmd: /sbin/my_own_init
或者
lxc.init_cmd = /sbin/my_own_init
这些设置直接传递给 LXC 低级(low-level)工具。
创建快照时,pct 在生成快照时将配置存储到具有相同配置文件的单独快照部分中。例如,创建一个名为 “testsnapshot”的快照后,您的配置文件将如下所示:
memory: 512 swap: 512 parent: testsnaphot ... [testsnaphot] memory: 512 swap: 512 snaptime: 1457170803 ...
有一些与快照相关的属性,例如 parent 和 snaptime。parent 属性用于存储快照之间的父/子关系。snaptime 是快照创建的时间戳(Unix 纪元)。
操作系统架构类型。
console(控制台)模式。默认情况下,console(控制台)命令将尝试打开一个可用的 tty 设备的连接。通过将 cmode 设置为 console(控制台),它会尝试连接到 /dev/console 。如果设置 cmode 为 shell,它只会调用容器内的 shell(无需登录)。
将控制台设备 (/dev/console) 附加到容器。
给容器分配的核心数量。容器默认可以使用所有可用核心。
CPU 的使用限制 。
|
|
如果计算机有 2 个 CPU,它总共有 2 个 CPU 时间,值为 0 表示没有 CPU 限制。 |
VM 的 CPU 权重。参数是用于内核公平调试程序,这个数字越大,这个 VM 获得的 CPU 时间越多。该数字与所有其它正在运行的 VM 的权重相关。
|
|
您可以通过将其设置为 0 来禁用公平调度程序配置。 |
尝试获得更详细的调试日志。目前这仅在启动时启用调试日志级别。
容器的描述。显示在 Web 界面 CT 的摘要中。这被保存为配置文件中的注释。
允许容器访问高级功能。
在非特权的容器中将 /sys 挂载为 rw 而不是 mixed。这可能在较新的 systemd-network(>= v245) 使用下可能会中断网络。
允许在容器中使用 fuse 文件系统。请注意,fuse 和 freezer cgroup 之间的交互作用可能会导致 I/O 死锁。
仅适用于非特权的容器:允许使用 keyctl() 系统调用。这是在容器内使用 docker 所必需的。默认情况下,非特权的容器会将此系统调用视为不存在。这主要是 systemd-networkd 的一种解决方法,因为当某些 keyctl() 操作由于缺乏权限而被内核拒绝时,它会将其视为致命错误。本质上,您可以选择运行 systemd networkd 或 docker。
允许非特权的容器使用 mknod() 添加某些设备节点。这需要具有 seccomp 陷阱的内核以支持用户空间(5.3 或更高版本)。这是实验性的。
允许挂载特定类型的文件系统。这应该是与 mount 命令一起使用的文件系统类型列表。请注意,这会对容器的安全性产生负面影响。通过访问循环设备(loop device),挂载文件可以绕过设备 cgroup 的 mknod 权限,挂载 NFS 文件系统可以完全阻止主机的 I/O 并防止其重新启动等。
允许嵌套。最好与具有额外的 id 映射的非特权的容器一起使用。请注意,这会将主机 procfs 和 sysfs 的内容暴露给来宾(容器)。
将在容器生命周期的各个步骤中执行的挂钩脚本。
为容器设置主机名。
锁定/解锁 VM 。
VM 的内存值(以 MB 为单位)。
使用卷作为容器挂载点,要对分配的新卷使用特殊的语法 STORAGE_ID:SIZE_IN_GiB 。
明确地启用或禁用 ACL 支持。
是否在备份中包含挂载点(仅用于卷挂载点)。
rootfs/mps 的额外挂载选项。
从容器内部看到的挂载点路径。
|
|
出于安全原因,不得包含任何符号链接。 |
在容器内启用用户配额(quota)(zfs 子卷不支持)
将此卷包含到存储复制任务中。
只读挂载点
将此非卷挂载点标记为在所有节点上可用。
|
|
该选项不会自动共享挂载点,它假设它已经共享了! |
卷大小(只读值)。
要挂载到容器中的卷、设备或目录
为容器设置 DNS 服务器 IP 地址。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
为容器指定网络接口。
指定用于连接网络设备的网桥(Bridge)。
控制是否此使用此接口的防火墙规则。
用于 IPv4 通信的默认网关。
用于 IPv6 通信的默认网关。
未设置 I/G(Individual/Group)位的通用MAC地址。
CIDR 格式的 IPv4 地址。
CIDR 格式的 IPv6 地址。
接口的最大传输单位(MTU)。( lxc.network.mtu )
从容器内部看到的网络设备的名称。( lxc.network.name )
对接口应用速率限制
此接口的 VLAN 标签(tag)。
通过接口的 VLAN ID
网络接口类型。
指定是否在系统启动期间启动 VM 。
操作系统类型。这是用于设置容器内部的配置,对应于 /usr/share/lxc/config/<ostype>.common.conf 中的 lxc 设置脚本。值 unmanaged (非托管) 可用于跳过特定于操作系统的设置。
设置容器的保护标志。这将阻止 CT 或 CT 的磁盘删除/更新操作。
使用卷作为容器 root 。
明确地启用或禁用 ACL 支持。
rootfs/mps 的额外挂载选项。
在容器内启用用户配额(quota)(zfs 子卷不支持)
将此卷包含到存储复制任务中。
只读挂载点
将此非卷挂载点标记为在所有节点上可用。
|
|
该选项不会自动共享挂载点,它假设它已经共享了! |
卷大小(只读值)。
要挂载到容器中的卷、设备或目录。
为容器设置 DNS 服务器 IP 地址。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
启动和关机行为。顺序 是定义常规启动顺序的非负数字。按相反顺序关闭。此外,您可以以秒为单位设置向上或向下的延时,它指定在启动或停止下一个 VM 之前等待的一个延时。
VM 的交换空间的数值(以 MB 为单位)。
容器的标签。这只是元信息。
启用/禁用模板。
要在容器中使用的时区。如果没有设置选项,则不会执行任何操作。可以设置为 host(主机)以匹配主机时区,或来自 /usr/share/zoneinfo/zone.tab 的任意时区选项。
指定容器可用的 tty 数量
使容器以非特权的用户身份运行。(不应手动修改。)
引用未使用的卷。这是内部使用的,不应手动修改。
当前未使用的卷。
容器迁移、快照和备份(vzdump)设置为锁定,以防止受影响容器上的不兼容并发操作。有时您需要手动移除这样的锁定(例如,在电源故障后)。
# pct unlock <CTID>
|
|
仅当您确定设置锁定的操作不再运行时才执行此操作。 |
软件定义网络(Software Defined Network (SDN))的功能是允许创建一个数据中心级别的虚拟网络(vent)。
|
|
SDN 目前是 Proxmox VE 中的实验性功能。相关文档还在开发中,请在我们的邮件列表或论坛中提问和反馈。 |
要启用实验性 SDN 集成,您需要在每个节点安装 libpve-network-perl 和 ifupdown2 软件包:
apt update apt install libpve-network-perl ifupdown2
之后,您需要添加以下行:
source /etc/network/interfaces.d/*
在 /etc/network/interfaces 配置文件的末尾,以便包含并激活 SDN 配置。
Proxmox VE SDN 允许使用灵活的软件控制配置对虚拟来宾网络进行分离和细粒度控制。
分隔(Separation)由区域(zone)组成,一个区域是它自己的虚拟分隔的网络区域。VNet 是一种连接到区域的虚拟网络。根据区域使用的类型或插件,它的表现会有所不同,并提供不同的功能、优点或缺点。通常,VNet 显示为一个带有 VLAN 或 VXLAN 标记(也可称为标签)的普通的 Linux 网桥,但是有些也可以使用三层路由进行控制。在从集群范围内的数据中心 SDN 管理界面提交配置之后,会在每个节点上对 VNet 进行本地部署。
配置完成于数据中心(集群范围)级别,它将保存在位于已共享的配置文件系统 /etc/pve/sdn 下的配置文件中:
在 Web 界面上用于配置 SDN 功能的有 3 个主要部分。
SDN:SDN状态概述
区域:创建并管理虚拟分隔的网络区域。
VNet:创建虚拟网络网桥 + 子网管理。
以及部分选项:
控制器:用于控制三层路由的复杂设置
子网:用于在 VNet 上定义 IP 网络。
IPAM:允许使用外部工具进行 IP 地址管理(来宾 IP)
DNS:允许定义用于注册虚拟来宾主机名和 IP 地址的 DNS 服务器 API
这是主要状态面板。在这里您可以看到不同节点上区域的部署状态。
有一个 应用 按钮,用于在所有集群节点上推送和重新加载本地配置。
通过 SDN Web 界面的主要面板应用配置后,在 /etc/network/interfaces.d/sdn 中的每个节点上,本地生成本地网络配置 ,并使用 ifupdown2 重新加载。
您可以通过主树监测本地区域和 vnet 的状态。
一个区域(zone)将定义一个虚拟分隔的网络。
它可以使用不同的技术进行分隔:
VLAN:虚拟局域网是划分局域网的经典方法。
QinQ:堆叠式 VLAN(正式名称为 IEEE 802.1ad)
VXLAN:二层 vxlan
Simple:隔离网桥,简单的三层路由网桥(NAT)
bgp-evpn:vxlan 使用三层边界网络协议进行路由
您可以在指定节点限制一个区域。
还可以在一个区域上添加权限,用于限制用户仅能使用指定区域和该区域中的 VNet 。
以下选项可用于所有区域类型。
仅在这些节点上部署并允许使用为此区域配置的 VNet。
可选,如果您想要使用 ipam 工具管理此区域的 IPS 。
可选,DNS API 服务器。
可选,反向 DNS API 服务器
可选,DNS 域名。用于注册主机名,类似 <hostname>.<domain> 。DNS 区域需要已存在于 DNS 服务器中。
这是最简单的插件,它将创建一个隔离的 vnet 网桥。此网桥未链接到物理接口,VM 流量仅在本地节点。它还可以用于 NAT 或路由设备。
该插件将重用现有的本地 Linux 或 OVS bridge(网桥),并在其上管理 VLAN。使用 SDN 模块的好处是,您可以使用指定的 VNet VLAN 标签创建不同的区域,并将虚拟机限制在分隔的区域。
特定的 VLAN 配置选项:
重用已在每个本地节点上配置的本地网桥或 OVS 交换机。
QinQ 是堆叠的 VLAN。为区域定义的第一个 VLAN 标签(也称为 service-vlan(业务 vlan)),以及为 vnet 定义的第二个 VLAN 标签。
|
|
您的物理网络交换机必须支持堆叠 VLAN! |
特定的 QinQ 配置选项:
已在每个本地节点上配置了一个本地 VLAN 感知(aware) 网桥
该区域的主 VLAN 标签
允许定义 802.1q(默认)或 802.1ad service-vlan 类型。
由于标签的双重堆叠,QinQ VLAN 需要多 4 个字节。例如,如果物理接口的 MTU 是 1500 ,则将 MTU 减少到 1496。
VXLAN 插件将在现有网络(名为 underlay)之上建立一个隧道(名为 overlay)。它将二层以太网帧封装在第 4 层 UDP 数据报中,使用 4789 作为默认目标端口。例如,您可以在公共 Internet 网络节点之上创建一个私有的 IPv4 VXLAN 网络。这只是一个二层隧道,在不同 VNet 之间不可能进行路由。
每个 VNet 都将使用范围(1-16777215)内的特定 VXLAN ID 。
特定的 EVPN 配置选项:
来自您想要通过其进行通信的所有节点的 IP 列表。也可以是外部节点。
由于 VXLAN 封装使用 50 字节,因此 MTU 需要比传出的物理接口低 50 字节。
这是所有支持的插件中最复杂的。
BGP-EVPN 允许创建一个可路由的三层网络。EVPN 的 VNet 可以具有任播 IP 地址和(或) MAC 地址。在每个节点上的网桥 IP 都是相同的,因此虚拟来宾可以使用该地址作为网关。
路由可以通过 VRF(虚拟路由转发)接口,跨越不同的区域的 VNet 进行工作。
特定的 EVPN 配置选项:
这是一个 vxlan 的 ID,用于 vnet 之间的路由互连,它必须与 VNet 的 VXLAN 的 ID 不同。
需要首先定义 EVPN 控制器(请参阅 控制器 插件部分)
该区域中所有 VNet 的唯一任播 MAC 地址。如果未定义,将自动生成。
如果您想定义一些 proxmox 节点,则使用它,作为从 evpn 网络到真实网络的出口网关。配置的节点将广播 EVPN 网络中的默认路由。
可选。如果您有静默的 vms/CT(例如,多个接口的 ips ,并且任意播网关无法识别来自这些 ips 的数据流量,则 ips 地址将无法在 evpn 网络内部访问)。在这种情况下,此选项将在 evpn 网络内广播完整子网。
可选。从出口节点访问 VM /容器服务的特殊选项。(默认情况下,出口节点仅允许在真实网络和 evpn 网络之间转发流量)。
由于 VXLAN 封装使用 50 字节,因此 MTU 需要比传出的物理接口的最大 MTU 低 50 字节。
VNet 的基本形式只是一个 Linux 网桥,它被部署在本地节点并用于 VM 通信。
VNet 属性包括:
8 个字符的 ID ,用于命名和标识 VNet
可选的更长的名称,如果 ID 不够直观
此 VNet 的关联区域
唯一的 VLAN 或 VXLAN id
允许在 VM 或容器的 vNIC 配置中添加额外的 VLAN 标签(tag),或允许来宾操作系统管理 VLAN 的标签(tag)。
一个子网(subnet or sub-net)允许您定义一个特定的 IP 网络(IPv4 或 IPv6)。对于每个 VNET,您可以定义一个或多个子网。
一个子网可以用于:
限制您可以在特定 VNET 上定义的 IP 地址
在三层区域的 VNET 上分配路由/网关
在三层区域的 VNET 上启用 SNAT(源 NAT)
通过 IPAM 插件在虚拟来宾(虚拟机或容器)中自动分配 IP
通过 DNS 插件进行 DNS 注册
如果 IPAM 服务器与子网区域相关联,则子网前缀将自动注册到 IPAM。
子网属性是:
一个 CIDR 格式的网络地址。例如:10.0.0.0/8
此网络默认网关的 IP 地址。在三层区域(simple/evpn 插件),它将部署在的 VNET 上。
可选,为该子网的三层区域(simple/evpn 插件)启用 SNAT(源 NAT)。该子网源 IP 将会转换为服务器的传出接口或 IP 地址。在 evpn 区域,它仅在 evpn 网关节点上使用。
可选,为域名注册添加前缀,类似 <hostname>.prefix.<domain>
某些类型的区域需要一个外部控制器来管理 VNet 控制层。目前,只有 bgp-evpn 区域插件需要这样做。
对于 BGP-EVPN ,我们需要一个控制器来管理控制层。当前支持的软件控制器是“frr”路由器。您可能需要在要部署 EVPN 区域的每个节点上安装它。
apt install frr frr-pythontools
配置选项:
唯一的 BGP ASN 编号。强烈建议使用私有 ASN 编号(64512 – 65534、4200000000 – 4294967294),否则您可能会因错误的全局路由而中断或被中断。
要用于 EVPN 通信的所有节点的 IP 列表(也可以是外部节点或路由反射器服务器 )
一个区域不直接使用 bgp 控制器。您可以使用它来配置 frr 来管理 bgp 的 peers 。
对于 BGP-evpn,它可以按节点来定义不同的 ASN,EBGP 也是如此。
配置选项:
此 BGP 控制器的节点
唯一的 BGP ASN 编号。强烈建议使用私有 ASN 编号(64512 – 65534、4200000000 – 4294967294),否则您可能会因错误的全局路由而中断或被中断。
用于底层 BGP 网络通信的 peers 的 IP 列表。
如果您的 peer 的远程 AS 不同,则启用 EBGP 。
如果您想使用环回或虚拟接口作为 evpn 网络的源。(对于多路径)
如果 peers 没有直接连接或使用环回,则可以增加到达它们的跳数。
IPAM(IP 地址管理,即 IP address management 的简称)工具,用于管理/分配您的设备所在网络的 IP 。例如,当您创建虚拟机或容器时,可以使用它来查找空闲的 IP 地址(尚未实现)。
一个 IPAM 关联一个或多个区域,在该区域中为定义的所有子网提供 IP 地址。
如果您没有外部 IPAM 软件,这是用于 Proxmox 集群的默认内部 IPAM 。
您需要在 phpIPAM 中创建一个应用程序,并添加一个具有管理员权限的 API 令牌。
phpIPAM 属性包括:
REST-API 端点:http://phpipam.domain.com/api/<appname>/
API 访问令牌
一个整数 ID 。部分是 phpIPAM 中的子网组。对于客户,默认安装使用 sectionid=1 。
NetBox 是一个 IP 地址管理(IPAM)和数据中心基础设施管理(Data Center Infrastructure Management,简称 DCIM)工具,详细信息见源代码库:https://github.com/netbox-community/netbox
您需要在 netbox 中创建一个 API 令牌 https://netbox.readthedocs.io/en/stable/api/authentication
NetBox 属性包括:
REST API 端点:http://yournetbox.domain.com/api
API 访问令牌
Proxmox VE 的 SDN 中的 DNS 插件用于定义一个 DNS API 服务器,用于注册您的主机名和 IP 地址。DNS 配置与一个或多个区域相关联,为该区域配置的所有子网 IP 提供 DNS 注册。
您需要在 PowerDNS 配置中启用 Web 服务器和 API:
api=yes api-key=arandomgeneratedstring webserver=yes webserver-port=8081
Powerdns 属性包括:
REST API 端点:http://yourpowerdnserver.domain.com:8081/api/v1/servers/localhost
API 访问密钥
记录的默认 TTL
|
|
虽然我们在这里展示了简单的配置内容,但几乎所有内容都应该仅使用 Web 界面进行配置。 |
节点 1:/etc/network/interfaces
auto vmbr0
iface vmbr0 inet manual
bridge-ports eno1
bridge-stp off
bridge-fd 0
bridge-vlan-aware yes
bridge-vids 2-4094
#management ip on vlan100
auto vmbr0.100
iface vmbr0.100 inet static
address 192.168.0.1/24
source /etc/network/interfaces.d/*节点 2:/etc/network/interfaces
auto vmbr0
iface vmbr0 inet manual
bridge-ports eno1
bridge-stp off
bridge-fd 0
bridge-vlan-aware yes
bridge-vids 2-4094
#management ip on vlan100
auto vmbr0.100
iface vmbr0.100 inet static
address 192.168.0.2/24
source /etc/network/interfaces.d/*创建一个名为“myvlanzone”的 VLAN 区域:
id: myvlanzone bridge: vmbr0
创建一个名为“myvnet1”、“vlan-id”为“10”的 VNet,以之前创建的“myvlanzone”作为它的区域。
id: myvnet1 zone: myvlanzone tag: 10
通过主 SDN 面板应用该配置,在每个节点上本地创建 VNet 。
在节点 1 上创建一个基于 Debian 的虚拟机(vm1),在 VNet“myvnet1”上有一个 vNIC 。
为该 VM 使用以下网络配置:
auto eth0
iface eth0 inet static
address 10.0.3.100/24在节点 2 上创建第二个与虚拟机(vm1)相同的虚拟机(vm2),也在 VNet“myvnet1”上有一个 vNIC 。
为该 VM 使用以下网络配置:
auto eth0
iface eth0 inet static
address 10.0.3.101/24然后,您应该能够通过该网络在两个 VM 之间进行 ping 操作。
|
|
虽然我们在这里展示了简单的配置内容,但几乎所有内容都应该仅使用 Web 界面进行配置。 |
节点 1:/etc/network/interfaces
auto vmbr0
iface vmbr0 inet manual
bridge-ports eno1
bridge-stp off
bridge-fd 0
bridge-vlan-aware yes
bridge-vids 2-4094
#management ip on vlan100
auto vmbr0.100
iface vmbr0.100 inet static
address 192.168.0.1/24
source /etc/network/interfaces.d/*节点 2:/etc/network/interfaces
auto vmbr0
iface vmbr0 inet manual
bridge-ports eno1
bridge-stp off
bridge-fd 0
bridge-vlan-aware yes
bridge-vids 2-4094
#management ip on vlan100
auto vmbr0.100
iface vmbr0.100 inet static
address 192.168.0.2/24
source /etc/network/interfaces.d/*创建一个名为“qinqzone1”、业务 VLAN 20 的 QinQ 区域
id: qinqzone1 bridge: vmbr0 service vlan: 20
创建另一个名为“qinqzone2”、业务 VLAN 30 的 QinQ 区域
id: qinqzone2 bridge: vmbr0 service vlan: 30
在之前创建的“qinqzone1”区域上创建一个名为“myvnet1”、用户 VLAN-id 为 100 的 VNet 。
id: myvnet1 zone: qinqzone1 tag: 100
在之前创建的“qinqzone2”区域上创建一个名为“myvnet2”、用户 VLAN-id 为 100 的 VNet 。
id: myvnet2 zone: qinqzone2 tag: 100
在 Web 界面的主 SDN 面板上应用配置以在每个节点上本地创建 VNet 。
在节点 1 上创建一个基于 Debian 的虚拟机(vm1),在 VNet“myvnet1”上有一个 vNIC 。
为该 VM 使用以下网络配置:
auto eth0
iface eth0 inet static
address 10.0.3.100/24在节点 2 上创建第二个与虚拟机(vm1)相同的虚拟机(vm2),也在 VNet“myvnet1”上有一个 vNIC 。
为该 VM 使用以下网络配置:
auto eth0
iface eth0 inet static
address 10.0.3.101/24在节点 1 上创建第三个虚拟机(vm3),在另一个 VNet“myvnet2”上有一个 vNIC 。
为该 VM 使用以下网络配置:
auto eth0
iface eth0 inet static
address 10.0.3.102/24在节点 2 上创建另一个与虚拟机(vm3)相同的虚拟机(vm4),也在相同的 VNet“myvnet2”上有一个 vNIC 。
为该 VM 使用以下网络配置:
auto eth0
iface eth0 inet static
address 10.0.3.103/24然后,您应该能够在虚拟机 vm1 和 vm2 以及虚拟机 vm3 和 vm4 之间进行 ping 操作。但是,虚拟机 vm1 或 vm2 都不能 ping 通虚拟机 vm3 或 vm4 ,因为他们位于具有不同业务 VLAN 的不同区域。
|
|
虽然我们在这里展示了简单的配置内容,但几乎所有内容都应该仅使用 Web 界面进行配置。 |
节点 1:/etc/network/interfaces
auto vmbr0
iface vmbr0 inet static
address 192.168.0.1/24
gateway 192.168.0.254
bridge-ports eno1
bridge-stp off
bridge-fd 0
mtu 1500
source /etc/network/interfaces.d/*节点 2:/etc/network/interfaces
auto vmbr0
iface vmbr0 inet static
address 192.168.0.2/24
gateway 192.168.0.254
bridge-ports eno1
bridge-stp off
bridge-fd 0
mtu 1500
source /etc/network/interfaces.d/*节点 3:/etc/network/interfaces
auto vmbr0
iface vmbr0 inet static
address 192.168.0.3/24
gateway 192.168.0.254
bridge-ports eno1
bridge-stp off
bridge-fd 0
mtu 1500
source /etc/network/interfaces.d/*创建一个名为“myvxlanzone”的 VXLAN 区域,使用较低的 MTU 以确保 VXLAN 头部可以容纳额外的 50 字节。将之前所有节点中配置的 IP 地址添加为 peer 地址列表。
id: myvxlanzone peers address list: 192.168.0.1,192.168.0.2,192.168.0.3 mtu: 1450
使用之前创建的 VXLAN 区域“myvxlanzone”,创建一个名为“myvnet1”的 VNet 。
id: myvnet1 zone: myvxlanzone tag: 100000
在 Web 界面的主 SDN 面板上应用配置以在每个节点上本地创建 VNet 。
在节点 1 上创建一个基于 Debian 的虚拟机(vm1),在 VNet“myvnet1”上有一个 vNIC 。
为该 VM 使用以下网络配置,请注意这里的 MTU 较低。
auto eth0
iface eth0 inet static
address 10.0.3.100/24
mtu 1450在节点 3 上创建第二个与虚拟机(vm1)相同的虚拟机(vm2),也在 VNet“myvnet1”上有一个 vNIC 。
为该 VM 使用以下网络配置:
auto eth0
iface eth0 inet static
address 10.0.3.101/24
mtu 1450然后,您应该能够在虚拟机 vm1 和 vm2 之间进行 ping 操作。
节点 1:/etc/network/interfaces
auto vmbr0
iface vmbr0 inet static
address 192.168.0.1/24
gateway 192.168.0.254
bridge-ports eno1
bridge-stp off
bridge-fd 0
mtu 1500
source /etc/network/interfaces.d/*
节点 2:/etc/network/interfaces
auto vmbr0
iface vmbr0 inet static
address 192.168.0.2/24
gateway 192.168.0.254
bridge-ports eno1
bridge-stp off
bridge-fd 0
mtu 1500
source /etc/network/interfaces.d/*
节点 3:/etc/network/interfaces
auto vmbr0
iface vmbr0 inet static
address 192.168.0.3/24
gateway 192.168.0.254
bridge-ports eno1
bridge-stp off
bridge-fd 0
mtu 1500
source /etc/network/interfaces.d/*创建一个名为“myevpnctl”的 EVPN 控制器,使用私有 ASN 编号和以上节点地址作为 peers 。
id: myevpnctl asn: 65000 peers: 192.168.0.1,192.168.0.2,192.168.0.3
使用之前创建的 EVPN 控制器,创建一个名为“myevpnzone”的 EVPN 区域,将 node1(节点 1) 和 node2(节点 2)定义为出口节点。
id: myevpnzone vrf vxlan tag: 10000 controller: myevpnctl mtu: 1450 vnet mac address: 32:F4:05:FE:6C:0A exitnodes: node1,node2
使用 EVPN 区域“myevpnzone”,创建名为“myvnet1”的第一个 VNet 。
id: myvnet1 zone: myevpnzone tag: 11000
在 vnet1 上创建一个子网 10.0.1.0/24,以 10.0.1.1 作为网关
subnet: 10.0.1.0/24 gateway: 10.0.1.1
使用相同的 EVPN 区域“myevpnzone”,创建第二个名为“myvnet2”的 VNet (不同的 IPv4 CIDR 网络)。
id: myvnet2 zone: myevpnzone tag: 12000
在 vnet2 上创建一个不同的子网 10.0.2.0/24,以 10.0.2.1 作为网关
subnet: 10.0.2.0/24 gateway: 10.0.2.1
在 Web 界面的主 SDN 面板上应用配置以在每个节点上本地创建 VNet 并生成 FRR 配置。
在节点 1 上创建一个基于 Debian 的虚拟机(vm1),在 VNet“myvnet1”上有一个 vNIC 。
为该 VM 使用以下网络配置:
auto eth0
iface eth0 inet static
address 10.0.1.100/24
gateway 10.0.1.1 #this is the ip of the vnet1
mtu 1450在节点 2 上创建第二个虚拟机(vm2),在另一个 VNet“myvnet2”上有一个 vNIC 。
为该 VM 使用以下网络配置:
auto eth0
iface eth0 inet static
address 10.0.2.100/24
gateway 10.0.2.1 #this is the ip of the vnet2
mtu 1450然后,您应该能够从 vm1 ping 通 vm2,并且从 vm2 ping 通 vm1 。
如果您从非网关的 node3(节点 3)上的 vm2 ping 一个外部 IP ,数据包将发往 myvnet2 配置的网关,然后将被路由到出口节点(node1(节点 1) 或 node2(节点 2)),并让数据包通过配置在 node1(节点 1) 或 node2(节点 2)上的默认网关离开这些节点。
|
|
当然,您需要将 10.0.1.0/24 和 10.0.2.0/24 网络的反向路由添加到作为外部网关的节点 1、节点 2 上,这样公共网络才能回应。 |
如果您配置了外部 BGP 路由器,则 BGP-EVPN 的路由(本例中为 10.0.1.0/24 和 10.0.2.0/24)将会动态广播。
如果您需要在 VXLAN 上添加加密,可以通过 strongswan 使用 IPSEC 来实现。您需要将 MTU 减少 60 字节(IPv4)或 80 字节(IPv6)来处理加密。
因此,默认实际为 1500 MTU,您需要使用 1370 MTU(1370 + 80 (IPSEC) + 50 (VXLAN) == 1500)。
apt install strongswan
在“/etc/ipsec.conf”中添加配置。我们只需要加密来自 VXLAN 的 UDP 端口 4789 的数据流量。
conn %default
ike=aes256-sha1-modp1024! # the fastest, but reasonably secure cipher on modern HW
esp=aes256-sha1!
leftfirewall=yes # this is necessary when using Proxmox VE firewall rules
conn output
rightsubnet=%dynamic[udp/4789]
right=%any
type=transport
authby=psk
auto=route
conn input
leftsubnet=%dynamic[udp/4789]
type=transport
authby=psk
auto=route然后通过以下命令生成一个预共享密钥:
openssl rand -base64 128
并复制“/etc/ipsec.secrets”中的密钥,此文件内容看起来像:
: PSK <generatedbase64key>
您需要在其他节点上复制 PSK 和配置。
Proxmox VE 防火墙提供了保护您的 IT 基础设施的简单方法。您可以为集群内的所有主机设置防火墙规则,或者为虚拟机和容器定义规则。防火墙宏、安全群组、IP 集和别名等功能有助于简化该任务。
虽然所有配置都存储在集群文件系统上,但是基于 iptables 的防火墙服务运行在每个集群节点上,从而在虚拟机之间提供完全隔离。该系统的分布式特性还提供比集中式防火墙解决方案更高的带宽。
防火墙完全支持 IPv4 和 IPv6 。IPv6 支持是完全透明的,我们默认过滤两种协议的流量。因此无需为 IPv6 维护一组不同的规则。
Proxmox VE 防火墙将网络分为以下逻辑区域:
进/出集群节点的流量
进/出特定 VM 的流量
对于每个区域,您可以为传入与(或)传出的流量定义防火墙规则。
所有与防火墙相关的配置都存储在 proxmox 集群文件系统上。因此,这些文件会自动分发到所有集群节点,并且 pve-firewall 服务会根据更改自动更新底层的 iptables 规则。
您可以使用 GUI 界面(例如 数据中心 → 防火墙,或在一个 节点 → 防火墙 中)配置任何内容,或者您可以使用首选编辑器直接编辑配置文件。
防火墙配置文件包含键-值(key-value)对的“节”。以 # 开头的行和空行被视为注释。“节”由包含了使用 [ 和 ] 括起来的“节”的名称的标题行开始。
集群范围的防火墙配置存储在:
/etc/pve/firewall/cluster.fw
此配置可以包含以下部分:
这是用于设置集群范围的防火墙选项。
在集群范围内启用 ebtables 规则。
启用或禁用集群范围的防火墙。
日志速率限制设置
在应用速率之前将始终记录初始数据包的突发数
启用或禁用日志速率限制
突发数被重新填充的频率
输入策略。
输出策略。
本节包含集群范围内所有节点的防火墙规则。
集群范围的 IPset 定义。
集群范围的安全群组定义。
集群范围的别名定义。
默认情况下防火墙是完全禁用的,因此您需要在此处设置启用选项:
[OPTIONS] # enable firewall (cluster-wide setting, default is disabled) enable: 1
|
|
如果您启用防火墙,默认情况下会阻断所有主机的流量。只有来自本地网络的 WebGUI(8006) 和 ssh(22) 例外。 |
如果您想要从远程管理您的 Proxmox VE 主机,则需要创建规则以允许从这些远程 IP 到 Web GUI(端口 8006)的流量。您可以还希望允许 SSH(端口 22),也可能是 SPICE(端口 3128)。
|
|
在启用防火墙之前,请打开与您的 Proxmox VE 主机之一的 SSH 连接。这样如果出现问题,您仍然可以访问主机。 |
为了简化该任务,您可以改为创建一个名为“management”的 IPSet ,并在其中添加所有远程 IP 。这将创建从远程访问 GUI 所需的所有防火墙规则。
主机相关的配置读取自:
/etc/pve/nodes/<nodename>/host.fw
如果您想覆盖 cluster.fw 配置中的规则,这很有用。您还可以增加日志详细程序,并设置 netfilter 相关选项。该配置可以包含以下部分:
这是用于设置与主机相关的防火墙选项。
启用主机的防火墙规则。
传入流量的日志级别。
传出流量的日志级别。
启用 conntrack 信息的日志记录。
启用 NDP(邻居发现协议,Neighbor Discovery Protocol 的简称)。
允许连接跟踪中的无效数据包。
最大跟踪连接数。
Conntrack 建立超时。
Conntrack 同步接收超时。
启用 SMURFS 过滤器。
启用 SYN洪水保护
由 IP 源提供的 SYN 洪水保护突发速率。
由 IP 源提供的 SYN 洪水保护速率(syn/sec)。
SMURFS 过滤器的日志级别。
非法 tcp 标志过滤器的日志级别。
过滤 TCP 标志的非法组合。
此部分包含主机特定的防火墙规则。
VM 的防火墙配置读取自:
/etc/pve/firewall/<VMID>.fw
并包含以下数据:
这是用于设置 VM / 容器相关的防火墙选项。
启用 DHCP 。
启用/禁用防火墙规则。
启用默认 IP 过滤器。这相当于为每个接口添加一个空的 ipfilter-net<id> ipset 。此类 ipset 隐式包含合理的默认限制,例如将 IPv6 链接本地地址限制为从接口的 MAC 地址派生的地址。对于容器,将隐式添加配置的 IP 地址。
传入流量的日志级别。
传出流量的日志级别。
启用/禁用 MAC 地址过滤器。
启用 NDP(邻居发现协议,Neighbor Discovery Protocol 的简称)。
输入策略。
输出策略。
允许发送路由广播。
此部分包含 VM /容器防火墙规则。
IPSet 定义。
IP 别名定义。
每个虚拟网络设备都有自己的防火墙启用标志。因此,您可以有选择地为每个接口启用防火墙。除了常规防火墙 启用 选项之外,这也是必需的。
防火墙规则由方向(IN(入方向) 或 OUT(出方向))和动作(ACCEPT、DENY、REJECT)组成。您还可以指定一个宏名称。宏包含预定义的规则和选项集。可以通过在规则前加上 | 来禁用规则。
[RULES] DIRECTION ACTION [OPTIONS] |DIRECTION ACTION [OPTIONS] # disabled rule DIRECTION MACRO(ACTION) [OPTIONS] # use predefined macro
以下选项可用于改善规则匹配。
限制数据包目标地址。这可以指单个 IP 地址、IP 集(+ipsetname)或 IP 别名定义。您还可以指定类似 20.34.101.207-201.3.9.99 的地址范围,或者 IP 地址与网络的列表(条目以逗号分隔)。请不要在此类列表中混合使用 IPv4 和 IPv6 地址。
限制 TCP/UDP 目标端口。您可以使用 /etc/services 中定义的服务名称或简单数字(0-65535)。可以通过 \d+:\d+ 指定端口范围,例如 80:85 ,并且您可以使用逗号分隔的列表来匹配多个端口或范围。
指定 ICMP 类型。仅当 proto(协议)等于 icmp 时有效。
网络接口名称。您必须为 VM 和容器使用网络配置关键的名称(net\d+)。与主机相关的规则可以使用任意字符串。
防火墙规则的日志级别。
IP 协议。您可以使用 /etc/protocols 中定义的协议名称(tcp/udp)或者简单数字。
限制数据包源地址。这可以指单个 IP 地址,IP 集(+ipsetname)或 IP 别名定义。您还可以指定类似 20.34.101.207-201.3.9.99 的地址范围,或者 IP 地址和网络的列表(条目以逗号分隔)。请不要在此类列表中混合使用 IPv4 和 IPv6 地址。
限制 TCP/UDP 源端口。您可以使用 /etc/services 中定义的服务名称或简单数字(0-65535)。可以通过 \d+:\d+ 指定端口范围,例如 80:85 ,并且您可以使用逗号分隔的列表来匹配多个端口或范围。
这里是部分范例:
[RULES] IN SSH(ACCEPT) -i net0 IN SSH(ACCEPT) -i net0 # a comment IN SSH(ACCEPT) -i net0 -source 192.168.2.192 # only allow SSH from 192.168.2.192 IN SSH(ACCEPT) -i net0 -source 10.0.0.1-10.0.0.10 # accept SSH for IP range IN SSH(ACCEPT) -i net0 -source 10.0.0.1,10.0.0.2,10.0.0.3 #accept ssh for IP list IN SSH(ACCEPT) -i net0 -source +mynetgroup # accept ssh for ipset mynetgroup IN SSH(ACCEPT) -i net0 -source myserveralias #accept ssh for alias myserveralias |IN SSH(ACCEPT) -i net0 # disabled rule IN DROP # drop all incoming packages OUT ACCEPT # accept all outgoing packages
安全群组是定义在集群级别的规则集合,可以在所有 VM 的规则中使用它。例如您可以定义一个名字为“webserver”,包含打开 http 和 https 端口规则的群组。
# /etc/pve/firewall/cluster.fw [group webserver] IN ACCEPT -p tcp -dport 80 IN ACCEPT -p tcp -dport 443
然后,您可以添加该组到 VM 的防火墙
# /etc/pve/firewall/<VMID>.fw [RULES] GROUP webserver
IP 别名允许您将网络的 IP 地址与一个名字相关联。然后,您可以参考这些名称:
内部 IP 集定义
在防火墙规则的 source(源) 和 dest(目标) 属性。
此别名是自动定义的。请使用以下命令查看分配的值:
# pve-firewall localnet local hostname: example local IP address: 192.168.2.100 network auto detect: 192.168.0.0/20 using detected local_network: 192.168.0.0/20
防火墙会自动设置规则,以允许使用此别名进行集群通信(corosync、API、SSH)所需的一切。
用户可以覆盖 cluster.fw 中 [ALIASES] 小节的这些值。如果您在公共网络上使用单个主机,最好显式分配本地 IP 地址。
# /etc/pve/firewall/cluster.fw [ALIASES] local_network 1.2.3.4 #备注:使用单个 IP 地址
IP 集可用于定义网络和主机群组。您可以在防火墙规则的 source(源) 和 dest(目标) 属性中使用“+name”来引用它们。
以下范例允许来自 management IP 集的 HTTP 流量。
IN HTTP(ACCEPT) -source +management
该 IP 集仅适用于主机防火墙(而非虚拟机防火墙)。这些 IP 可以执行常规的管理任务(PVE GUI、VNC、SPICE、SSH)。
本地集群网络会自动添加到此 IP 集(别名是 cluster_network),以启用主机间集群通信(多播、SSH等)。
# /etc/pve/firewall/cluster.fw [IPSET management] 192.168.2.10 192.168.2.10/24
每个主机与虚拟机的防火墙都会丢弃来自这些 IP 的流量。(即 黑名单功能)
# /etc/pve/firewall/cluster.fw [IPSET blacklist] 77.240.159.182 213.87.123.0/24
这些过滤器属于 VM 的网络接口,主要用于防止 IP 欺骗。如果接口存在这样的集合,则源 IP 与其接口对应的 ipfilter 集合不匹配的任何传出流量都将被丢弃。
对于配置了 IP 地址的容器,这些集合(如果存在,或者是通过虚拟机防火墙的 选项 选项页中的 IP 筛选 选项激活的)将隐式包含关联的 IP 地址。
对于虚拟机和容器,它们还隐含包含标准 MAC 派生的 IPv6 链路本地地址,以允许邻居发现协议(NDP)正常工作。
# /etc/pve/firewall/<VMID>.fw [IPSET ipfilter-net0] # 仅允许 net0 上的指定 IP 192.168.2.10
防火墙在每个节点上运行两个服务守护进程:
pvefw-logger:NFLOG 守护进程(ulogd 替代)。
pve-firewall:更新 iptables 规则
还有一个名为 pve-firewall 的 CLI 命令,它可以用于启动(start)和停止(stop)防火墙服务:
# pve-firewall start # pve-firewall stop
要获取状态(status)使用:
# pve-firewall status
上述命令读取并编译所有防火墙规则,因此假如您的防火墙配置包含任何错误时,您将看到警告。
如果您想要查看生成的 iptables 规则,可以使用以下命令:
# iptables-save
默认防火墙配置会过滤以下流量:
假设把防火墙的输入或输出策略设置为 DROP(丢弃)或 REJECT(拒绝),集群中的所有 Proxmox VE 主机仍然允许以下流量:
环回(loopback)接口上的流量
已建立的连接
使用 IGMP 协议的流量
从管理主机到端口 8006 的 TCP 流量以允许访问 Web 界面
从管理主机到端口范围(5900 到 5999)的 TCP 流量以允许 VNC Web 控制台的流量
从管理主机到端口 3128 的 TCP 流量,用于连接到 SPICE 代理
从管理主机到端口 22 的 TCP 流量以允许 SSH 访问
在集群网络中,到用于 corosync 端口(5404 和 5405)的 UDP 流量
集群网络中的 UDP 多播流量
ICMP 流量类型:3(目标不可达)、4(拥塞控制)或 11(超时)
将会丢弃以下流量,即使启用日志记录也不会记录:
具有无效连接状态的 TCP 连接
与 corosync 无关的广播、多播和任播流量,即不通过端口 5404 或 5405
到端口 43 的 TCP 流量
到端口 135 和 445 的 UDP 流量
到端口范围(137 到 139)的 UDP 流量
从源端口 137 到端口范围(1024 到 65535)的 UDP 流量
到端口 1900 的 UDP 流量
到端口 135 、139 和 445 的 TCP 流量
来自源端口 53 的 UDP 流量源
其余的流量分别被丢弃或拒绝,并被记录下来。这可能的变化取决于 防火墙 → 选项 中启用的其他选项,例如 NDP、SMURFS 和 TCP 标志筛选。
通过执行以下系统命令:
# iptables-save
然后,检查以上系统命令的输出,查看系统上活动的防火墙链(chains)和规则。该输出也包含在 系统报告 中,在 Web GUI 中节点的订阅选项卡上或通过 pvereport 命令行工具可见。
这会丢弃或拒绝所有到 VM 的流量,但与 DHCP、NDP、路由器广播、MAC 和 IP 筛选相关的一些例外情况取决于配置的设定。用于丢弃或拒绝数据包的相同规则继承自数据中心,但是不适用于主机接受的传入/传出流量的例外情况。
同样,您可以使用 iptables-save(见上文) 来检查所有已应用的规则和链(chains)。
默认情况下,禁止记录所有被防火墙规则过滤的流量日志。要启用日志记录,必须在 防火墙 → 选项 中设置传入和(或)传出流量的 loglevel(日志级别)。这可以用主机以及 VM / CT 的防火墙单独完成。由此,已启用 Proxmox VE 的标准防火墙规则的日志记录,并且可以在 防火墙 → 日志 中观察输出。此外,标准规则仅记录部分被丢弃或拒绝的数据包(请参阅 默认防火墙规则)。
loglevel(日志级别) 不影响记录了多少已过滤的流量。它将 LOGID 作为前缀附加到日志输出,以便于筛选与后处理。
loglevel(日志级别) 是以下标志之一:
| loglevel(日志级别) | LOGID |
|---|---|
nolog |
— |
emerg |
0 |
alert |
1 |
crit |
2 |
err |
3 |
warning |
4 |
notice |
5 |
info |
6 |
debug |
7 |
典型的防火墙日志输出如下所示:
VMID LOGID CHAIN TIMESTAMP POLICY: PACKET_DETAILS
这个情况下的主机防火墙,VMID 等于 0 。
为了记录由用户定义的防火墙规则过滤的数据包,可以为每个规则单独设置一个日志级别参数。这允许以细粒度方式进行日志记录,并且独立于 防火墙 → 选项 中的标准规则定义的日志级别。
虽然可以在创建或修改规则期间在 WebUI 中轻松定义或更改每个独立规则的 日志级别 ,但也可以通过相应的 pvesh API调用进行设置。
此外,还可以通过防火墙配置文件设置日志级别,方法是将 -log <loglevel> 附加到所选的规则(请参阅 合适的日志级别)。
例如,下面配置有两个日志级别的标识:
IN REJECT -p icmp -log nolog IN REJECT -p icmp
鉴于此,以下的配置:
IN REJECT -p icmp -log debug
是生成一个带有 debug 级别标记的日志输出。
FTP 是一种旧式协议,它使用端口 21 和其他几个动态端口,因此您需要一个接受端口 21 的规则。另外,您需要加载 ip_conntrack_ftp 模块。所以请运行:
modprobe ip_conntrack_ftp
并添加 ip_conntrack_ftp 到 /etc/modules(以便它在重新启动后工作)。
如果您想使用 Suricata IPS(入侵防御系统,Intrusion Prevention System 的简称),这是可能的。
只有在防火墙接受(动作:ACCEPT)数据包后,数据包才会转发到IPS。
而被防火墙拒绝或丢弃的数据包不会转发到 IPS 。
在 proxmox 主机上安装 suricata:
# apt-get install suricata # modprobe nfnetlink_queue
不要忘记将 nfnetlink_queue 添加到 /etc/modules 以便下次重启。
然后,通过以下方式为特定 VM 启用 IPS :
# /etc/pve/firewall/<VMID>.fw [OPTIONS] ips: 1 ips_queues: 0
ips_queues 将为该 VM 绑定一个特定的 CPU 队列。
可用队列定义在
# /etc/default/suricata NFQUEUE=0
防火墙包含一些 IPv6 特定选项。需要注意的一点是,IPv6 不再使用 ARP 协议,而是使用 NDP(邻居发现协议,Neighbor Discovery Protocol 的简称),它工作在 IP 层,因此需要 IP 地址才能成功。为此,使用从接口的 MAC 地址派生的链路本地地址。默认情况下,同时启用主机和 VM 级别的 NDP 选项,以允许发送和接收邻居发现(NDP)数据包。
除了邻居发现,NDP 还用于其他一些事情,比如自动配置和广播路由器。
默认情况下,允许 VM 发送路由器请求消息(查询路由器),并接收路由器广播数据包。这允许他们使用无状态自动配置。在另一方面,除非设置了”允许路由器广播“(radv: 1)选项,否则 VM 无法将自身广播为路由器。
至于 NDP 所需的链路本地地址,还有一个”IP 筛选“(ipfilter: 1)选项可以启用,它与为每个 VM 的网络接口添加一个包含相应的链路本地地址的 IP 集(ipfilter-net*)的效果相同。(有关详细信息,请参阅 标准 IP 集 ipfilter-net* 部分。)
Web 界面:8006(TCP、HTTP/1.1 over TLS)
VNC Web 控制台:5900-5999(TCP、WebSocket)
SPICE 代理:3128(TCP)
sshd(用于集群操作):22(TCP)
rpcbind:111(UDP,例如用于 NFS 存储的文件共享)
sendmail:25 (TCP,传出,例如发送邮件)
corosync 集群流量:5404、5405 UDP
实时迁移( VM 内存和本地磁盘数据):60000-60050(TCP)
Proxmox VE 支持多种身份验证源,例如 Linux PAM、Proxmox VE 集成的身份验证服务器、LDAP(轻型目录访问协议)、Microsoft 活动目录(Active Directory,简称 AD)和 OpenID Connect 。
通过对所有对象( VM 、存储、节点等)使用基于角色的用户和权限管理 ,可以定义颗粒化的访问。
Proxmox VE 将用户属性存储在 /etc/pve/user.cfg。密码不存储在这里; 用户与下面描述的 认证领域 相关联。因此,用户通常以 <userid>@<realm>. 的形式通过其用户名和领域在内部进行标识。
此文件中的每个用户条目都包含以下信息:
名字
姓
邮箱地址
群组成员身份
可选的到期日期
关于此用户的评论或说明
是否启用或禁用此用户
可选的二次验证(双因子认证)密钥
|
|
当您禁用或删除用户时,或者如果设置的到期日期已过,则该用户将无法登录新的会话或开始新的任务。任何此类事件都 不会 自动终止该用户已经启动的所有任务(例如,终端会话)。 |
系统的 root 用户始终可以通过 Linux PAM 领域登录,并且是无需配置的管理员。此用户无法删除,但可以修改属性。系统将发送邮件到分配给该用户的电子邮件地址。
每个用户可以是多个群组的成员。群组是组织访问权限的首选方式。您应该始终授权给群组而不是单个用户。这样,您将得到一个更易于维护的访问控制列表。
API 令牌允许从另一个系统、软件或 API 客户端无状态访问 REST API 的大多数部分。可以为单个用户生成令牌,并可以授予单独的权限和到期日期,以限制访问的范围和持续时间。它可以撤销泄露的 API 令牌而无需禁用用户。
API 令牌有两种基本类型:
分离的权限: 需要使用 ACL 为令牌授予明确的访问权限,其有效权限通过交叉用户和令牌权限进行计算。
完整的权限:令牌的权限与关联用户的权限相同。
|
|
令牌的值仅在生成令牌时显示/返回一次,以后无法通过 API 再次检索它。 |
要使用 API 令牌,在发出 API 请求时将设置 HTTP 标头 授权(Authorization) 的显示值设置为 PVEAPIToken=USER@REALM!TOKENID=UUID 的形式,或者参考 API 客户端的文档。
资源池是一组虚拟机、容器和存储设备。这有助于当某些用户应以受控方式访问特定的一组资源的情况时的权限管理,因为它允许将单个权限应用于一组元素,而不必基于每个资源进行管理。资源组通常与群组一起使用,以便群组的成员对一组机器和存储拥有权限。
由于 Proxmox VE 用户只是存在于某些外部领域的用户的对应项,因此必须在 /etc/pve/domains.cfg 中配置领域。以下领域(认证方法)可用:
Linux PAM 是一个用于系统范围内用户认证的框架。这些用户是在主机上使用 adduser 等命令创建的。如果 Proxmox VE 主机系统上存在 PAM 用户,则可以在 Proxmox VE 中添加相应的条目,以允许这些用户通过其系统用户名和密码登录。
这是一个类 Unix 的密码存储,它将哈稀的密码存储在 /etc/pve/priv/shadow.cfg 。密码使用 SHA-256 哈希算法进行哈希运算。这是小型(甚至中型)的安装中最便捷的认证领域,用户无需访问 Proxmox VE 之外的任何内容。在这种情况下,用户完全由 Proxmox VE 管理,并且能够通过 GUI 更改自己的密码。
LDAP (轻型目录访问协议) 是一个开放的、使用目录服务进行认证的跨平台协议。OpenLDAP 是 LDAP 协议的一个受欢迎的的开源实现。
Microsoft Active Directory (AD,活动目录) 是适用于 Windows 域网络的目录服务,支持作为 Proxmox VE 的认证领域。它支持 LDAP 作为身份验证协议。
OpenID Connect 是作为 OATH 2.0 协议之上的身份层实现的。它允许客户端根据外部授权服务器执行的身份验证来验证用户的身份。
由于 Linux PAM 对应的是主机系统用户,因此每个允许该用户登录的节点上都必须存在一个系统用户。用户使用其常用的系统密码进行身份验证。此领域默认已添加且无法删除。在可配置性方面,管理员可以选择要求来自领域的登录进行二次验证(双因子认证),并将此领域设置为默认的认证领域。
Proxmox VE 认证服务器领域是一个简单的类 Unix 的密码存储。该领域是默认创建的,与 Linux PAM 一样,唯一可用的配置项是有为领域用户进行二次验证(双因子认证)的能力,以及将其设置为登录的默认领域。
不同于其他的 Proxmox VE 领域类型,用户完全通过 Proxmox VE 创建和认证,而不是针对另一个系统进行认证。因此,您需要在创建时为此类用户设置密码。
您还可以使用外部 LDAP 服务器进行用户认证(例如 OpenLDAP)。在这个领域类型中,使用 用户属性名称 (user_attr) 字段中指定的用户名属性,在 基本域名 (base_dn) 下搜索用户。
可以配置服务器和可选的后备服务器,并且可以通过 SSL 加密连接。此外,可以为目录和群组配置过滤器。过滤器允许您进一步限制领域的范围。
例如,如果用户通过以下 LDIF 数据集表示:
# user1 of People at ldap-test.com dn: uid=user1,ou=People,dc=ldap-test,dc=com objectClass: top objectClass: person objectClass: organizationalPerson objectClass: inetOrgPerson uid: user1 cn: Test User 1 sn: Testers description: This is the first test user.
这里的基本域名 是 ou=People,dc=ldap-test,dc=com ,用户属性是 uid 。
如果 Proxmox VE 在能够查询和认证用户之前需要认证(绑定)到 LDAP 服务器,则可以通过 /etc/pve/domains.cfg 中的 bind_dn 属性配置绑定域名。然后它的密码必须存储在 /etc/pve/priv/ldap/<realmname>.pw(例如,/etc/pve/priv/ldap/my-ldap.pw)文件中。
要验证证书,您需要设置 capath 。您可以将其直接设置为 LDAP 服务器的 CA 证书,也可以设置为包含所有受信任 CA 证书的系统路径(/etc/ssl/certs) 。此外,您需要设置 验证 选项,这也可以通过 Web 界面完成。
LDAP 服务器领域的主要配置选项如下:
领域 (realm):Proxmox VE 用户的领域标识符
基本域名 (base_dn):搜索用户的目录
用户属性名称 (user_attr):包含用户登录的用户名的 LDAP 属性
服务器 (server1):托管 LDAP 目录的服务器
后备服务器 (server2):可选的后备服务器地址,以防主服务器无法访问
端口 (port):LDAP 服务器侦听的端口
|
|
为了允许特定用户使用 LDAP 服务器进行认证,您还必须在 Proxmox VE 服务器中将他们添加为该领域的用户。这可以通过 同步 自动执行。 |
要将 Microsoft AD 设置为领域,需要指定服务器地址和认证域。Active Directory 支持大多数与 LDAP 相同的属性,例如可选的后备服务器、端口和 SSL 加密。此外,用户可以在配置后通过 同步 操作自动添加到 Proxmox VE 。
与 LDAP 一样,如果 Proxmox VE 在绑定到 AD 服务器之前需要进行认证,则必须配置绑定用户 (bind_dn) 属性。默认情况下,Microsoft AD 通常需要此属性。
Microsoft 活动目录(AD)的主要配置选项如下:
领域 (realm):Proxmox VE 用户的领域标识符
域名 (domain):服务器的 AD 域
服务器 (server1):服务器的 FQDN 或 IP 地址
后备服务器 (server2):可选的后备服务器地址,以防主服务器无法访问
端口 (port):Microsoft AD 服务器侦听的端口
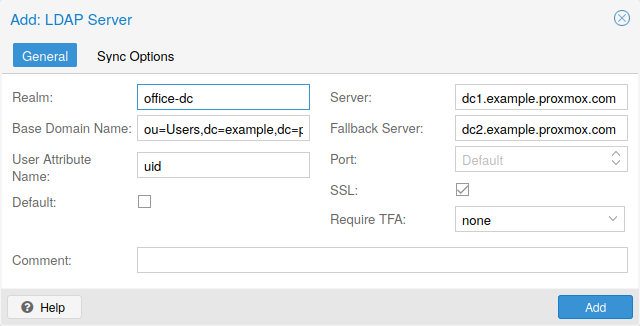
可以自动同步基于 LADP 的领域(LDAP & Microsoft Active Directory)的用户和群组,而不必手动将它们添加到 Proxmox VE 。您可以从 Web 界面的 认证 面板的“添加/编辑”窗口或通过 pveum realm add/modify 命令访问同步选项。到那时,您可以从 GUI 的 认证 面板或使用以下命令执行同步操作:
pveum realm sync <realm>
用户和群组同步到集群范围的配置文件(/etc/pve/user.cfg)。
可以在“添加/编辑”窗口的 同步选项 选项卡中找到用于同步基于 LDAP 的领域的配置选项。
配置选项如下:
绑定用户 (bind_dn):指用于查询用户和群组的 LDAP 帐户。此帐户需要访问所有所需条目。如果设置了,将通过绑定进行搜索; 否则,搜索将匿名进行。用户必须是完整的 LDAP 格式的专有名称 (DN),例如,cn=admin,dc=example,dc=com。
群组名属性 (group_name_attr):表示用户的群组。仅同步符合 user.cfg 的通常字符限制的条目。为避免命名冲突,在群组同步的名称附加 -$realm。请确保同步不会覆盖手动创建的群组。
用户类别 (user_classes):与用户关联的对象类。
群组对象类别 (group_classes):与组关联的对象类。
邮件属性:如果基于 LDAP 的服务器指定了用户电子邮件地址,则这些地址也可以通过在此处设置关联属性来包含在同步中。从命令行,这可以通过 --sync_attributes 参数实现。
用户筛选器 (filter):有关针对特定用户的进一步过滤选项。
群组筛选器 (group_filter):有关针对特定群体的进一步过滤选项。
|
| 筛选器允许您创建一组额外的匹配条件,以缩小同步范围。可以在 ldap.com 上找到有关可用的 LDAP 筛选器类型及其用法的信息。 |
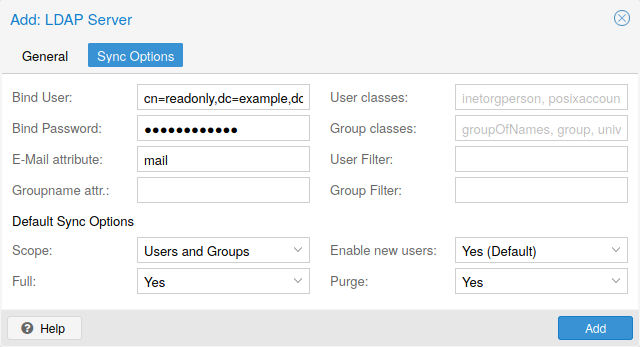
除了上一节中指定的选项之外,您还可以配置描述同步操作行为的更多选项。
这些选项要么在同步之前设置为参数,要么通过领域选项 默认同步选项 设置默认值。
同步的主要选项有:
范围 (scope):要同步的范围。它可以是 用户、群组 或 两者(用户和组)。
启用新用户 (enable-new):如果设置,新同步的用户将被启用并且可以登录。默认值是 true 。
完整 (full):如果设置,同步使使用 LDAP 目录作为真实来源,覆盖 user.cfg 中手动设置的信息并删除 LDAP 目录中不存在的用户和组。如果未设置,则只会将新数据写入配置,不会删除陈旧用户。
清除 ACL (purge):如果设置,同步会在删除用户和组时删除所有相应的 ACL。这仅对 完整 选项有用。
预览 (dry-run):没有数据写入配置。如果您想查看哪些用户和组将同步到 user.cfg,这将非常有用。
OpenID Connect 的主要配置选项是:
发行人 URL (issuer-url): 这是认证服务器的 URL 。Proxmox 使用 OpenID Connect Discovery 协议自动配置更多详细信息。
虽然可以使用未加密的 http:// URL,但我们强烈建议使用加密的 https:// 连接。
领域 (realm):Proxmox VE 用户的领域标识符
客户端 ID (client-id):OpenID 客户端 ID 。
客户端秘钥 (client-key):可选的 OpenID 客户端秘钥。
自动创建用户 (autocreate):如果用户不存在,则自动创建用户。虽然身份验证是在 OpenID 服务器上完成的,但所有用户仍然需要 Proxmox VE 用户配置中的条目。可以手动添加它们,也可以使用自动创建用户 选项来自动添加新用户。
用户名声明 (username-claim):OpenID 声明用于生成唯一的用户名(subject(主题)、username(用户名) 或 email(电子邮件))。
OpenID Connect 规范定义了一个名为 subject(主题) 的唯一属性(OpenID 术语中的 声明 )。默认情况下,我们使用此属性的值生成 Proxmox VE 用户名,只需添加 @ 和领域名称:${subject}@${realm}。
不幸的是,大多数 OpenID 服务器使用随机字符串作为 subject(主题),例如 DGH76OKH34BNG3245SB,因此典型的用户看起来像 DGH76OKH34BNG3245SB@yourrealm 。虽然独一无二,但人类很难记住这样的随机字符串,因此很难将真实用户与此联系起来。
用户名声明(username-claim) 设置允许您为用户名映射使用其他属性。如果 OpenID Connect 服务器提供该属性并保证其唯一性,则首选将其设置为 username 。
另一个选项是使用 email(电子邮件),这也会产生人类可读的用户名。同样,仅当服务器保证此属性的唯一性时才使用此设置。
以下是使用 Google 创建 OpenID 领域的范例,您需要用 Google OpenID 的设置来替换 --client-id 和 --client-key 。
pveum realm add myrealm1 --type openid --issuer-url https://accounts.google.com --client-id XXXX --client-key YYYY --username-claim email
上面的命令使用 --username-claim email,因此 Proxmox VE 端的用户名类似于 example.user@google.com@myrealm1 。
Keycloak (https://www.keycloak.org/) 是一种受欢迎的身份和访问管理的开源工具,它支持 OpenID Connect。在以下范例中,您需要将 --issuer-url 和 --client-id 替换为您的信息:
pveum realm add myrealm2 --type openid --issuer-url https://your.server:8080/auth/realms/your-realm --client-id XXX --username-claim username
使用 --username-claim username 在 Proxmox VE 端启用简单的用户名,例如 example.user@myrealm2 。
|
|
您需要确保不允许用户自己编辑用户名设置(在 Keycloak 服务器上)。 |
有两种使用二次验证的方法:
身份验证领域可能需要它,通过 TOTP(基于时间的一次性密码)或 YubiKey OTP 。在这种情况下,新创建的用户需要立即添加他们的秘钥,因为没有第二个因子就无法登录。对于 TOTP ,用户也可以稍后更改 TOTP ,前提是他们可以先登录。
或者,用户可以选择稍后加入二次验证,即使领域没有强制执行。
您可以设置多个第二个因子,以避免丢失智能手机或安全密钥将您被永久锁定在帐户之外。
除以领域强制 TOTP 和 YubiKey OTP 之外,还提供以下二级验证方法:
用户配置的 TOTP(基于时间的一次性密码)。源自共享机密和当前时间的短代码,每 30 秒更改一次。
WebAuthn (Web 认证)。认证的通用标准。它由各种安全设备实现,例如来自计算机或智能手机的硬件密钥或可信平台模块 (TPM)。
一次性使用恢复密钥。应该打印出来并锁定在安全地方或以数字方式保存在电子保险库中的密钥列表。每把钥匙只能使用一次。这些非常适合确保您不会被锁定,即使您的所有其他次要因子都丢失或损坏。
在支持 WebAuthn 之前,用户可以设置 U2F。仍然可以使用现有的 U2F 因子,但建议在服务器上配置后切换到 WebAuthn。
这可以通过在添加或编辑认证领域时通过 TFA 下拉框选择一种可用的方法来完成。当一个领域启用了 TFA 时,它要求只有配置了 TFA 的用户才能登录。
目前有两种方法可用:
这使用标准的 HMAC-SHA1 算法,其中当前时间使用用户的配置密钥进行哈稀,其中时间步长和密码长度参数为可配置的。
用户可以有配置多个密钥(使用空格分隔),密钥可以用 Base32 (RFC3548) 或十六进制表示。
Proxmox VE 提供一个密钥生成工具(oathkeygen),它以 Base32 符号打印出一个随机密钥,可以直接与各种 OTP 工具一起使用,例如 oathtool 命令行工具,或在安卓(Android)上的 Google Authenticator、FreeOTP 和 OTP 或类似的应用程序。
要通过 YubiKey 进行身份验证,必须配置 Yubico API ID、API KEY 和验证服务器 URL,并且用户必须拥有可用的 YubiKey。为了从 YubiKey 中获取密钥 ID,您可以在通过 USB 连接后触发一次 YubiKey,并将键入的密码的前 12 个字符复制到用户的 密钥 ID 字段中。
请参阅 YubiKey OTP 文档以了解如何使用 YubiCloud 或 托管您自己的验证服务器 。
用户可以选择启用 TOTP 或 WebAuthn 作为登录时报第二个因子,通过用户列表中的 TFA 按钮(除非领域强制执行 YubiKey OTP)。
用户始终可以添加和使用一次性 还原密钥。
打开 TFA 窗口后,该用户会看到一个对话框,用于设置 TOTP 认证。The 秘钥 字段包含此密钥,可以通过 随机化 按钮随机生成。可以添加一个可选的 发行者名称,以便向 TOTP 应用程序提供有关密钥所属的信息。大多数 TOTP 应用程序将显示发行者名称和相应的 OTP 值。用户名也已经包含在 TOTP 应用程序的二维码中。
生成密钥后,将会显示一个二维码,可用于大多数 OTP 应用程序(例如 FreeOTP)。然后,用户需要通过在 验证码 字段中输入当前 OTP 值,并按压 应用 按钮来验证当前用户的密码(除非以 root 身份登录),以及正确使用 TOTP 密钥的能力。
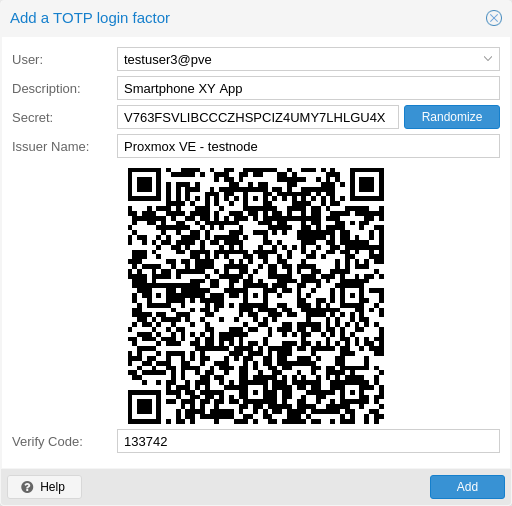
无需服务器设置。只需在智能手机上安装 TOTP 应用(例如 FreeOTP),并使用 Proxmox Backup Server 的 Web 界面添加一个 TOTP 因子。
要使 WebAuthn 工作,您需要做两件事:
受信任的 HTTPS 证书(例如,通过使用 Let’s Encrypt)。虽然它可能不适用于不受信任的证书,但如果不受信任,某些浏览器可能会警告或者拒绝 WebAuthn 操作。
设置 WebAuthn 配置(查看 Proxmox VE Web 界面里的 数据中心 → 选项 → WebAuthn 设置)。这可以在多数设置中使用自动填充。
一旦满足两个必要条件,您可以在 数据中心 → 权限 → 二次验证 下的二次验证 面板中添加 WebAuthn 配置。
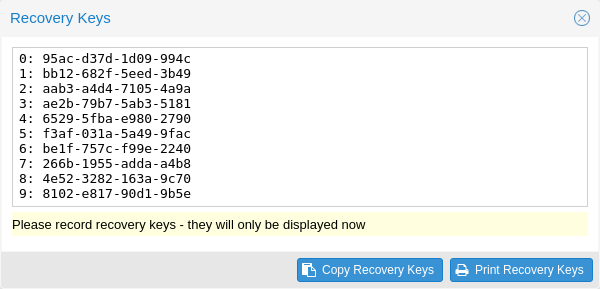
还原密钥代码无需任何准备;您可以简单地在 数据中心 → 权限 → 二次验证 下的二次验证 面板中创建一组还原密码。
|
|
每个用户在任何时候都只能有一组一次性还原密钥。 |
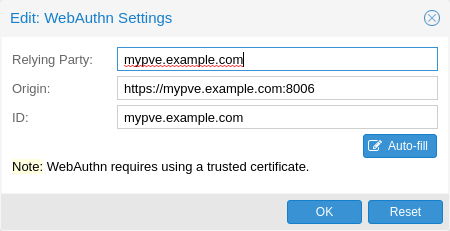
要允许用户使用 WebAuthn 认证,必须使用具有有效的 SSL 证书的有效域,否则某些浏览器可能会发出警告或完全拒绝认证。
|
|
更改 WebAuthn 配置可能会导致所有现有 WebAuthn 注册无法使用! |
这是通过 /etc/pve/datacenter.cfg 完成的。例如:
webauthn: rp=mypve.example.com,origin=https://mypve.example.com:8006,id=mypve.example.com
|
|
建议改用 WebAuthn 。 |
要允许用户使用 U2F 认证,必须使用具有有效的 SSL 证书的有效域,否则某些浏览可能会发出警告或完全拒绝使用 U2F。最初,需要配置 AppId
[AppId https://developers.yubico.com/U2F/App_ID.html]
。
|
|
更改 AppId 可能会导致所有现有 U2F 注册无法使用! |
这是通过 /etc/pve/datacenter.cfg 完成的。例如:
u2f: appid=https://mypve.example.com:8006
对于单个节点,AppId 可以简单的是 Web 接口的地址,与它在浏览器使用的完全一样,包括 https:// 和端口,如上所示。请注意,某些浏览器在匹配 AppIds 时可能会比其他浏览器更严格。
当使用多个节点时,最好有一个单独的 https 服务器提供 appid.json
[Multi-facet apps: https://developers.yubico.com/U2F/App_ID.html]
文件,因为它似乎与大多数浏览器兼容。如果所有节点使用同一顶级域的子域,则使用 TLD 为 AppId 可能就足够了。但是需要注意的是,有些浏览器可能不接受这一点。
|
|
错误的 AppId 通常会产生错误,但是我们遇到过这样的情况,特别是在 Chromium 中通过子域访问使用顶级域 AppId 的节点。基于此原因,建议使用多个浏览器测试配置,比如更改 AppId 之后将会使现有的 U2F 注册无法使用。 |
要启用 U2F 认证,打开 TFA 窗口的 U2F 选项卡,输入当前密码(除非以 root 身份登录),并按压 注册 按钮。如果服务器设置正确并且浏览器接受了该服务器提供的 AppId,则会出现一条消息提示用户按下 U2F设备上的按钮(如果是 YubiKey,按钮灯应该稳定地打开和关闭,大致每次两次)。
火狐浏览器(Firefox)用户在使用 U2F 令牌前,可能需要通过 about:config 启用 security.webauth.u2f 。
为了让用户执行操作(例如列出、修改或删除 VM 的部分配置),用户需要拥有适当的权限。
Proxmox VE 使用基于角色和路径的权限管理系统。特权表中的条目允许用户、组或令牌在访问 对象 或 路径 时承担特定的角色。这意味着这样的访问规则可以表示为(路径、用户、角色)、(路径、群组、角色)或(路径、令牌、角色)的三元组,其中角色包含一组允许的操作,路径表示这些操作的目标。
角色只是一个特权列表。Proxmox VE 带有许多预定义角色,可满足大多数要求。
Administrator:拥有完整权限
NoAccess:没有权限(用于禁止访问)
PVEAdmin:可以完成大部分任务,但无权修改系统设置(Sys.PowerMgmt,Sys.Modify,Realm.Allocate)
PVEAuditor:拥有只读权限
PVEDatastoreAdmin:创建和分配备份空间和模板
PVEDatastoreUser:分配备份空间和查看存储
PVEPoolAdmin:分配池
PVESysAdmin:用户 ACL、审计、系统控制台和系统日志
PVETemplateUser:查看和克隆模板
PVEUserAdmin:管理用户
PVEVMAdmin:完全管理 VM
PVEVMUser:查看、备份、配置 CD-ROM、 VM 控制台、 VM 电源管理
您可以在 GUI 中看到整套预定义角色。
您可以通过 GUI 或命令行添加新角色。
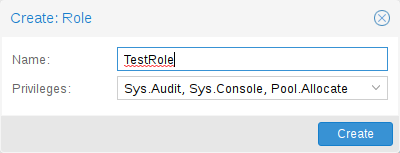
在 GUI 中,从 数据中心 导航到 权限 → 角色 选项卡,然后单击 创建 按钮。在这里您可以设置角色名称,并从 特权 下拉菜单中选择所需的任何权限。
要通过命令行添加角色,可以使用 pveum CLI 工具,例如:
pveum role add PVE_Power-only --privs "VM.PowerMgmt VM.Console" pveum role add Sys_Power-only --privs "Sys.PowerMgmt Sys.Console"
特权是执行特定操作的权利。为了简化管理,特权列表被分组到角色中,然后可以在特权表中使用。请注意,特权不能直接分配给用户和路径,而不是角色的一部分。
我们目前支持以下特权:
Permissions.Modify:修改访问权限
Sys.PowerMgmt:节点电源管理(启动、停止、重置、关机 …)
Sys.Console:控制台访问节点
Sys.Syslog:查看系统日志
Sys.Audit:查看节点状态/配置,Corosync 集群配置和 HA 配置
Sys.Modify:创建/修改/删除节点的网络参数
Group.Allocate:创建/修改/删除群组
Pool.Allocate:创建/修改/删除池
Pool.Audit:查看池
Realm.Allocate:创建/修改/删除认证领域
Realm.AllocateUser:将用户分配到领域
User.Modify:创建/修改/删除用户访问和详细信息。
VM.Allocate:在服务器上创建/删除 VM
VM.Migrate:将 VM 迁移到集群的备用服务器
VM.PowerMgmt:电源管理(启动、停止、重置、关机 …)
VM.Console:控制台访问 VM
VM.Monitor:访问 VM 监视器(kvm)
VM.Backup:备份/恢复 VM
VM.Audit:查看 VM 配置
VM.Clone:克隆/复制 VM
VM.Config.Disk:添加/修改/删除磁盘
VM.Config.CDROM:弹出/更换 CD-ROM
VM.Config.CPU:修改 CPU 设置
VM.Config.Memory:修改内存设置
VM.Config.Network:添加/修改/删除网络设备
VM.Config.HWType:修改仿真的硬件类型
VM.Config.Options:修改任何其他 VM 配置
VM.Snapshot:创建/删除 VM 快照
Datastore.Allocate:创建/修改/删除数据存储和删除卷
Datastore.AllocateSpace:在数据存储上分配空间
Datastore.AllocateTemplate:分配/上传模板和 ISO 映像
Datastore.Audit:查看/浏览数据存储
访问权限分配给对象,例如虚拟机、存储或资源池。我们使用类似路径的文件系统来寻址这些对象。这些路径形成一个自然树,更高级别(较短路径)来权限可以选择在这个层次结构中向下传播。
路径可以模板化。当 API 调用需要模板化路径的权限时,该路径可能包含对 API 调用参数的引用。这些引用在花括号中指定。一些参数隐式地取自 API 调用的 URI。例如,调用 /nodes/mynode/status 时的权限路径 /nodes/{node} 需要 /nodes/mynode 的权限,而 /access/acl 的 PUT 请求中的路径 {path} 指的是该方法的路径参数。
部分范例:
/nodes/{node}:访问 Proxmox VE 服务器机器
/vms:覆盖所有 VM
/vms/{vmid}:访问特定 VM
/storage/{storeid}:访问特定存储
/pool/{poolname}:访问包含在特定池中的资源
/access/groups:群组管理
/access/realms/{realmid}:对领域的管理访问
如前所述,对象路径形成一个类似于树的文件系统,并且该树下的对象可以继续权限(默认情况下设置了传播标志)。我们使用以下继承规则:
个人用户的权限始终替换群组权限。
当用户是该组的成员时,将应用群组的权限。
更深层次的权限将替换从更高层次继承的权限。
此外,权限分离的令牌永远不能在其关联用户没有的任何给定路径上拥有权限。
池可用于对一组虚拟机和数据存储进行分组。然后,您可以简单地设置池(/pool/{poolid})的权限,这些权限由所有池成员继承。这是简化访问控制的好方法。
每个单独的方法都记录了所需的 API 权限,可以在 https://pve.proxmox.com/pve-docs/api-viewer/ 找到。
权限被指定为一个列表,可以将其解释为逻辑树和访问检查功能:
当前列表中的每个(and)或任何(or)其他元素必须为真(true)。
path(路径)是模板化参数(请参阅 对象和路径)。必须在指定的路径上允许所有(或者,如果使用 any 选项,则为任何)列出的权限。如果指定了 require-param 选项,则即使 API 调用的架构将其列为可选参数,它的指定参数也是必需的。
调用者必须对 /access/groups 具有任何列出的权限。此外,还有两种可能的检查,具体取决于是否设置了 groups_param 选项:
groups_param 已设置:API 调用具有非可选的 群组 参数,并且调用者必须对所有列出的群组具有任何列出的权限。
groups_param 未设置:通过 userid 参数传递的用户必须存在并且是调用者具有任何列出权限的群组的一部分(通过/access/groups/<group> 路径)。
为 API 调用的 userid 参数提供的值必须指代执行操作的用户(通常与 or 结合使用,以允许用户对自己执行操作,即使他们没有提升的权限)。
用户需要 Realm.AllocateUser 访问 /access/realm/<realm>,其中 <realm> 指的是通过 userid 参数传递的用户领域。请注意,为了与领域相关联,用户不需要存在,因为用户 ID 以 <username>@<realm> 的形式传递。
path(路径)是模板化参数(请参阅 对象和路径)。用户需要 Permissions.Modify 权限,或者根据路径需要以下权限作为可能的替代:
/storage/...:另外需要“Datastore.Allocate”
/vms/...:另外需要“VM.Allocate”
/pool/...:另外需要“Pool.Allocate”
如果路径为空,则需要 Permission.Modify 上的 /access。
大多数用户将简单地使用 GUI 来管理用户。但是还有一个全功能的命令行工具,称为 pveum(Proxmox VE 用户管理,“Proxmox VE User Manager”的缩写)。请注意,所有 Proxmox VE 命令行工具都是 API 的包装器,因此您可以通过 REST API 访问这些功能。
下面是一些简单的使用范例。要显示帮助,请键入:
pveum
或(显示有关特定命令的详细帮助)
pveum help user add创建一个新用户:
pveum user add testuser@pve -comment "Just a test"设置或更改密码(并非所有领域都支持):
pveum passwd testuser@pve
禁用一个用户:
pveum user modify testuser@pve -enable 0创建一个新的群组:
pveum group add testgroup
创建一个新角色:
pveum role add PVE_Power-only -privs "VM.PowerMgmt VM.Console"管理员可能希望创建具有完全管理员权限的用户组(不使用 root 帐户)。
为此,首先定义组:
pveum group add admin -comment "System Administrators"然后分配角色:
pveum acl modify / -group admin -role Administrator最后,您可以将用户添加新的 admin 群组:
pveum user modify testuser@pve -group admin
您可以通过将 PVEAuditor 角色分配给用户或群组来授予用户只读访问的权限。
范例 1:允许用户 joe@pve 查看所有内容
pveum acl modify / -user joe@pve -role PVEAuditor范例 2:允许用户 joe@pve 查看所有虚拟机
pveum acl modify /vms -user joe@pve -role PVEAuditor
如果您想将用户管理委托给用户 joe@pve ,您可以这样做:
pveum acl modify /access -user joe@pve -role PVEUserAdmin
用户 joe@pve 现在可以添加和删除用户,以及更改其他用户的属性,例如密码。这是一个非常强大的角色,您很可能希望将其限制在所选的领域和群组中。以下范例允许 joe@pve 修改 pve 领域内的用户,如果他是 customers 群组的成员:
pveum acl modify /access/realm/pve -user joe@pve -role PVEUserAdmin pveum acl modify /access/groups/customers -user joe@pve -role PVEUserAdmin
|
| 用户可以添加其他用户,但是前提是他们是 customers 群组的成员,并且在 pve 领域内。 |
API 令牌的权限始终是其相应用户的权限的子集,这意味着 API 令牌不能用于执行支持用户无权执行的任务。本节将演示如何使用具有单独权限的 API 令牌,以进一步限制令牌所有者的权限。
在所有 VM 上为用户 joe@pve 授予 PVEVMAdmin 角色:
pveum acl modify /vms -user joe@pve -role PVEVMAdmin
添加一个新的具有单独权限的 API 令牌,该令牌仅允许查看 VM 信息(例如,用于监控目的):
pveum user token add joe@pve monitoring -privsep 1 pveum acl modify /vms -token 'joe@pve!monitoring' -role PVEAuditor
验证用户和令牌的权限:
pveum user permissions joe@pve pveum user token permissions joe@pve monitoring
一个企业通常由几个较小的部门组成,您通常希望为每个部门分配资源并委派管理任务。假设您想要为软件开发部门建立一个池。首先,创建一个组:
pveum group add developers -comment "Our software developers"现在,我们创建一个新用户,该用户是该组的成员:
pveum user add developer1@pve -group developers -password
|
|
“-password”参数将提示您输入密码 |
然后,我们创建一个资源池供我们的开发部门使用:
pveum pool add dev-pool --comment "IT development pool"最后,我们可以为该池分配权限:
pveum acl modify /pool/dev-pool/ -group developers -role PVEAdmin我们的软件开发人员现在可以管理分配给该池的资源。
我们的现代社会严重依赖计算机通过网络提供的信息。移动设备放大了这种依赖性, 因为人们可以随时随地访问网络。如果您提供这样的服务,它们大部分时间都是可用的,这一点非常重要。
我们用数学方法将可用性定义为(A)与(B)之间的比率,(A)是指在规定的时间间隔内服务可用的总时间,(B)是指该时间间隔的总长度。
| 可用率 % | 每年停机时间 |
|---|---|
99 |
3.65 天 |
99.9 |
8.76 小时 |
99.99 |
52.56 分钟 |
99.999 |
5.26 分钟 |
99.9999 |
31.5 秒 |
99.99999 |
3.15 秒 |
有几种方法可以提高可用性。最优雅的解决方案是重构您的软件,让它可以同时在多个主机运行。软件本身需要有一种方法可以检测错误并进行故障切换。如果您仅想提供只读的网页,则相对简易。然而,这通常很复杂且有时不可能实现,毕竟您不能自己修改软件。以下解决方案在不修改软件的情况下工作:
使用可靠的 “服务器” 组件
|
|
具有相同功能的计算机组件可能有不同的可靠性标识号,由组件质量决定。大多数供应商将可靠性更高的组件作为 “服务器” 组件销售 - 通常价格更高。 |
消除单点故障(冗余组件)
使用不间断电源(UPS)
在主板上使用冗余电源
使用 ECC 内存
使用冗余网络硬件
本地存储使用 RAID
为 VM 数据使用分布式的冗余存储
减少停止时间
快速反应的管理人员 (24/7)
备件保障(Proxmox VE 集群中的其它节点)
自动检测错误(由 ha-manager 提供)
自动故障转移(由 ha-manager 提供)
类似 Proxmox VE 这样的虚拟化环境,更容易实现高可用性,因为它们摆离了“硬件”的依赖,还支持设置和使用冗余存储和网络设备,所以如果一台主机发生故障,您只需在集群内的另一台主机上启动这些服务即可。
更好的是,Proxmox VE 提供了一个名为 ha-manager 的软件栈,它可以为您自动处理。它能够自动检测错误并自动故障切换。
Proxmox VE 的 ha-manager 的工作方式类似于“自动化”的管理员。首先,您可以配置它应该管理的资源(虚拟机,容器,…) 。然后,ha-manager 遵循精确的功能设计,在出现错误时将服务故障转移到另一个节点。ha-manager 还可以处理启动,停止,重新定位和迁移服务的正常用户的请示。
但是高可用性需要付出代价。高质量的组件更昂贵,且让它们形成冗余至少使成本翻一番。额外的备件进一步增加了成本。因此您需要仔细计算收益,并与这些额外的成本进行比较。
|
|
将可用性从 99% 提高到 99.9% 相对简单。但将可用性从 99.9999% 提高到 99.99999% 是非常困难且昂贵的。ha-manager 具有特有的错误检测和故障切换时间约为 2 分钟,因此您可能获得不超过 99.999% 的可用性。 |
实现高可用性(HA)前您必须满足以下需求:
至少三个集群节点(获取可靠的数量)
为虚拟机和容器共享存储
硬件冗余(每个地方)
使用可靠的 “服务器” 组件
硬件监测(watchdog) - 如果不可用,我们将回退使用 Linux 的内核软件监测 (softdog)
可选的硬件隔离设备
我们将由 ha-manager 处理的主要管理单元称为资源。资源 (也叫 “服务”) 通过服务 ID(SID)进行唯一标识,它由资源类型和特定于类型的ID组成,例如 vm:100 。此范例是指一个 vm(虚拟机)类型和 ID 为 100 的资源。
目前,我们有两种重要的资源类型 - 虚拟机和容器。这里的一个基本想法,我们可将相关软件捆绑到一个 VM 或容器中,所以无需将其它服务组成一个大服务,就像 rgmanager 一样。通常 HA 管理的资源不依赖于其它资源。
本节简要概述了常见的管理任务。第一步是为资源启用 HA 。这是通过将资源添加到 HA 资源配置来完成的。您可以使用 GUI 执行该操作,或者简单地使用命令行工具,例如:
# ha-manager add vm:100
HA Stack(堆栈)现在尝试启动资源并保持其运行。请注意,您可以配置“已请求”的资源状态。
例如,您可能希望 HA 堆栈(Stack)停止资源:
# ha-manager set vm:100 --state stopped
停止以后再启动:
# ha-manager set vm:100 --state started
您还可以使用标准的虚拟机和容器管理命令,它们会自动化将命令转发到 HA 堆栈(Stack),比如:
# qm start 100
请求的状态设置为 started。这同样适用于 qm stop,它将请求的状态设置为 stopped。
|
|
HA 堆栈(Stack)完全地异步工作,需要与其它集群成员通信。因此,您需要几秒钟才能看到这些操作的结果。 |
要查看当前 HA 的资源配置,请使用:
# ha-manager config
vm:100
state stopped
查看 HA 管理器和资源的实际状态,请使用:
# ha-manager status quorum OK master node1 (active, Wed Nov 23 11:07:23 2016) lrm elsa (active, Wed Nov 23 11:07:19 2016) service vm:100 (node1, started)
您还可以迁移资源到其它节点,请使用:
# ha-manager migrate vm:100 node2
这里使用在线迁移并尝试保持虚拟机运行。在线迁移需要通过网络传输所有已用内存,因此,有时停止虚拟机,然后在新节点重新启动它会更快。这可以使用 relocate 命令来完成:
# ha-manager relocate vm:100 node2
最后,您可以从 HA 配置中移除资源,使用下面命令:
# ha-manager remove vm:100
|
|
这不会启动或停止该资源。 |
但是所有 HA 相关的任务都可以在 GUI 中完成,因此不需要使用命令行。
本节提供 Proxmox VE HA 管理器内部的详细说明。它描述了所有涉及的守护进程以及它们如何协同工作。要使用 HA,每个节点上要运行两个守护进程:
本地资源管理器 (LRM),它控制本地节点上运行的服务。它从当前管理器状态文件中读取其服务的请求状态,并执行相应的命令。
集群资源管理 (CRM),它制订集群范围内的决策。它向 LRM 发送命令,处理结果,并在出现故障时将资源移动到其它节点。CRM 还处理节点隔离。
|
|
LRM & CRM 中的锁 锁由我们的分布式配置文件系统(pmxcfs)提供。它们用于保证每个 LRM 都激活一次并正常工作。由于 LRM 仅在持有锁时才执行操作,因此如果我们可以获取其锁,我们可以将故障节点标记为已防护。这让我们可以安全地恢复任何失败的 HA 服务,而不受现在未知的失败节点的任何干扰。这一切都由当前持有管理器主锁的 CRM 监督。 |
CRM 使用服务状态枚举来记录当前服务状态,此状态会显示在 GUI 上,还可以使用 ha-manager 命令行工具查询:
# ha-manager status quorum OK master elsa (active, Mon Nov 21 07:23:29 2016) lrm elsa (active, Mon Nov 21 07:23:22 2016) service ct:100 (elsa, stopped) service ct:102 (elsa, started) service vm:501 (elsa, started)
以下是可能的状态列表:
服务已停止(由 LRM 确认)。如果 LRM 检测到停止的服务仍然在运行,它将再次停止该服务。/p>
服务应该被停止,CRM 等待 LRM 的确认。
等待停止请求。但是 CRM 到目前为止还没有收到请求。
服务处于活动状态,如果 LRM 尚未运行,则应尽快启动它。如果服务失败并被检测到未运行,LRM 将重新启动它(请参阅 启动失败策略)。
挂起的启动请求。但是 CRM 没有得到 LRM 的任何确认,即该服务正在运行。
等待节点防护,因为服务节点不在仲裁集群分区内(请参阅 防护)。一旦节点被成功隔离,服务将被置于恢复状态。
等待服务恢复。HA 管理器尝试找到可以运行服务的新节点。此搜索不仅取决于在线和仲裁节点的列表,还取决于服务是否为群组成员以及如何限制此类群组。一旦发现新的可用节点,服务将被移动到那里并最初置于停止状态。如果它被配置为运行新节点就会这样做。
不可以接触的服务状态。我们在重新启动节点或重新启动 LRM 守护程序时使用此状态(请参阅 软件包更新)。
表现得好像服务根本不是由 HA 管理的。如果需要暂时完全控制服务,而无需将其从 HA 配置中删除,则此功能非常有用。
迁移服务(实时)到其它节点。
由于 LRM 错误,服务被禁用。需要人工干预(请参阅 错误恢复)。
服务是新增的,CRM 目前还没看到。
服务已停止并标记为 已禁用
本地资源管理器(pve-ha-lrm)在引导启动时作为守护进程启动,并等待 HA 集群达到规定数量,从而集群范围的锁开始工作
它可以有三种状态:
LRM 等待我们的独占锁。如果没有配置服务,这也用作空闲状态。
LRM 持有其独占锁并配置了服务。
LRM 失去了锁定,这意味着发生了故障并且失去了仲裁。
LRM 进入活动(active)状态后,它会读取管理器状态文件(/etc/pve/ha/manager_status),并确定它有为其拥有的服务执行的命令。对于工作程序启动的每个命令,这些工作程序并行运行,默认情况下最多限制为 4 个。此默认设置可以通过数据中心配置 max_worker 键值进行更改。完成后,工作进程会被收集起来,并将其结果保存到 CRM 中。
|
|
工作程序(Worker)最大并发数调整提示 最多 4 个并发工作器的默认值可能不适合特定设置。例如,可能同时发生 4 个实时迁移,这可能会由于慢速网络和(或)大的(内存方面)服务而导致网络拥塞。例外,确保在最坏的情况下拥塞最小,即使这意味着降低 max_worker 的值。相反,如果您有一个特别强大的高端设置,您可能还想增加它。 |
CRM 请求的每个命令都由 UID 唯一标识。当工作程序完成时,其结果将被处理并写入 LRM 状态文件 /etc/pve/nodes/<nodename>/lrm_status。CRM 可以在那里收集它并让它的状态机器 - 对应于命令输出 - 对其进行操作。
CRM 和 LRM 之间对每个服务上的操作通常总是同步的。这意味着 CRM 请求一个由 UID 唯一标识的状态,然后 LRM 执行 一次 该动作并回写结果,结果也可以通过相同的 UID 识别。这是必需的,以便 LRM 不会执行过时的命令。这种行为的唯一例外是 停止 和 错误 命令;这两个不依赖于产生的结果,并且总是在停止状态的情况下执行,在错误状态的情况下执行一次。
|
|
阅读日志 HA 堆栈(Stack)记录它执行的每个动作,这有助于了解集群中发生了什么以及为什么会发生某些事情。在这里,了解 LRM 和 CRM 两个守护程序的作用很重要。您可以在服务所在的节点上使用 journalctl -u pve-ha-lrm 并在当前主节点上对 pve-ha-crm 使用相同的命令。 |
集群资源管理器(pve-ha-crm)在每个节点上启动在等待管理器锁,该锁一次只能由一个节点持有。成功获取管理器锁的节点被提升为 CRM 主节点。
它可以有三种状态:
CRM 等待我们的独占锁。如果没有配置服务,这也用作空闲状态。
CRM 持有其独占锁并配置了服务。
CRM 失去了锁定,这意味着发生了故障并且失去了仲裁。
它的主要任务是管理被配置为高可用的服务,并尝试始终强制执行请求的状态。例如,如果服务尚未运行,则将启动具有启动请求状态的服务。如果它崩溃,它将自动重新启动。因此,CRM 规定了 LRM 需要执行的操作。
当节点离开集群仲裁(quorum)时,其状态更改为未知。如果当前的 CRM 可以保护故障节点的锁,则服务将被 偷偷地移到(stolen) 另一个节点上重启。
当集群成员确定它不再位于集群仲裁(quorum)中时,LRM 将等待形成新的仲裁(quorum)。只要没有仲裁(quorum),节点就无法重置监控功能( watchdog)。这将在监控功能( watchdog)超时后触发重启(这发生在 60 秒后)。
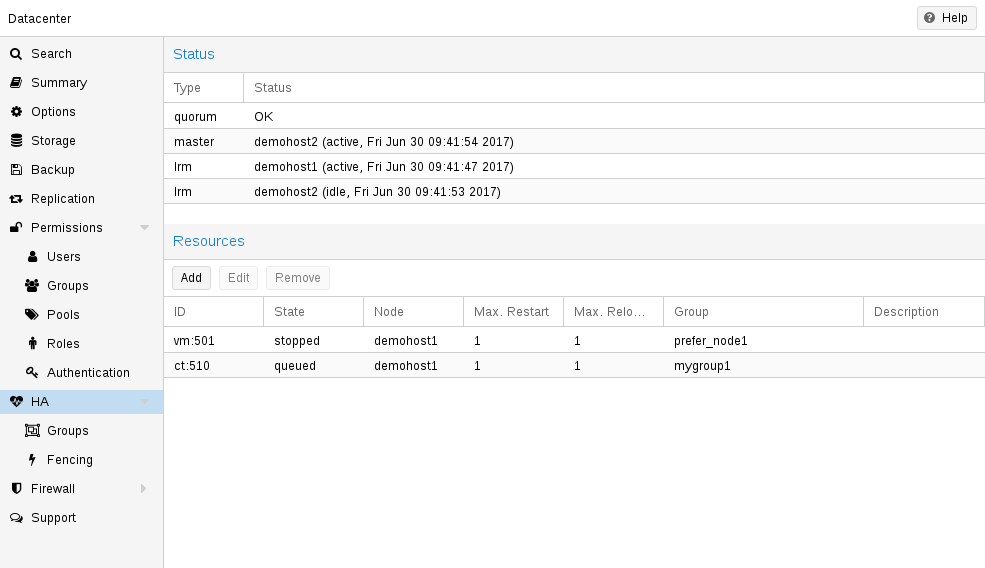
通过使用 HA 模拟器,您可以测试和学习 Proxmox VE HA 解决方案的所有功能。
默认情况下,模拟器允许您观察和测试具有 6 个 VM 的真实 3 个节点集群的表现行为。您还可以添加或删除附加的 VM 和容器。
您不必设置或配置真正的集群,HA 模拟器开箱即用。
使用 apt 安装:
apt install pve-ha-simulator
您甚至可以在任何基于 Debian 的系统上安装该软件包,而无需任何其他 Proxmox VE 软件包。为此,您需要下载该软件包并将其复制到您要在其上运行以进行安装的系统。当您从本地文件系统使用 apt 安装软件包时,它还会为您解析所需的依赖项。
要在远程机器上启动模拟器,必须可以将 X11 重定向到当前系统。
如果您使用的是 Linux 机器,则可以使用:
ssh root@<IPofPVE> -Y
在 Windows 上,它可以通过 mobaxterm 工作。
连接到安装了模拟器的现有 Proxmox VE 或手动将其安装在本地基于 Debian 系统上后,您可以按如下方式进行尝试。
首先,您需要创建一个工作目录,模拟器在其中保存其当前状态并写入其默认配置:
mkdir working
然后,只需将创建的目录作为参数传递给 pve-ha-simulator:
pve-ha-simulator working/
然后,您可以启动、停止、迁移模拟的 HA 服务,甚至检查节点故障时会发生什么。
HA 堆栈(stack)很好地集成到 Proxmox VE API 中。因此,例如,可以通过 ha-manager 命令行界面或 Proxmox VE Web 界面 - 这两个界面都提供了一种管理 HA 的简单方法。自动化工具可以直接使用 API 。
所有 HA 配置文件都在 /etc/pve/ha/ 中,因此它们会自动分发到集群节点,并且所有节点共享相同的 HA 配置。
资源配置文件 /etc/pve/ha/resources.cfg 存储了由 ha-manager 管理的资源列表。该资源配置文件内的列表类似于:
<type>: <name>
<property> <value>
...它以资源类型开头,后跟资源特定名称,以冒号分隔。这一起构成了 HA 资源 ID,所有的 ha-manager 命令都使用它来唯一标识资源(例如:vm:100 或 ct:101)。下一行包含其他属性:
描述。
HA 组标识符。
服务启动失败时,尝试服务重新定位的最大次数。
节点启动失败后,尝试在节点上重新启动服务的最大次数。
请求的资源状态。CRM 读取此状态并相应地采取行动。请注意,enabled 只是 started 的别名。
CRM 尝试启动资源。服务成功启动后,服务状态设置 started(已启动) 。在节点故障或启动失败时,它会尝试恢复资源。如果一切都失败,服务状态设置为 error(错误)。
CRM 尝试将资源保持在 stopped(已停止) 状态,但它仍会尝试在节点故障时重新定位资源。
CRM 尝试将资源置于 stopped(已停止) 状态,但不会尝试在节点故障时重新定位资源。此状态的主要目的是error(错误)恢复,因为它是将资源移出错误状态的唯一方法。
该资源从管理器状态中删除,因此 CRM 和 LRM 不再接触该资源。所有影响此资源的 Proxmox VE API 调用都将被执行,直接绕过 HA 堆栈(stack),CRM 命令将被丢弃,资源不会在节点故障时重新定位。
这是一个包括 VM 和一个容器的真实范例。如您所见,这些文件的语法非常简单,因此甚至可以使用您喜欢的编辑器读取或编辑这些文件:
vm: 501
state started
max_relocate 2
ct: 102
# Note: use default settings for everything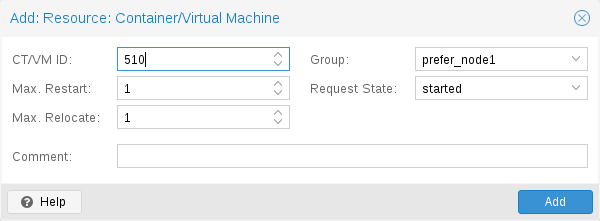
上面的配置是使用 ha-manager 命令行工具生成的:
# ha-manager add vm:501 --state started --max_relocate 2 # ha-manager add ct:102
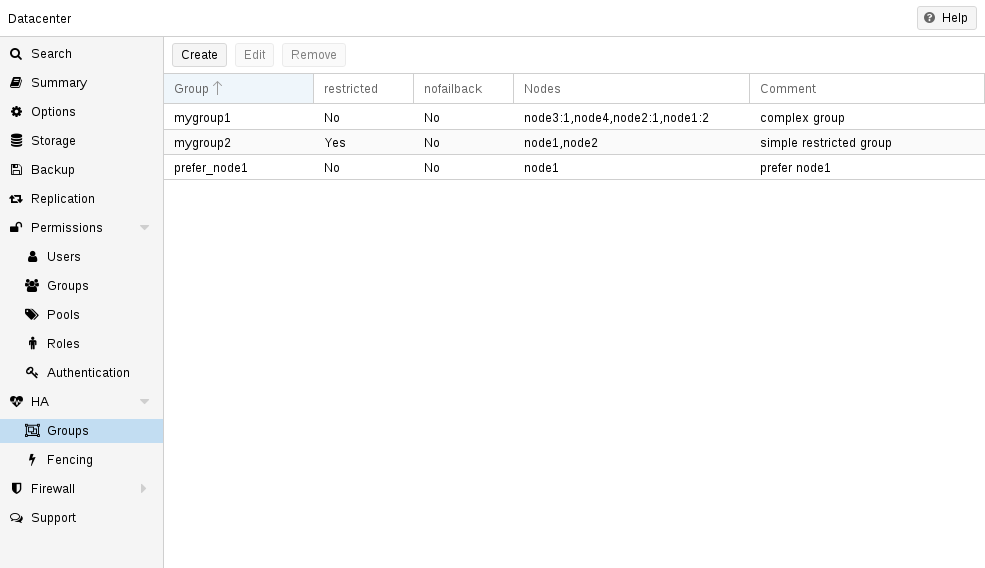
HA 组配置文件 /etc/pve/ha/groups.cfg 用于定义集群节点组。可以限制资源仅在此类组的节点成员上运行。组配置如下所示:
group: <group>
nodes <node_list>
<property> <value>
...描述。
集群节点成员列表,其中可以给每个节点一个优先级。绑定到组的资源将在具有最高优先级的可用节点上运行。如果最高优先级类别中有更多节点,则服务将分配到这些节点。优先级仅具有相对意义。
CRM 尝试在具有最高优先级的节点上运行服务。如果具有更高优先级的节点上线,CRM 会将服务迁移到该节点。启用 nofailback 可以防止这种行为。
绑定到受限组的资源只能在该组定义的节点上运行。如果没有组节点成员在线,该资源将处于停止状态。如果所有组成员都离线,则不受限制组上的资源可以在任何集群节点上运行,但一旦组成员上线,它们就会迁移回来。可以使用只有一个成员的不受限制的组来实现 首选节点 的行为。
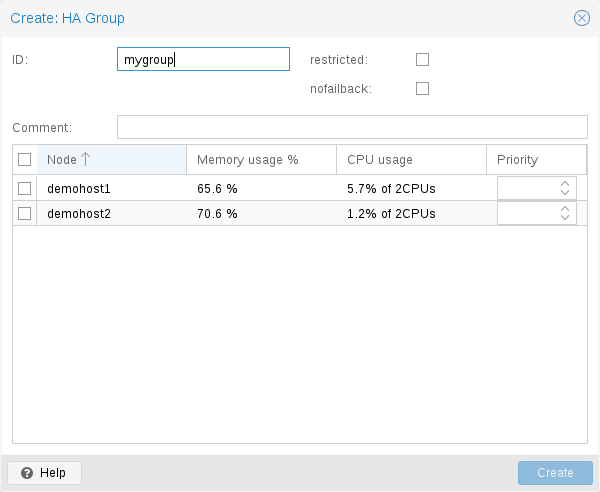
一个常见的要求是资源应该在特定节点上运行。通常资源能够在其他节点上运行,因此您可以定义一个具有单个成员的不受限制的组:
# ha-manager groupadd prefer_node1 --nodes node1
对于更大的集群,定义更详细的故障转移行为是有意义的。例如,如果可能,您可能希望在 node1 上运行一组服务。如果 node1 不可用,则希望在 node2 和 node3 上平均拆分运行它们。如果这些节点也失败,则服务应在 node4 上运行。为此,您可以将节点列表设置为:
# ha-manager groupadd mygroup1 -nodes "node1:2,node2:1,node3:1,node4"
另一个用例是,如果资源使用仅在特定节点上可用的其他资源,例如 node1 和 node2 。我们需要确保 HA 管理器不使用其他节点,因此我们需要使用所述节点创建一个受限组:
# ha-manager groupadd mygroup2 -nodes "node1,node2" -restricted
上述命令创建了以下组配置文件:
group: prefer_node1
nodes node1
group: mygroup1
nodes node2:1,node4,node1:2,node3:1
group: mygroup2
nodes node2,node1
restricted 1nofailback 选项主要用于在管理任务期间避免不必要的资源移动。例如,如果您需要将服务迁移到组中没有最高优先级的节点,您需要通过设置 nofailback 选项告诉 HA 管理器不要立即将该服务移回。
另一种情况是当一个服务被隔离并且它被恢复到另一个节点时。管理员尝试修复受防护的节点并再次使其联机以调查故障原因并检查它是否再次稳定运行。设置 nofailback 标志可防止恢复的服务直接移回受防护的节点。
在节点故障时,隔离 确保错误的节点保证处于离线状态。这是确保在另一个节点上恢复时没有资源运行两次的必要条件。这是一项非常重要的任务,因为没有它,就不可能在另一个节点上恢复资源。
如果一个节点没有被隔离,它将处于未知状态,它可能仍然可以访问共享资源。这真的很危险! 想象一下,除了存储之外的所有网络都崩溃了。现在,虽然无法从公共网络访问,但 VM 仍在运行并写入共享存储。
如果我们在另一个节点上简单的启动 VM ,我们将得到一个危险的竞态条件,因为我们从两个节点都写入。这种情况可能会破坏所有 VM 的数据,并且整个 VM 可能无法使用。如果存储可以防止多次挂载,恢复也可能失败。
有不同的方法来隔离节点,例如,隔离设备会切断节点的电源或完全禁用它们的通信。这些通常非常昂贵,并且会为系统带来额外的关键组件,因为如果它们出现故障,您将无法恢复任何服务。
因此,我们希望集成一种更简单的隔离方法,它不需要额外的外部硬件。这可以使用监控功能(watchdog)的定时器来完成。
外部电源开关
通过禁用交换机上的完整网络流量来隔离节点
使用监控功能(watchdog)定时器的自我隔离
自微控制器出现以来,监控功能(watchdog)的定时器已广泛应用于关键和可靠的系统中。它们通常是简单、独立的集成电路,用于检测计算机故障并从故障中恢复。
在正常操作期间,ha-manager 会定期重置监控功能(watchdog)的定时器以防止其超时。如果由于硬件故障或程序错误,计算机无法重置监控功能(watchdog),计时器将结束并触发整个服务器的重置(重启)。
最近的服务器主板通常包括这样的硬件监控(watchdog),但是这些需要配置。如果没有可用的或配置的监控功能(watchdog),我们就回退到 Linux 内核的 (软监控功能)softdog 。虽然仍然可靠,但它不独立于服务器硬件,因此可靠性低于硬件监控(watchdog)。
默认情况下,出于安全原因,所有硬件监控功能(watchdog)的模块都被阻止。如果没有正确初始化,它们就像上了膛的枪。要启用硬件监控功能(watchdog),您需要在 /etc/default/pve-ha-manager 里指定加载的模块,例如:
# select watchdog module (default is softdog) WATCHDOG_MODULE=iTCO_wdt
此配置由 watchdog-mux 服务读取,该服务在启动时加载指定的模块。
在节点发生故障并且其防护成功后,CRM 尝试将服务从故障节点移动到仍然在线的节点。
恢复这些服务的节点的选择受到 资源组设置、当前活动节点的列表以及它们各自的活动服务计数的影响。
CRM 首先根据用户选择的节点(来自 组 设置)和可用节点之间的交集构建一个集合。然后选择具有最高优先级的节点子集,最后选择具有最低活动服务计数的节点。这最大限度地减少了节点过载的可能性。
|
|
在节点发生故障时,CRM 将服务分发到其余节点。这会增加这些节点上的服务数量,并可能导致高负载,尤其是在小型集群上。请设计您的集群,使其能够处理这种最坏的情况。 |
如果服务在节点上启动失败一次或多次,启动失败策略就会生效。它可用于配置在同一节点上触发重启的频率以及重新定位服务的频率,以便尝试在另一个节点上启动。此策略的目的是避免特定节点上共享资源的暂时不可用。例如,如果共享存储在法定节点上不再可用,例如由于网络问题,但在其他节点上仍然可用,重定位策略仍然允许服务启动。
有两个服务启动恢复策略设置,可以针对每个资源进行配置。
尝试在实际节点上重新启动失败服务的最大次数。默认设置为 1 。
尝试将服务重定位到不同节点的最大次数。只有在实际节点上超过 max_restart 值后,才会发生重新定位。默认设置为 1。
|
|
只有当服务至少成功启动一次时,重定位计数状态才会重置为零。这意味着如果服务在没有修复错误的情况下重新启动,则只会重复重新启动策略。 |
如果在所有尝试之后都无法恢复服务状态,则将其置于错误状态。在这种状态下,该服务将不再受到 HA 堆栈(stack)的影响。唯一的方式是禁用服务:
# ha-manager set vm:100 --state disabled
这也可以在 Web 界面中完成。
要从错误状态中恢复,您应该执行以下操作:
使资源恢复到安全且一致的状态(例如:如果服务无法停止,则终止其进程)
禁用资源以移除错误标志
修复导致此失败的错误
修复所有错误以后,您可以请求重新启动服务
当更新 ha-manager 时,您应该一个接一个地更新节点,而不是出于各种原因一次全部更新。首先,虽然我们彻底测试了我们的软件,但不能完全排除影响您特定设置的错误。一个接一个地更新一个节点并在完成更新后检查每个节点的功能有助于从最终问题中恢复,而一次性更新所有可能会导致集群损坏,通常不是一个好习惯。
此外,Proxmox VE HA 堆栈(stack)使用一个请求确认协议在集群和本地资源管理器之间执行操作。为了重启,LRM 向 CRM 发出请求以冻结其所有服务。这可以防止它们在 LRM 重启时被集群短时间内接触到。之后,LRM 可以在重启期间安全地关闭监控功能(watchdog)。这种重启通常发生在软件包更新期间,并且如前所述,需要一个活动的主 CRM 来确认来自 LRM 的请求。如果不是这种情况,更新过程可能需要很长时间,在最坏的情况下,可能会导致监控功能(watchdog)触发重置。
有时需要关闭或重新启动节点来执行维护任务,例如更换硬件,或者只是安装新的内核映像。使用 HA 堆栈(stack)时也是如此,可以配置关闭期间 HA 堆栈(stack)的行为。
您将在下面找到对节点关闭的不同 HA 策略的描述。由于要向后兼容,当前 条件 是默认值。部分用户可能会发现 迁移 的行为更符合预期。
一旦本地资源管理(LRM)收到关机请求并启用此策略,它会将自身标记为对当前 HA 管理器不可用。这会触发当前位于该节点上的所有 HA 服务的迁移。LRM 将尝试延迟关机过程,直到所有正在运行的服务都被移走。但是,这要求正在运行的服务可以迁移到另一个节点。换句话说,服务不能是本地绑定的,例如通过使用硬件直通。由于如果没有可用的组成员,则将非组成员节点视为可运行的目标,因此在仅选择某些节点的情况下使用 HA 组时仍然可以使用此策略。但是,将组标记为受限会告诉 HA 管理器该服务不能在所选节点集之外运行。如果所有这些节点都不可用,则关闭将挂起,直到您手动干预。一旦关闭的节点重新上线,如果它们之间还没有手动迁移,之前被取代的服务将被移回。
|
|
在关机时的迁移过程中,监控功能(watchdog)仍然处于活动状态。如果节点丢失规定数量(quorum),它将被隔离并且服务将被恢复。 |
如果您在当前正在维护的节点上启动(先前停止的)服务,则需要对该节点进行防护,以确保该服务可以在另一个可用节点上移动和启动。
这种模式确保所有服务都已停止,如果当前节点没有很快上线,它们也会被恢复。比如在集群规模上进行维护时,如果同时关闭太多节点,可能无法进行 VM 的实时迁移,但您仍然希望确保 HA 服务尽快恢复并重新启动,它可能很有用。
这种模式确保所有服务都已停止和冻结,直到当前节点再次上线前它们不会恢复。
关机 条件 策略会自动检测是否请求关机或重启,并相应地更改行为。
如果计划让保持节点关闭一段时间,通常会执行关机(电源关闭)。LRM 会停止所有托管服务,这意味着其他节点将在之后接管这些服务。
|
|
近来硬件都有大量的内存(RAM)。所以我们停止所有资源,然后重启它们以避免所有内存的在线迁移。如果要使用在线迁移,则需要在关闭节点之前手动调用它。 |
通过 reboot 命令开始重启节点。这通常是在安装新内核之后完成的。请注意,这与“关机”不同,因为节点会立即重新启动。
LRM 告诉 CRM,它要重启,并等待 CRM 将所有资源置于 冻结(freeze) 状态(软件包更新 使用相同的机制)。这可以防止这些资源被移动到其他节点。相反,CRM 在同一节点上重启后启动相应资源。
最后不能不提,您可以在关机或重启节点之前手动将资源移动到其他节点。优点是您可以拥有完全的控制权,且您可以决定是否要使用在线迁移。
|
|
请不要 终止(kill) 像 pve-ha-crm、pve-ha-lrm 或 watchdog-mux 这样的服务。它们管理并使用监控功能(watchdog),因此这可能会导致节点立即重启,甚至重置。 |
备份是任何合理的 IT 部署的必要条件,Proxmox VE 提供了一个完全集成的解决方案,利用了每个存储和每个来宾系统类型的功能。这允许系统管理员通过 模式(mode) 选项在备份的一致性和来宾系统的停机时间之间进行微调。
Proxmox VE 的备份始终是完全备份 - 包含 VM 或 CT 的配置和所有数据。通过 GUI 或者通过 vzdump 命令行工具启动备份。
在运行备份之前,必须定义备份存储。有关如何添加存储的信息,请参阅存储文档。备份存储必须是文件级存储,因为备份存储为常规文件。在多数情况下,使用 NFS 服务器是存储备份的好方法。您可以稍后将这些备份保存到磁带驱动器,用于异地归档。
可以为可选节点和来宾系统安排备份作业,以便它们在特定日期和时间自动执行备份作业。计划备份的配置在 GUI 中的数据中心级别完成,这将在 /etc/pve/jobs.cfg 中生成一个作业条目,然后由 pvescheduler 守护进程解析和执行。这些作业使用 日历事件(calendar events) 来定义计划。
有几种方法可以提供一致性(模式 选项),具体取决于来宾类型。
此模式提供了最高的备份一致性,但代价是 VM 操作时需要短暂的停机时间。它的工作原理是有序地关闭 VM ,然后在后台运行 Qemu 进程来备份 VM 数据。备份启动后,VM 将进入完全操作模式(如果之前正在运行)。通过使用实时备份功能可以保证一致性。
提供此模式是由于兼容性原因,并在调用 快照 模式之前挂起 VM 。由于挂起 VM 会导致更长的停机时间,并且不一定会提高数据的一致性,因此推荐使用 快照 模式。
这个模式提供了最短的操作停机时间,但代价是很小的不一致风险。它的工作原理是通过 VM 运行时复制数据块,以执行 Proxmox VE 实时备份。如果来宾代理已启用(agent: 1)并正在运行,它会调用 guest-fsfreeze-freeze 和 guest-fsfreeze-thaw 以提高一致性。
可以 在线 找到 QemuServer 的 Proxmox VE 实时备份的技术概述。
|
|
Proxmox VE 实时备份在任何存储类型上提供类似快照语义。它不要求底层存储支持快照。另请注意,由于备份是通过后台 Qemu 进程完成的,因此在 Qemu 读取 VM 磁盘时,停止的 VM 将显示为运行一小段时间。但是,VM 本身并未启动,仅读取它的磁盘。 |
在备份期间停止容器。这可能会导致很长的停机时间。
此模拟使用 rsync 将容器数据复制到临时位置(请参阅选项 --tmpdir)。然后,容器被挂起,第二个 rsync 复制更改的文件。之后,容器再次启动(恢复)。这会导致非常短的停机时间,但是需要额外的空间来保存容器副本。
当容器是在本地文件系统上,并且备份的目标存储是 NFS/CIFS 服务器时,您应该将 --tmpdir 也设置为驻留在本地文件系统上,因为这将导致成倍的性能提升。如果备份存储是 NFS 服务器,您想要在挂起模式下使用 ACL 备份本地容器,则还需要使用本地 tmpdir 。
此模式使用底层存储的快照功能。首先,容器会被挂起来保护数据的一致性。接着生成容器的卷的临时快照,并将快照内容归档为一个 tar 文件。最后,临时快照再次被删除。
|
|
快照(snapshot) 模式要求所有备份的卷都放在支持快照的存储上。使用 backup=no 挂载点选项可以从备份中排除单个卷(因此这是一项要求)。 |
|
|
默认情况下,备份中不包含根磁盘挂载点以外的其他挂载点。对于卷挂载点,您可以设置 备份 选项,在备份中包括挂载点。设备和绑定挂载永远不会备份,因为它们的内容在 Proxmox VE 存储库之外进行管理。 |
较新版本的 vzdump 将来宾类型和备份时间编码到文件名中,例如
vzdump-lxc-105-2009_10_09-11_04_43.tar
这样就可以在同一个目录中存储多个备份。您可以使用各种保留选项限制保留的备份数量,请参阅下面的 备份保留 部分。
备份文件可以使用其中一个算法进行压缩:lzo
[Lempel–Ziv–Oberhumer 一种无损数据压缩算法 https://en.wikipedia.org/wiki/Lempel-Ziv-Oberhumer]
、gzip
[gzip - 基于 DEFLATE 算法 https://en.wikipedia.org/wiki/Gzip]
或 zstd
[Zstandard 一种无损数据压缩算法 https://en.wikipedia.org/wiki/Zstandard]
。
目前,Zstandard (zstd) 是这三种算法中最快的。多线程是 zstd 相对于 lzo 和 gzip 的另一个优势。Lzo 和 gzip 使用更广泛,通常是默认安装。
您可以安装 pigz
[pigz - gzip的并行实现 https://zlib.net/pigz/]
作为 gzip 的替代品,并通过多线程提供更好的性能。对于 pigz 和 zstd ,可以调整线程/核心的使用数量。请参阅下面的 配置选项 。
备份文件的扩展名通常可用于确定它使用哪种压缩算法来创建备份。
.zst |
Zstandard (zstd) 压缩 |
.gz or .tgz |
gzip 压缩 |
.lzo |
lzo 压缩 |
如果备份文件名中不以上述文件扩展名之一结尾,则说明它没有被 vzdump 压缩。
对于 Proxmox 备份服务器存储,您可以选择设置客户端的备份加密,请查阅 相应部分 。
使用 prune-backups 选项,您可以灵活地指定要保留的备份。提供以下可用的保留选项:
保留所有备份。如果是 true ,则无法设置其他选项。
保留最后 <N> 个备份。
保留过去 <N> 个小时的备份。如果一小时内有多个备份,则仅保留最新的备份。
保留过去 <N> 天的备份。如果一天内有多个备份,则仅保留最新的备份。
保留过去 <N> 周的备份。如果一周内有多个备份,则仅保留最新的备份。
|
|
周 从星期一开始,星期日结束。本软件使用 ISO 周日期 系统并正确处理年末的星期。 |
保留过去 <N> 个月的备份。如果一个月内有多个备份,仅保留最新的备份。
保留过去 <N> 年的备份。如果一年内有多个备份,仅鉙最新的备份。
保留选项通过上面给出的顺序进行处理。每个选项仅涵盖其时间段内的备份。下一个选项不处理已经涵盖的备份。它只会考虑较旧的备份。
指定使用逗号分隔的保留选项的列表,例如:
# vzdump 777 --prune-backups keep-last=3,keep-daily=13,keep-yearly=9
虽然您可以将 prune-backups 直接传递给 vzdump ,但是在存储级别的配置上设定通常更明智,这可以通过 Web 界面完成。
|
|
旧的 maxfiles 选项已弃用,应替换为 keep-last ,或者通过设置 maxfiles 为 0 来无限保留的情况,则应替换为 keep-all 。 |
您可以使用 Proxmox 备份服务器文档的 Prune 模拟器 来探索不同的保留选项对于各种备份计划的影响。
备份的频率和旧备份的保留可能取决于数据的变化,和备份的较旧状态在特定工作负载中的重要性。当备份成为公司的归档文档,可能还存在关于备份必须保留多长时间的法律要求。
对于此范例,我们假设您正在执行每日备份,保留期为 10 年,并且备份存储的时间间隔逐渐增长。
keep-last=3 - 即使只进行每日备份,管理员也可能希望在一个大的升级前后创建一个额外的备份。设置 keep-last 可以确保这一点。
keep-hourly 未设置 - 对于每日备份,这无关紧要。您已经使用 keep-last 覆盖了额外的手动备份。
keep-daily=13 - 与 keep-last 一起,至少涵盖一天,这可以确保您拥有至少两周的备份。
keep-weekly=8 - 确保您有至少两个完整月份的每周备份。
keep-monthly=11 - 与之前的保留设置一起使用,确保您有至少一年的每月备份。
keep-yearly=9 - 这是用于长期存档的。当您使用之前的选项覆盖当前年份时,您可以将其余选项设置为 9 ,从而为您提供至少 10 年的覆盖期。
我们建议您使用一个比您的环境最低要求更高的保留期;如果您发现它过高,您可以随时减少它,但是一旦它们被删除,您就无法重新创建备份。
可以通过 Proxmox VE Web GUI 或以下 CLI 工具恢复备份存档:
容器还原实用程序
虚拟机还原实用程序
有关详细信息,请参阅相应的手册页。
恢复一个或多个大备份可能需要大量资源,尤其是同时从备份存储读取和写入到目标存储的存储带宽。因为对存储的访问会变得拥护,这会对其他虚拟来宾产生负面影响。
为避免这种情况,您可以为备份作业设置带宽限制。Proxmox VE 对于恢复和存档提供了两种限制:
每次恢复限制:表示从备份存档中读取的最大带宽量
每次存储写入限制:表示用于写入指定存储的最大带宽量
读取限制间接影响到写入限制,因为我们无法写入的比读取的多。一个较小的每个作业将覆盖较大的每个存储限制。如果您对受影响的存储具有“Data.Allocate”的权限,则更大的每个作业限制将只会覆盖每个存储限制。
您可以在恢复 CLI 命令中使用“--bwlimit <integer>”选项来设置恢复作业特定的带宽限制。使用 KB/s 作为限制的单位,这意味着传递“10240”将限制备份的读取速度为 10MB/s ,应确保剩余的存储带宽可用于已经运行的虚拟来宾,并且备份不影响来宾的操作。
|
|
您可以对 bwlimit 参数使用“0”来取消特定恢复作业的所有限制。有助于尽快恢复非常重要的虚拟来宾。(需要在存储上拥有“Data.Allocate”权限) |
大多数情况下,您的存储的通常可用带宽随着时间的推移保持不变,因此我们实现了为每个配置的存储设置默认带宽限制的可能性,这可以通过以下方式完成:
# pvesm set STORAGEID --bwlimit restore=KIBs
恢复大型备份可能需要很长时间,会让其中的来宾仍然不可用。对于存储在 Proxmox 备份服务器上的 VM 备份,可以使用实时恢复选项来缩短此等待时间。
通过 GUI 中的复选框或 qmrestore 的 --live-restore 参数启用实时恢复会导致虚拟机在恢复开始后立即启动。数据在后台复制时,优先考虑 VM 正在访问的块。
请注意,这有两个注意事项:
在实时恢复期间,VM 将以有限的磁盘读取速度运行,因为必须从备份服务器加载数据(一旦加载,目标存储中的数据将立即可用,因此两次访问数据只会导致第一次的损失)。写入速度基本上不受影响。
如果因任何原因实时还原失败,VM 将处于一个未定义状态 - 也就是说,并非所有数据都已从备份中复制,并且 极有可能 无法保留在失败的还原操作期间写入的任何数据。
这种操作模式对于大型 VM 特别有用,其中初始操作只需要少量数量,例如 Web 服务器 - 一旦操作系统和必要的服务已经启动,VM 就可以运行,而后台任务继续复制很少使用的数据。
使用存储 GUI 的 备份 选项卡中的 文件恢复 按钮,可以在包含数据的备份上直接打开一个文件浏览器。此功能仅适用于 Proxmox 备份服务器上的备份。
对于容器,文件树的第一层显示了所有包含的 pxar 存档,可以自由的打开和浏览。对于 VM ,第一层显示包含的驱动器映像,可以打开它来展示驱动器上支持的存储技术列表。在最基本的情况下,这将是一个称为 part 的条目,代表一个分区表,它包含该驱动器上找到的每个分区的条目。请注意,对于 VM ,并非所有数据都可以访问(不支持的来宾文件系统、存储技术等)。
可以使用 下载 按钮下载文件和目录,后者会即时压缩成 zip 存档。
要启用可能包含不受信任数据的 VM 映像的安全访问,将启动一个临时的 VM (来宾不可见)。这并不意味着从此类存档下载的数据本质上是安全,但它避免了将管理程序系统暴露于危险之中。VM 将在超时后自行停止。从用户的角度看,整个过程是透明的。
OPTION: value
文件中的空白行会被忽略,以 # 字符开头的行被视为注释,也会被忽略。此文件中的值会用作默认值,并且可以在命令行上覆盖。
我们目前支持以下选项:
限制 I/O 带宽(单位:KB/s)。
压缩转储文件。
将生成的文件存储到指定目录。
排除某些文件/目录(shell globs)。以 / 开头的路径锚定到容器的根目录,其他路径相对匹配到每个子目录。
设置 CFQ ionice 的优先级(CFQ ionice:I/O 调度器)
等待全局锁定的最长时间(分钟)。
指定何时发送电子邮件
应该接收电子邮件通知的电子邮件地址或用户的逗号分隔列表。
已弃用:使用 prune-backups 代替。每个来宾系统的最大备份文件数量。
备份模式。
当 N>0 时,使用 pigz 而不是 gzip。N=1 使用一半的核心,N>1 使用 N 作为线程数。
备份指定池中包含的所有已知来宾系统。
使用这些保留选项而不是存储配置中的保留选项。
保留所有备份。当为 true 时,与其他选项冲突。
保留过去 <N> 天的备份。如果一天内有多个备份,则仅保留最新的一个。
保留过去 <N> 个不同小时的备份。如果一个小时内有多个备份,则仅保留最新的一个。
保留最后 <N> 个备份。
保留过去 <N> 个不同月份的备份。如果单个月内有多个备份,则仅保留最新的一个。
保留过去 <N> 周的备份。如果一周内有多个备份,则仅保留最新的一个。
保留过去 <N> 年的备份。如果一年内有多个备份,则仅保留最新的一个。
根据 prune-backups 缩减较旧的备份。
使用指定的挂钩脚本。
排除临时文件和日志。
等待来宾系统停止的最长时间(分钟)。
将生成的文件存储到此存储中。
存储临时文件到指定目录。
Zstd 线程。N=0 使用一半的可用核心,N>0 使用 N 作为线程数。
tmpdir: /mnt/fast_local_disk storage: my_backup_storage mode: snapshot bwlimit: 10000
您可以使用选项 --script 指定一个挂钩脚本。在备份过程的各个阶段调用此脚本,并相应的设置参数。您可以在文档目录(vzdump-hook-script.pl)中找到范例。
|
|
此选项仅适用于容器备份。 |
vzdump 默认跳过以下文件(使用选项 --stdexcludes 0 禁用)
/tmp/?* /var/tmp/?* /var/run/?*pid
您还可以手动指定(附加)排除路径,例如:
# vzdump 777 --exclude-path /tmp/ --exclude-path '/var/foo*'
不包括目录 /tmp/ 以及任何名为 /var/foo 、/var/foobar 等的文件或目录。
不以 / 开头的路径不会锚定到容器的根目录,但是会相对匹配到任何子目录。例如:
# vzdump 777 --exclude-path bar
排除名为 /bar、/var/bar、/var/foo/bar 等任何文件或目录,但不包括 /bar2 。
配置文件也存储在备份存档内部(在 ./etc/vzdump/ 中),并将被正确恢复。
只需转储来宾 777 - 无快照,仅将来宾的私人区域和配置文件存档到默认转储目录(通常为 /var/lib/vz/dump/)。
# vzdump 777
使用 rsync 和挂起/恢复来创建快照(最短停机时间)。
# vzdump 777 --mode suspend
备份所有来宾系统并向 root 和管理员发送通知邮件。
# vzdump --all --mode suspend --mailto root --mailto admin
使用快照模式(无停机时间)和非默认转储目录。
# vzdump 777 --dumpdir /mnt/backup --mode snapshot
备份多个来宾(有选择地),并向 root 发送通知邮件。
# vzdump 101 102 103 --mailto root
备份所有来宾,排除 101 和 102 来宾。
# vzdump --mode suspend --exclude 101,102
将容器恢复到新的 CT 600
# pct restore 600 /mnt/backup/vzdump-lxc-777.tar
将 QemuServer VM 恢复到 VM 601
# qmrestore /mnt/backup/vzdump-qemu-888.vma 601
使用管道将现有容器 101 克隆到具有 4GB 根文件系统的新容器 300
# vzdump 101 --stdout | pct restore --rootfs 4 300 -
这个守护进程在 127.0.0.1:85 上公开了完整的 Proxmox VE API 。它以 root 身份运行,并有权执行所有特权操作。
|
|
守护进程仅侦听本地地址,因此您无法从外部访问它。pveproxy 守护进程将 API 暴露给外界。 |
此守护进程使用 HTTPS 在 TCP 端口 8006 上公开完整的 Proxmox VE API 。它以 www-data 用户身份运行,并且权限非常有限。需要更多权限的操作会被转发到本地守护进程 pvedaemon 。
针对其他节点的请求会自动转发到这些节点。这意味着您可以通过连接到单个 Proxmox VE 节点来管理整个集群。
可以配置类似“apache2”的访问控制列表。从文件 /etc/default/pveproxy 读取值。例如:
ALLOW_FROM="10.0.0.1-10.0.0.5,192.168.0.0/22" DENY_FROM="all" POLICY="allow"
可以使用 Net::IP 理解的任何语法来指定 IP 地址。名称 all 是 0/0 和 ::/0 的别名(表示所有 IPv4 和 IPv6 地址)。
默认策略(policy)是 允许(allow)。
| Match | POLICY=deny | POLICY=allow |
|---|---|---|
Match Allow only |
allow |
allow |
Match Deny only |
deny |
deny |
No match |
deny |
allow |
Match Both Allow & Deny |
deny |
allow |
默认情况下,pveproxy 和 spiceproxy 守护进程侦听通配符地址并接受来自 IPv4 和 IPv6 客户端的连接。
通过在 /etc/default/pveproxy 中设置 LISTEN_IP ,您可以控制 pveproxy 和 spiceproxy 守护进程绑定到哪个 IP 地址。需要在系统上配置 IP 地址。
通过 sysctl net.ipv6.bindv6only 设置为非默认值 1 ,将导致守护进程仅接受来自 IPv6 客户端的连接,同时通常还会导致许多其他问题。如果您设置此配置,我们建议您删除 sysctl 设置,或者将 LISTEN_IP 设置为 0.0.0.0(这将只允许 IPv4 客户端)。
LISTEN_IP 可用于将套接字(socket)限制为内部接口,从而减少暴露到公共 Internet,例如:
LISTEN_IP="192.0.2.1"
同样,您也可以设置 IPv6 地址:
LISTEN_IP="2001:db8:85a3::1"
请注意,如果您想要指定一个 IPv6 的链路本地地址,还需要提供接口自身的名称。例如:
LISTEN_IP="fe80::c463:8cff:feb9:6a4e%vmbr0"
|
|
集群中的节点需要访问 pveproxy 用于通信,可能在不同的子网上。不建议 在集群系统上设置 LISTEN_IP 。 |
要应用更改,您需要重启节点或完全重启 pveproxy 和 spiceproxy 服务:
systemctl restart pveproxy.service spiceproxy.service
|
|
不同于 重载(reload),重启(restart) pveproxy 服务可能会中断一些长期运行的工作进程,例如正在运行控制台或 shell 的虚拟来宾。因此,请使用维护窗口来使该更改生效。 |
您可以在 /etc/default/pveproxy 中定义密码列表,例如
CIPHERS="ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-SHA384:ECDHE-RSA-AES256-SHA384:ECDHE-ECDSA-AES128-SHA256:ECDHE-RSA-AES128-SHA256"
以上是默认值。有关所有可用选项的列表,请参见 openssl 软件包中的 ciphers(1) 手册页。
此外,您可以设置客户端选择使用 /etc/default/pveproxy 中的密码(默认是客户端和 pveproxy 都可用的列表中的第一个密码):
HONOR_CIPHER_ORDER=0
您可以通过将 DHPARAMS 设置为一个包含 DH 参数的 PEM 格式的文件路径,定义为 /etc/default/pveproxy 中的 Diffie-Hellman 参数,例如
DHPARAMS="/path/to/dhparams.pem"
如果未设置此选项,将使用内置的 skip2048 参数。
|
|
DH 参数仅在协商使用 DH 密钥交换算法的密码套件时才使用。 |
您可以将使用的证书更改为外部证书或通过 ACME 获得的证书。
pveproxy 使用 /etc/pve/local/pveproxy-ssl.pem 和 /etc/pve/local/pveproxy-ssl.key(如果存在),故障时使用 /etc/pve/local/pve-ssl.pem 和 /etc/pve/local/pve-ssl.key 。私钥不能使用密码。
有关详细信息,请参阅文档的主机系统管理章节。
默认情况下,如果客户端支持,pveproxy 对可压缩的内容使用 HTTP 级别的 gzip 压缩。这可以在 /etc/default/pveproxy 中禁用。
COMPRESSION=0
该守护进程定期查询 VM 、存储和容器的状态。把结果发送到集群中的所有节点。
SPICE(独立计算环境简单协议,Simple Protocol for Independent Computing Environments 的简称)是一个开放的远程计算解决方案,提供远程显示和设备(例如键盘、鼠标、音频)的客户端访问。主要的用案是远程访问虚拟机和容器。
该守护进程侦听 TCP 端口 3128,并实现一个 HTTP 代理用来将 SPICE 客户端的 连接 请求转发到正确的 Proxmox VE VM 。它以 www-data 用户身份运行,并且权限非常有限。
可以配置类似“apache2”的访问控制列表。从文件 /etc/default/pveproxy 读取值。更多详细信息请参阅 pveproxy 文档。
该守护进程负责按计划启动作业,例如复制和 vzdump 作业。
此工具用于处理 Proxmox VE 订阅。
尝试从挂载在 PATH(默认使用 /)的硬盘上收集一些 CPU 或硬盘的性能数据:
所有 CPU 的 bogoMIPS 总和
每秒正则表达式数(perl 性能测试),应在 300000 以上
硬盘大小
简单的硬盘读取测试。现代硬盘应该至少达到 40 MB/s
测试平均寻道时间。快速 SCSI 硬盘的值小于 8 毫秒。常见的 IDE/SATA 磁盘获取的值从 15 到 20 毫秒不等。
值应该大于 200(您应在 RAID 控制器上启用 回写 缓存模式 - 需要电池备份缓存(BBWC) )。
解析外部 DNS 名称的平均时间
解析本地 DNS 名称的平均时间
Proxmox VE 管理工具(pvesh)允许直接调用 API 函数,而无需使用 REST/HTTPS 服务器。
|
|
只允许 root 执行此操作。 |
获取集群中的节点列表
# pvesh get /nodes
获取数据中心的可用选项列表
# pvesh usage cluster/options -v
将 HTML5 NoVNC 控制台设置为数据中心的默认控制台
# pvesh set cluster/options -console html5
|
|
新的常见问题解答会附加在本节的底部。 |
Proxmox VE 基于什么发行版?
Proxmox VE 基于 Debian GNU/Linux
Proxmox VE 项目使用什么许可证?
Proxmox VE 的代码是根据 GNU Affero General Public License, version 3 进行许可的。
Proxmox VE 可以在 32 位处理器上运行吗?
Proxmox VE 仅适用于 64 位 CPU(AMD 或 Intel)。本平台没有 32 位的计划。
|
|
VM 和容器可以是 32 位和 64 位的。 |
我的 CPU 是否支持虚拟化?
要检查您的 CPU 是否兼容虚拟化,请检查此命令输出中的 vmx 或 svm 标记:
egrep '(vmx|svm)' /proc/cpuinfo
支持的 Intel CPU
支持 Intel 虚拟化技术 (Intel VT-x) 的 64 位处理器。(Intel VT 和 64 位处理器列表)
支持的 AMD CPU
支持 AMD 虚拟化技术 (AMD-V) 的 64 位处理器。
什么是容器/虚拟环境 (VE)/虚拟专用服务器 (VPS)?
在容器的上下文中,这些术语都是指操作系统级别的虚拟化概念。操作系统级别的虚拟化是一种虚拟化方式,其中操作系统的内核允许多个隔离的实例共享内核。当提到 LXC,我们将此类实例称为容器。因为容器使用主机的内核而不是模拟一个完整的操作系统,它们所需开销较少,但是仅限于 Linux 来宾。
什么是 QEMU/KVM 来宾(或 VM )?
QEMU/KVM 来宾(或 VM )是使用 QEMU 和 Linux KVM 内核模块在 Proxmox VE 下运行虚拟化的来宾系统。
什么是 QEMU?
QEMU 是一个通用的开源机器模拟器和虚拟器。QEMU 使用 Linux KVM 内核模块通过直接在主机 CPU 上执行来宾代码来实现接近原生的性能。它不仅限于 Linux 来宾,还允许运行任意的操作系统。
我的 Proxmox VE 版本将支持多长时间?
Proxmox VE 支持的版本至少只要对应的 Debian 版本是 oldstable 。Proxmox VE 使用一个滚动发布模型,并且始终推荐使用最新的稳定版本。
| Proxmox VE 版本 | Debian 版本 | 首次发布 | Debian EOL | Proxmox EOL |
|---|---|---|---|---|
Proxmox VE 7.x |
Debian 11 (Bullseye) |
2021-07 |
tba |
tba |
Proxmox VE 6.x |
Debian 10 (Buster) |
2019-07 |
2022-07 |
2022-07 |
Proxmox VE 5.x |
Debian 9 (Stretch) |
2017-07 |
2020-07 |
2020-07 |
Proxmox VE 4.x |
Debian 8 (Jessie) |
2015-10 |
2018-06 |
2018-06 |
Proxmox VE 3.x |
Debian 7 (Wheezy) |
2013-05 |
2016-04 |
2017-02 |
Proxmox VE 2.x |
Debian 6 (Squeeze) |
2012-04 |
2014-05 |
2014-05 |
Proxmox VE 1.x |
Debian 5 (Lenny) |
2008-10 |
2012-03 |
2013-01 |
如何将 Proxmox VE 升级到下一个版本?
次要版本升级,例如从版本 5.1 的 Proxmox VE 升级到版本 5.2 ,可以像任何正常更新一样完成,可以通过 GUI 的 节点 → 更新 面板或者通过 CLI 运行以下命令:
apt update apt full-upgrade
|
|
始终确保您正确设置了软件包存储库,并且只有在 apt update 没有遇到任何错误时才继续实际升级。 |
同样支持主要版本升级,例如从 Proxmox VE 4.4 升级到 5.0 。它们必须经过仔细计划和测试,并且在没有准备好当前备份的情况下,绝不 应该启动它们。虽然具体的升级步骤取决于您各自的设置,但我们提供了有关如何执行升级的常规说明和建议:
LXC vs LXD vs Proxmox 容器 vs Docker
LXC 是 Linux 内核包含特性的用户空间接口。通过强大的 API 和简单的工具,它可以让 Linux 用户轻松创建和管理系统的容器。LXC 与之前的 OpenVZ 一样,都是针对 系统虚拟化。因此,它允许您在容器内运行完整的操作系统,您可以在其中使用 SSH 登录、添加用户、运行 apache 等。
LXD 建立在 LXC 之上,以提供新的、更好的用户体验。在底层,LXD 通过 liblxc 及其 Go 绑定使用 LXC 来创建和管理容器。它基本上是 LXC 的工具和分发模板系统的替代品,具有可通过网络控制的附加功能。
Proxmox 容器是指使用 Proxmox 容器工具箱(pct)创建和管理的容器。它们还针对 系统虚拟化 并使用 LXC 作为容器产品的基础。Proxmox 容器工具箱(pct)与 Proxmox VE 紧密结合。这意味着它能感知集群设置,并且可以使用与 QEMU VM 相同的网络和存储资源。甚至您可以使用 Proxmox VE 防火墙、创建和恢复备份,或使用 HA 框架管理容器。一切都可以使用 Proxmox VE 的 API 通过网络进行控制。
Docker 的目标是在一个隔离的、自包含的环境中运行 单个 应用程序。这些通常被称为“应用程序容器”,而不是“系统容器”。您可以使用 Docker Engine 命令行界面从主机管理 Docker 实例。不建议直接在您的 Proxmox VE 主机上运行 docker 。
|
|
如果您需要运行应用程序容器,比如 Docker 映像,最好在一台 Proxmox Qemu 虚拟机内部运行它们。 |
[Ahmed16] Wasim Ahmed. Mastering Proxmox - Third Edition(精通 Proxmox - 第三版). Packt Publishing, 2017. ISBN 978-1788397605
[Ahmed15] Wasim Ahmed. Proxmox Cookbook. Packt Publishing, 2015. ISBN 978-1783980901
[Cheng14] Simon M.C. Cheng. Proxmox High Availability(Proxmox 高可用性). Packt Publishing, 2014. ISBN 978-1783980888
[Goldman16] Rik Goldman. Learning Proxmox VE(学习 Proxmox VE). Packt Publishing, 2016. ISBN 978-1783981786
[Surber16]] Lee R. Surber. Virtualization Complete: Business Basic Edition. Linux Solutions (LRS-TEK), 2016. ASIN B01BBVQZT6
[Hertzog13] Raphaël Hertzog & Roland Mas. The Debian Administrator's Handbook: Debian Jessie from Discovery to Mastery, Freexian, 2013. ISBN 979-1091414050
[Bir96] Kenneth P. Birman. Building Secure and Reliable Network Applications. Manning Publications Co, 1996. ISBN 978-1884777295
[Walsh10] Norman Walsh. DocBook 5: The Definitive Guide. O’Reilly & Associates, 2010. ISBN 978-0596805029
[Richardson07] Leonard Richardson & Sam Ruby. RESTful Web Services. O’Reilly Media, 2007. ISBN 978-0596529260
[Singh15] Karan Singh. Learning Ceph. Packt Publishing, 2015. ISBN 978-1783985623
[Singh16] Karan Signh. Ceph Cookbook Packt Publishing, 2016. ISBN 978-1784393502
[Mauerer08] Wolfgang Mauerer. Professional Linux Kernel Architecture. John Wiley & Sons, 2008. ISBN 978-0470343432
[Loshin03] Pete Loshin, IPv6: Theory, Protocol, and Practice, 2nd Edition. Morgan Kaufmann, 2003. ISBN 978-1558608108
[Loeliger12] Jon Loeliger & Matthew McCullough. Version Control with Git: Powerful tools and techniques for collaborative software development. O’Reilly and Associates, 2012. ISBN 978-1449316389
[Kreibich10] Jay A. Kreibich. Using SQLite, O’Reilly and Associates, 2010. ISBN 978-0596521189
可以使用 --output-format 参数指定输出格式。默认格式 text 使用 ASCII-art 在表格周围绘制漂亮的边框。它还将一些值转换为人类可读的文本,例如:
Unix 纪元显示为 ISO 8601 日期字符串。
持续时间显示为周/日/小时/分钟/秒计数,即 1d 5h(1 天 5 小时) 。
字节大小值包括单位(B、KB、MB、GB、TB、PB)。
分数显示为百分比,即 1.0 显示为 100% 。
您还可以使用选项 --quiet 完全禁止输出。
调用输出呈现函数以生成人类可读的文本。
不绘制边框(对于 text 格式)。
不显示列标题(对于 text 格式)。
输出格式。
禁止打印结果。
pvesm <COMMAND> [ARGS] [OPTIONS]
pvesm add <type> <storage> [OPTIONS]
创建一个新的存储。
存储类型。
存储标识符。
授权支持
基础卷。该卷会自动激活。
块大小
设置带宽 / IO 限制的各种操作。
用于 comstar 视图的主机组
用于 comstar 视图的目标组
允许的内容类型。
|
|
值 rootdir 用于容器,值 images 用于 VM 。 |
Proxmox 备份服务器的数据存储(datastore)名称。
禁用存储的标志。
CIFS 域。
加密密钥。使用 autogen 自动生成一个,无需密码。
NFS 导出路径。
证书的 SHA 256 指纹。
默认的映像格式。
Ceph 文件系统名称。
通过 FUSE 挂载 CephFS 。
假设给定路径是外部托管的挂载点,如果未挂载,则认为存储离线。使用布尔值(yes 或 no)作为在此字段中使用目标路径的快捷方式。
iscsi provider
客户端的 keyring 文件内容(用于外部集群)。
始终通过 krbd 内存模块访问 rbd 。
Linux LIO 目标的目标网络端口(portal)组
Base64 编码,PEM 格式的 RSA 公钥。用于加密将要添加到每个加密备份中的加密密钥的副本。
已弃用:改用 prune-backups 。每个 VM 的最大备份文件数。使用 0 表示无限制。
如果目录不存在,则创建该目录。
监视器的 IP 地址(用于外部集群)。
挂载点
RBD 命名空间。
在文件上设置 NOCOW 标志。禁用数据校验,同时允许直接 I/O 而导致的数据错误无法恢复。仅当数据不需要比在没有底层 RAID 系统的单个 ext4 格式的磁盘上更安全时才使用此选项。
集群节点名称的列表。
在目标上禁用写入缓存
NFS 挂载选项(请参阅 man nfs)
访问共享/数据存储(datastore)的密码。
文件系统路径。
资源池。
用于非默认端口。
iSCSI 网络端口(portal)(可选端口的 IP 或 DNS 名称)。
用于 raw 和 qcow2 映像的预分配模式。在 raw 映像上使用 metadata 会导致 preallocation=off 。
首先处理具有较短间隔的保留选项,其中 --keep-last 是第一个。每个选项都涵盖特定的时间段。我们说这段时间内的备份包含在该选项中。下一个选项不处理已覆盖的备份,而只考虑较旧的备份。
删除逻辑卷(LV)时清零数据。
擦除吞吐量(cstream -t 参数值)。
服务器 IP 或 DNS 名称。
备用 volfile 服务器 IP 或 DNS 名称。
|
|
需要选项:server |
CIFS 共享。
将存储标记为共享。
SMB 协议版本。如果未设置默认值 default ,则协商客户端和服务器都支持的最高 SMB2+ 版本。
使用稀疏卷。
挂载子目录。
仅使用带有 pve-vm-ID 标记的逻辑卷。
iSCSI 目标(target)。
LVM 精简池的逻辑卷(LV)名称。
Gluster 传输:tcp 或 rdma 。
RBD 的 ID 。
卷组(VG)名称。
Glusterfs 卷。
pvesm alloc <storage> <vmid> <filename> <size> [OPTIONS]
分配磁盘映像。
存储标识符。
指定所有者的 VM
要创建的文件的名称。
大小以 KB(1024 字节)为单位。可选后缀 M(MB,1024KB)和 G(GB,1024MB)。
没有可用的描述
|
|
需要选项:size |
pvesm apiinfo
返回 APIVER 和 APIAGE。
pvesm cifsscan
用于 pvesm scan cifs 的别名。
pvesm export <volume> <format> <filename> [OPTIONS]
在内部用于导出卷。
卷标识符
导出流格式
目标文件名
用于启动增量流的快照
要导出的快照
要传输的快照的有序列表
是否在流中包含中间快照
pvesm extractconfig <volume>
从 vzdump 备份存档中提取配置。
卷标识符
pvesm free <volume> [OPTIONS]
删除卷
卷标识符
等待任务完成的时间。如果任务在该时间内完成,我们返回 null 。
存储标识符。
pvesm glusterfsscan
用于 pvesm scan glusterfs 的别名。
pvesm help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pvesm import <volume> <format> <filename> [OPTIONS]
在内部用于导入卷。
卷标识符
输入流格式
源文件名。作为 - stdin(标准输入)使用 ,则 tcp://<IP-or-CIDR> 格式允许使用 TCP 连接,unix://PATH-TO-SOCKET 格式为一个 UNIX 套接字输入。否则,文件被视为通用文件。
如果请求的卷 ID 已存在,就选择一个新的卷 ID,而不是引发错误。
增量流的基本快照
成功时要删除的快照
如果流包含快照,则为当前状态快照
流是否包含中间快照
pvesm iscsiscan
用于 pvesm scan iscsi 的别名。
pvesm list <storage> [OPTIONS]
列出存储内容。
存储标识符。
仅列出该类型的内容。
仅列出该 VM 的映像
pvesm lvmscan
用于 pvesm scan lvm 的别名。
pvesm lvmthinscan
用于 pvesm scan lvmthin 的别名。
pvesm nfsscan
用于 pvesm scan nfs 的别名。
pvesm path <volume>
获取指定卷的文件系统路径
卷标识符
pvesm prune-backups <storage> [OPTIONS]
缩减备份。仅考虑使用标准命名方案。如果未指定保留选项,则使用存储配置中的选项。
存储标识符。
只显示哪些要被缩减,不要删除任何内容。
保留所有备份。值为 true 时与其他选项冲突。
保留过去 <N> 天的备份。如果一天内有多个备份,则仅保留最新的一个。
保留过去 <N> 个不同小时的备份。如果一个小时内有多个备份,则仅保留最新的一个。
保留最后 <N> 个备份。
保留过去 <N> 个不同月份的备份。如果单个月内有多个备份,则仅保留最新的一个。
保留过去 <N> 周的备份。如果一周内有多个备份,则仅保留最新的一个。
保留过去 <N> 年的备份。如果一年内有多个备份,则仅保留最新的一个。
仅考虑 qemu 或者 lxc 这两种类型的来宾的备份。
只考虑此来宾的备份。
pvesm remove <storage>
删除存储配置。
存储标识符。
pvesm scan cifs <server> [OPTIONS]
扫描远程 CIFS 服务器。
服务器地址(名称或 IP)。
SMB 域(Workgroup)。
用户密码。
用户名。
pvesm scan glusterfs <server>
扫描远程 GlusterFS 服务器。
服务器地址(名称或 IP)。
pvesm scan iscsi <portal>
扫描远程 iSCSI 服务器。
iSCSI 网络端口(portal)(可选端口的 IP 或 DNS 名称)。
pvesm scan lvm
列出本地 LVM 卷组(VG)。
pvesm scan lvmthin <vg>
列出本地 LVM 精简池。
没有可用的描述
pvesm scan nfs <server>
扫描远程 NFS 服务器。
服务器地址(名称或 IP)。
pvesm scan pbs <server> <username> --password <string> [OPTIONS] [FORMAT_OPTIONS]
扫描远程 Proxmox 备份服务器。
服务器地址(名称或 IP)。
用户名或 API 令牌 ID 。
证书的 SHA 256 指纹。
用户密码或 API 令牌密码。
可选端口。
pvesm scan zfs
扫描本地节点上的 zfs 池列表。
pvesm set <storage> [OPTIONS]
更新存储配置。
存储标识符。
块大小
设置带宽 / IO 限制的各种操作。
用于 comstar 视图的主机组
用于 comstar 视图的目标组
允许的内容类型。
|
|
值 rootdir 用于容器,值 images 用于 VM 。 |
您要删除的设置列表。
当前配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
禁用存储的标志。
CIFS 域。
加密密钥。使用 autogen 自动生成一个,无需密码。
证书的 SHA 256 指纹。
默认的映像格式。
Ceph 文件系统名称。
通过 FUSE 挂载 CephFS 。
假设给定路径是外部托管的挂载点,如果未挂载,则认为存储离线。使用布尔值(yes 或 no)作为在此字段中使用目标路径的快捷方式。
客户端的 keyring 文件内容(用于外部集群)。
始终通过 krbd 内存模块访问 rbd 。
Linux LIO 目标的目标网络端口(portal)组
Base64 编码,PEM 格式的 RSA 公钥。用于加密将要添加到每个加密备份中的加密密钥的副本。
已弃用:改用 prune-backups 。每个 VM 的最大备份文件数。使用 0 表示无限制。
如果目录不存在,则创建该目录。
监视器的 IP 地址(用于外部集群)。
挂载点
RBD 命名空间。
在文件上设置 NOCOW 标志。禁用数据校验,同时允许直接 I/O 而导致的数据错误无法恢复。仅当数据不需要比在没有底层 RAID 系统的单个 ext4 格式的磁盘上更安全时才使用此选项。
集群节点名称的列表。
在目标上禁用写入缓存
NFS 挂载选项(请参阅 man nfs)
访问共享/数据存储(datastore)的密码。
资源池。
用于非默认端口。
用于 raw 和 qcow2 映像的预分配模式。在 raw 映像上使用 metadata 会导致 preallocation=off 。
首先处理具有较短间隔的保留选项,其中 --keep-last 是第一个。每个选项都涵盖特定的时间段。我们说这段时间内的备份包含在该选项中。下一个选项不处理已覆盖的备份,而只考虑较旧的备份。
删除逻辑卷(LV)时清零数据。
擦除吞吐量(cstream -t 参数值)。
服务器 IP 或 DNS 名称。
备用 volfile 服务器 IP 或 DNS 名称。
|
|
需要选项:server |
将存储标记为共享。
SMB 协议版本。如果未设置默认值 default ,则协商客户端和服务器都支持的最高 SMB2+ 版本。
使用稀疏卷。
挂载子目录。
仅使用带有 pve-vm-ID 标记的逻辑卷。
Gluster 传输:tcp 或 rdma 。
RBD 的 ID 。
pvesm status [OPTIONS]
获取所有数据存储的状态。
仅列出支持此内容类型的存储。
仅列出已启用的存储(在配置中未禁用)。
包括有关格式的信息
仅列出指定存储的状态
如果目标与 节点(node) 不同,我们只列出在该 节点(node) 和指定 目标(target) 节点上可以访问内容的共享存储。
pvesm zfsscan
用于 pvesm scan zfs 的别名。
pvesubscription <COMMAND> [ARGS] [OPTIONS]
pvesubscription delete
删除该节点的订阅密钥。
pvesubscription get
读取订阅信息。
pvesubscription help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pvesubscription set <key>
设置订阅密钥。
Proxmox VE 订阅密钥
pvesubscription update [OPTIONS]
更新订阅信息。
始终连接到服务器,即使我们在本地缓存中有最新信息。
pveperf [PATH]
pveceph <COMMAND> [ARGS] [OPTIONS]
pveceph createmgr
用于 pveceph mgr create 的别名。
pveceph createmon
用于 pveceph mon create 的别名。
pveceph createosd
用于 pveceph osd create 的别名。
pveceph createpool
用于 pveceph pool create 的别名。
pveceph destroymgr
用于 pveceph mgr destroy 的别名。
pveceph destroymon
用于 pveceph mon destroy 的别名。
pveceph destroyosd
用于 pveceph osd destroy 的别名。
pveceph destroypool
用于 pveceph pool destroy 的别名。
pveceph fs create [OPTIONS]
创建一个 Ceph 文件系统
将创建的 CephFS 配置为该集群的存储。
Ceph 文件系统名称。
后备数据池的归置组数量。元数据池将使用其中的四分之一。
pveceph fs destroy <name> [OPTIONS]
销毁一个 Ceph 文件系统
Ceph 文件系统名称。
删除为此文件系统配置的数据和元数据池。
删除为此文件系统配置的所有 pveceph 管理的存储。
pveceph help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pveceph init [OPTIONS]
创建初始的 ceph 默认配置并设置符号链接。
声明一个单独的集群网络,OSD 会在上面进行路由心跳、对象复制和恢复流量。
|
|
需要选项:network |
禁用 cephx 身份验证。
|
|
Cephx 是一种防止中间人攻击的安全功能。仅在您的网络是私有的时候才考虑是否禁用 cephx! |
每个对象允许 I/O 的最小可用副本数
对所有与 ceph 相关的流量使用特定网络
归置组位,用于指定归置组的默认数量。
|
|
osd pool default pg num 不适用于默认池。 |
每个对象的目标副本数
pveceph install [OPTIONS]
安装 ceph 相关的软件包。
允许实验版本。小心使用!
用于测试,不是主存储库。小心使用!
要安装的 Ceph 版本。
pveceph lspools
用于 pveceph pool ls 的别名。
pveceph mds create [OPTIONS]
创建 Ceph 元数据服务器(MDS)
确定 ceph-mds 守护进程是否应该轮询和重放活动 MDS 的日志。更快的 MDS 故障切换,但需要更多的空闲资源。
MDS 的 ID,当省略时与节点名相同。
pveceph mds destroy <name>
销毁 Ceph 元数据服务器
MDS 的名称(ID)
pveceph mgr create [OPTIONS]
创建 Ceph 管理员。
管理员的 ID,当省略时与节点名相同。
pveceph mgr destroy <id>
销毁 Ceph 管理员。
管理员的 ID
pveceph mon create [OPTIONS]
创建 Ceph 监视器和管理员。
覆盖自动检测到的监视器 IP 地址。必须在 Ceph 的公共网络中。
监视器的 ID,当省略时与节点名相同。
pveceph mon destroy <monid>
销毁 Ceph 监视器和管理员。
监视器 ID
pveceph osd create <dev> [OPTIONS]
创建 OSD
块设备名称。
在 crush 中设置 OSD 的设备分类。
block.db 的块设备名称。
block.db 的大小(以 GB 为单位)。
|
|
需要选项:db_dev |
启用 OSD 加密。
block.wall 的块设备名称。
block.wal 的大小(以 GB 为单位)。
|
|
需要选项:wal_dev |
pveceph osd destroy <osdid> [OPTIONS]
销毁 OSD
OSD 的 ID
如果设置,我们删除分区表条目。
pveceph pool create <name> [OPTIONS]
创建 POOL(存储池)
存储池在名称,它必须是唯一的。
使用新存储池来配置 VM 和 CT 的存储。
存储池的应用。
用于在集群中映射对象归置的规则。
每个对象的最小副本数
该存储池的自动 PG 缩放模式。
归置组的数量。
归置组的最小数量。
每个对象的副本数
用于 PG autoscaler 的存储池的预估目标大小。
用于 PG autoscaler 的存储池的预估目标比率。
pveceph pool destroy <name> [OPTIONS]
销毁 pool
存储池在名称,它必须是唯一的。
如果 true ,即使该存储池在使用中也会销毁它。
删除为该存储池配置的所有 pveceph 管理的存储。
pveceph pool get <name> [OPTIONS] [FORMAT_OPTIONS]
列出存储池设置。
存储池在名称,它必须是唯一的。
如果启用,将显示额外的数据(例如统计信息)。
pveceph pool ls [FORMAT_OPTIONS]
列出所有存储池。
pveceph pool set <name> [OPTIONS]
更改 POOL(存储池)设置
存储池在名称,它必须是唯一的。
存储池的应用
用于在集群中映射对象归置的规则。
每个对象的最小副本数
该存储池的自动 PG 缩放模式。
归置组的数量。
归置组的最小数量。
每个对象的副本数
用于 PG autoscaler 的存储池的预估目标大小。
用于 PG autoscaler 的存储池的预估目标比率。
pveceph purge [OPTIONS]
销毁 ceph 相关的数据和配置文件。
附加清除 Ceph 的崩溃日志文件 /var/lib/ceph/crash 。
附加清除 Ceph 日志文件,/var/log/ceph 。
pveceph start [OPTIONS]
启动 ceph 服务。
Ceph 服务名称。
pveceph status
获取 Ceph 状态。
pveceph stop [OPTIONS]
停止 ceph 服务。
Ceph 服务名称。
pvenode <COMMAND> [ARGS] [OPTIONS]
pvenode acme account deactivate [<name>]
停用 CA 的现有 ACME 帐户。
ACME 帐户的配置文件名。
pvenode acme account info [<name>] [FORMAT_OPTIONS]
返回现有的 ACME 帐户信息。
ACME 帐户的配置文件名。
pvenode acme account list
ACME 账户索引。
pvenode acme account register [<name>] {<contact>} [OPTIONS]
向兼容的 CA 注册一个新的 ACME 帐户。
ACME 帐户的配置文件名。
联系电子邮件地址。
ACME CA 目录端点的 URL。
pvenode acme account update [<name>] [OPTIONS]
使用 CA 更新现有 ACME 帐户信息。注意:不指定任何新帐户信息会触发刷新。
ACME 帐户的配置文件名。
联系电子邮件地址。
pvenode acme cert order [OPTIONS]
从兼容 ACME 的 CA 订购新证书。
覆盖现有的自定义证书。
pvenode acme cert renew [OPTIONS]
从 CA 续订现有证书。
即使到期时间超过 30 天,也可以强制续订。
pvenode acme cert revoke
从 CA 吊销现有证书。
pvenode acme plugin add <type> <id> [OPTIONS]
添加 ACME 插件配置。
ACME 质询类型。
ACME 插件 ID 名称
API 插件名称
DNS 插件数据。(Base64 编码)
标志以禁用该配置。
集群节点名称的列表。
在请求验证之前等待的额外延迟(以秒为单位)。允许处理长 TTL 的 DNS 记录。
pvenode acme plugin config <id> [FORMAT_OPTIONS]
获取 ACME 插件配置。
ACME 插件实例的唯一标识符。
pvenode acme plugin list [OPTIONS] [FORMAT_OPTIONS]
ACME 插件的索引。
仅列出指定类型的 ACME 插件
pvenode acme plugin remove <id>
删除 ACME 插件配置。
ACME 插件实例的唯一标识符。
pvenode acme plugin set <id> [OPTIONS]
更新 ACME 插件配置。
ACME 插件 ID 名称
API 插件名称
DNS 插件数据。(Base64 编码)
要删除的设置列表。
当前配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
标志以禁用该配置。
集群节点名称的列表。
在请求验证之前等待的额外延迟(以秒为单位)。允许处理长 TTL 的 DNS 记录。
pvenode cert delete [<restart>]
删除自定义证书链和密钥。
重启 pveproxy 。
pvenode cert info [FORMAT_OPTIONS]
获取节点证书的有关信息。
pvenode cert set <certificates> [<key>] [OPTIONS] [FORMAT_OPTIONS]
上传或更新自定义证书链和密钥。
PEM 编码证书(链)。
PEM 编码的私钥。
覆盖现有的自定义或 ACME 证书文件。
重启 pveproxy 。
pvenode config get [OPTIONS]
获取节点配置选项。
仅返回节点配置中的指定属性。
pvenode config set [OPTIONS]
设置节点配置选项。
指定节点的 ACME 设置。
ACME 域和验证插件。
要删除的设置列表。
节点的描述。显示在 Web 界面节点的备注面板中。这在配置文件中保存为备注。
当前配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
初始延迟(以秒为单位),指在所有启用了开机启动的虚拟来宾启动之前。
用于网络唤醒(wake on LAN)的 MAC 地址
pvenode help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pvenode migrateall <target> [OPTIONS]
迁移所有 VM 和容器。
目标节点。
并行迁移作业的最大数值。如果未设置,则使用 datacenter.cfg 中的 max_workers,两者必须设置其中一个!
仅考虑这些 ID 的来宾。
为本地磁盘启用实时存储迁移。
pvenode startall [OPTIONS]
启动位于该节点上的所有 VM 和容器(默认情况下仅启动那些 onboot=1 的虚拟机和容器)。
即使虚拟来宾未设置 onboot 或设置为 off ,也可以发出启动命令。
仅考虑逗号分隔的 VMID 列表中的来宾。
pvenode stopall [OPTIONS]
停止全部 VM 和容器。
仅考虑这些 ID 的来宾。
pvenode task list [OPTIONS] [FORMAT_OPTIONS]
读取一个节点的任务列表(已完成的任务)。
仅列出状态为 ERROR 的任务。
仅列出此数量的任务。
仅列出此 UNIX 纪元以来的任务。
列出已归档、活动或所有任务。
列出从此偏移量开始的任务。
应该返回的任务状态列表。
仅列出此类型的任务(例如,vzstart、vzdump)。
仅列出此 UNIX 纪元之前的任务。
仅列出此用户的任务。
仅列出此 VM 的任务。
pvenode task log <upid> [OPTIONS]
阅读任务日志。
任务的唯一 ID 。
开始打印的行号。
pvenode task status <upid> [FORMAT_OPTIONS]
阅读任务状态。
任务的唯一 ID 。
pvenode wakeonlan <node>
尝试通过 Wake on LAN 网络数据包唤醒节点。
Wake on LAN 数据包的目标节点
pvesh <COMMAND> [ARGS] [OPTIONS]
pvesh create <api_path> [OPTIONS] [FORMAT_OPTIONS]
在 <api_path> 上调用 API POST 。
API 路径 。
禁用自动代理。
pvesh delete <api_path> [OPTIONS] [FORMAT_OPTIONS]
在 <api_path> 上调用 API DELETE 。
API 路径 。
禁用自动代理。
pvesh get <api_path> [OPTIONS] [FORMAT_OPTIONS]
在 <api_path> 上调用 API GET 。
API 路径 。
禁用自动代理。
pvesh help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pvesh ls <api_path> [OPTIONS] [FORMAT_OPTIONS]
列出 <api_path> 上的子对象。
API 路径 。
禁用自动代理。
pvesh set <api_path> [OPTIONS] [FORMAT_OPTIONS]
在 <api_path> 上调用 API PUT 。
API 路径 。
禁用自动代理。
pvesh usage <api_path> [OPTIONS]
打印 <api_path> 的 API 使用信息。
API 路径。
API 命令。
包括返回数据的模式。
详细的输出格式。
qm <COMMAND> [ARGS] [OPTIONS]
qm agent
用于 qm guest cmd 的别名。
qm cleanup <vmid> <clean-shutdown> <guest-requested>
在 VM 关闭、崩溃等之后调用,用来清理 Tap 设备、vgpus 等资源。
VM 的(唯一) ID 。
指示 qemu 是否完全关闭。
指示关闭是由来宾请求还是通过 qmp 请求的。
qm clone <vmid> <newid> [OPTIONS]
创建虚拟机/模板的副本。
VM 的(唯一) ID 。
克隆(副本)的 VMID 。
覆盖 I/O 带宽限制(以 KB/s 为单位)。
新 VM 的描述。
文件存储的目标格式。仅对完整克隆有效。
创建所有磁盘的完整副本。当您克隆普通 VM 时,总是会这样做。对于 VM 模板,我们默认尝试创建链接克隆。
为新的 VM 设置一个名称。
将新 VM 添加到指定的池中。
快照的名称。
用于完全克隆的目标存储。
目标节点。仅当原始 VM 位于共享存储上时才允许。
qm cloudinit dump <vmid> <type>
获取自动生成的 cloudinit 配置。
VM 的(唯一) ID 。
配置类型。
qm config <vmid> [OPTIONS]
获取应用了挂起配置更改的虚拟机配置。设置 current 参数以获取当前配置。
VM 的(唯一) ID 。
获取当前值(而不是挂起的值)。
从给定的快照中获取配置值。
qm create <vmid> [OPTIONS]
创建或恢复虚拟机。
VM 的(唯一) ID 。
启用/禁用 ACPI 。
启用/禁用与 Qemu 来宾代理(Agent)及其属性的通信。
虚拟处理器架构。默认为主机(host)。
备份存档。.tar 或 .vma 文件的文件系统路径(用于 - 从标准输入(stdin)管道传输数据)或 proxmox 存储备份卷标识符。
传递给 kvm 的任意参数。
配置音频设备,与 QXL/Spice 结合使用。
崩溃后自动重启(目前被忽略)。
VM 的目标内在量(以 MB 为单位)。使用 0 禁用 ballon 驱动程序。
选择 BIOS 实现。
指定来宾引导顺序。使用 order= 子属性,是因为对无按键或 legacy= 的用法是不推荐的。
启用从指定磁盘引导。不推荐:使用 boot: order=foo;bar 代替。
覆盖 I/O 带宽限制(以 KB/s 为单位)。
这是选项 -ide2 的别名
cloud-init:指定自定义文件以替换启动时自动生成的文件。
cloud-init:分配用户的密码。通常不推荐使用它,请改用 ssh 密钥。另请注意,较旧版本的 Cloud-Init 不支持哈希的密码。
指定 cloud-init 配置格式。默认取决于配置的操作系统类型(ostype)。我们对于 Linux 使用 nocloud 格式,对于 Windows 使用 configdrive2 。
cloud-init:更改 ssh 密钥和密码的用户名,而不是映像的配置的默认用户。
每个插槽的核心数。
模拟 CPU 类型。
CPU 使用限制。
VM 的 CPU 权重在 cgroup v2 中将被限制为 [1, 10000]。
VM 备注。显示在 Web 界面中的 VM 的摘要中。这被保存为配置文件中的备注。
配置一个磁盘用于存储 EFI 变量。使用特殊的语法 STORAGE_ID:SIZE_IN_GiB 分配新卷,请注意,此处忽略 SIZE_IN_GiB ,而是将默认 EFI 变量复制到卷中。
允许覆盖现有 VM 。
|
| 需要选项:archive |
启动时冻结 CPU(使用 c monitor 命令开始执行)。
将在 vms(虚拟内存系统) 生命周期的各个步骤中执行的挂钩脚本。
将主机 PCI 设备映射到来宾。
有选择地启用热插拔功能。这是逗号分隔的热插拔功能的列表:network, disk, cpu, memory 和 usb。使用 0 完全禁用热插拔。使用 1 作为值等于是默认的 network,disk,usb 。
启用/禁用大页面内存。
将卷用作 IDE 硬盘或 CD-ROM(n 是 0 到 3)。使用特殊语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。
cloud-init:为相应的接口指定 IP 地址和网关。
IP 地址使用 CIDR 表示法,网关为可选的,但需要指定相同类型的 IP 。
特殊字符串 dhcp 可用于使用 DHCP 获取 IP 地址,在这种情况下不提供显式网关。对于 IPv6 ,特殊字符串 auto 可用于无状态自动配置。这需要 cloud-init 19.4 或更高版本。
如果启用了 cloud-init 且同时未指定 IPv4 和 IPv6 地址,它默认在 IPv4 上使用 dhcp 。
虚拟机间(Inter-VM)共享内存。用于 VM 之间或与主机的直接通信。
与 hugepages 一起使用。如果启用,VM 关机后大页面将不会被删除,可用于后续启动。
用于 VNC 服务器的键盘布局。默认值是从配置文件 '/etc/pve/datacenter.cfg' 读取。它不是必要设置。
启用/禁用 KVM 硬件虚拟化。
立即从备份启动虚拟机并在后台恢复。仅限 PBS。
|
|
需要选项:archive |
将实时时钟 (RTC) 设置为本地时间。如果 ostype 指示 Microsoft Windows 操作系统,则默认启用此功能。
锁定/解锁 VM 。
指定 Qemu 机器类型。
VM 的内存量(以 MB 为单位)。这是您使用 balloon 设备时的最大可用内存。
设置迁移的最大允许停机时间(以秒为单位)。
设置迁移的最大速度(以 MB/s 为单位)。值为 0 表示没有限制。
设置 VM 的名称。仅在 Web 界面上的配置中使用。
cloud-init:为容器设置 DNS 搜索域。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
指定网络设备。
启用/禁用 NUMA 。
NUMA 拓扑。
指定是否在系统启动期间启动 VM 。
指定来宾操作系统。
映射主机并行设备(n 是 0 到 2)。
将 VM 添加到指定的池。
设置 VM 的保护标志。这将禁用移除 VM 和移除磁盘操作。
允许重启。如果设置为 0,VM 会在重启时退出。
配置基于 VirtIO 的随机数生成器(VirtIO RNG)。
将卷用作 SATA 硬盘或 CD-ROM(n 为 0 到 5)。使用特殊语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。
将卷用作 SCSI 硬盘或 CD-ROM(n 为 0 到 30)。使用特殊语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。
SCSI 控制器型号
cloud-init:为容器设置 DNS 搜索域。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
在 VM 内部创建一个串口设备(n 是 0 到 3)
用于 Auto-ballooning(自动增长)的内存共享量。数字越大,VM 获得的内存越多。数字与所有其他正在运行 VM 的权重有关。使用 0 禁用 Auto-ballooning(自动增长),Auto-ballooning(自动增长)通过 pvestatd 完成的。
指定 SMBIOS 类型 1 字段。
CPU 数量。请改用 -sockets 选项。
CPU 插槽的数量。
为 SPICE 配置其他增强功能。
cloud-init:设置公共 SSH 密钥(每行一个密钥,OpenSSH 格式)。
创建成功以后启动 VM 。
设置实时时钟的初始日期。日期的有效格式是:'now' 或 2006-06-17T16:01:21 或 2006-06-17 。
启动和关机行为。Order 是一个定义常规启动顺序的正整数。关机执行相反的顺序。此外,您可以以秒为单位设置 up(增加)或 down(减少)的延迟,它指定在启动或停止下一个 VM 之前的延迟等待。
默认存储。
启用/禁用 USB 平板设备。
VM 的标签。这只是元信息。
启用/禁用时间漂移修复。
启用/禁用模板。
配置一个用于存储 TPM 状态的磁盘。使用特定语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。请注意,此处忽略 SIZE_IN_GiB,并且将始终使用默认大小 4 MB。格式也固定为 raw 。
分配一个唯一的随机以太网地址。
|
|
需要选项:archive |
引用未使用的卷。这是内部使用的,不应手动修改。
配置一个 USB 设备(n 是 0 到 4)。
热插拔 vcpus 的数量。
配置 VGA 硬件。
使用卷作为 VIRTIO 硬盘(n 为 0 到 15)。使用特殊语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。
设置 VM Generation ID 。使用 1 在创建或更新时自动生成,传递 0 以显式禁用。
VM 状态卷/文件的默认存储。
创建一个虚拟硬件监控设备(watchdog)。
qm delsnapshot <vmid> <snapname> [OPTIONS]
删除一个 VM 快照。
VM 的(唯一)ID 。
快照名称
从配置文件中删除,即使删除磁盘快照失败。
qm destroy <vmid> [OPTIONS]
销毁 VM 和所有使用/拥有的卷。删除任何 VM 特定权限和防火墙规则。
VM 的(唯一)ID 。
如果设置,则额外销毁所有在配置中未引用的但与所有已启用存储中匹配 VMID 的磁盘。
从配置中删除 VMID,例如备份和复制作业以及 HA 。
忽略锁定 - 只允许 root 使用此选项。
qm guest cmd <vmid> <command>
执行 Qemu 来宾代理(Agent)命令。
VM 的(唯一)ID 。
QGA 命令。
qm guest exec <vmid> [<extra-args>] [OPTIONS]
通过来宾代理执行给定的命令
VM 的(唯一)ID 。
额外的参数作为数组
设置后,读取 STDIN 直到 EOF 并通过 input-data 转发给来宾代理(通常被视为 STDIN 来由来宾代理启动的进程)。允许最大 1 MiB。
如果设置为 off,则立即返回 pid,而不是等待命令完成或超时。
同步等待命令完成的最长时间。如果达到,则返回 pID 。设置为 0 以停用。
qm guest exec-status <vmid> <pid>
获取由来宾代理启动的给定 pid 的状态
VM 的(唯一)ID 。
要查询的 PID
qm guest passwd <vmid> <username> [OPTIONS]
将给定用户的密码设置为给定密码
VM 的(唯一)ID 。
要为其设置密码的用户。
设置为 1 ,则密码通过 crypt() 进行加密。
qm help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
qm importdisk <vmid> <source> <storage> [OPTIONS]
将外部磁盘映像导入为 VM 中未使用的磁盘。qemu-img(1) 必须支持的映像格式。
VM 的(唯一)ID 。
要导入的磁盘映像的路径
目标存储 ID
目标格式
qm importovf <vmid> <manifest> <storage> [OPTIONS]
使用从 OVF 的清单文件(manifest文件)中读取的参数创建新 VM
VM 的(唯一)ID 。
OVF 文件的路径
目标存储 ID
打印提取的 OVF 参数的解析描述,但不创建 VM
目标格式
qm list [OPTIONS]
虚拟机索引(每个节点)。
确定活动 VM 的完整状态。
qm listsnapshot <vmid>
列出所有快照。
VM 的(唯一)ID 。
qm migrate <vmid> <target> [OPTIONS]
迁移虚拟机。创建一个新的迁移任务。
VM 的(唯一)ID 。
目标节点。
覆盖 I/O 带宽限制(以 KB/s 为单位)。
允许迁移使用本地设备的 VM 。仅 root 可以使用该选项。
用于迁移的(子)网络的 CIDR。
默认情况下,迁移的流量使用 SSH 隧道加密。可以在安全、完全私有的网络上禁用此功能以提高性能。
如果 VM 正在运行,请使用在线/实时迁移。如果 VM 已停止,则忽略。
从源存储映射到目标存储。仅提供一个存储 ID 会将所有源存储映射到该存储。提供特殊值 1 会将每个源存储映射到自身。
为本地磁盘启用实时存储迁移
qm monitor <vmid>
进入Qemu 监视器界面。
VM 的(唯一)ID 。
qm move-disk <vmid> <disk> [<storage>] [OPTIONS]
将卷移动到不同的存储或不同的 VM 。
VM 的(唯一)ID 。
您要移动的磁盘。
目标存储。
覆盖 I/O 带宽限制(以 KB/s 为单位)。
复制成功后删除原盘。默认情况下,将原磁盘保留为未使用的磁盘。
当前配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
目标格式。
当前目标 VM 的配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
磁盘将移动到目标 VM 上的配置密钥(例如,ide0 或 scsi1)。默认为源磁盘密钥。
VM 的(唯一)ID 。
qm move_disk
用于 qm move-disk 的别名。
qm mtunnel
由 qmigrate 使用 - 不要手动使用。
qm nbdstop <vmid>
停止嵌入式 nbd 服务器。
VM 的(唯一)ID 。
qm pending <vmid>
获取具有当前值和待定值的虚拟机配置。
VM 的(唯一)ID 。
qm reboot <vmid> [OPTIONS]
通过关闭 VM 来重启它,然后再次重启它来应用挂起的更改
VM 的(唯一)ID 。
等待关机的最大超时秒数。
qm rescan [OPTIONS]
重新扫描所有存储并更新磁盘大小和未使用的磁盘映像。
不要实际将更改写入 VM 的配置。
VM 的(唯一)ID 。
qm reset <vmid> [OPTIONS]
重置虚拟机。
VM 的(唯一)ID 。
忽略锁定 - 只允许 root 使用此选项。
qm resize <vmid> <disk> <size> [OPTIONS]
扩展卷的大小。
VM 的(唯一)ID 。
要调整大小的磁盘。
新的大小。带有 + 号的值被添加到卷的实际大小,没有它,该值被视为绝对值。不支持缩小磁盘大小。
当前配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
忽略锁定 - 只允许 root 使用此选项。
qm resume <vmid> [OPTIONS]
恢复虚拟机。
VM 的(唯一)ID 。
没有可用的描述
忽略锁定 - 只允许 root 使用此选项。
qm rollback <vmid> <snapname>
将 VM 的状态回滚到指定的快照。
VM 的(唯一)ID 。
快照的名称。
qm sendkey <vmid> <key> [OPTIONS]
向虚拟机发送按键事件。
VM 的(唯一)ID 。
按键(qemu 监视器编码)。
忽略锁定 - 只允许 root 使用此选项。
qm set <vmid> [OPTIONS]
设置虚拟机选项(同步 API) - 对于任何涉及热插拔或存储分配的操作,您应该考虑使用 POST 方法。
VM 的(唯一)ID 。
启用/禁用 ACPI 。
启用/禁用与 Qemu 来宾代理(Agent)及其属性的通信。
虚拟处理器架构。默认为主机(host)。
传递给 kvm 的任意参数。
配置音频设备,与 QXL/Spice 结合使用。
崩溃后自动重启(目前被忽略)。
VM 的目标内在量(以 MB 为单位)。使用 0 禁用 ballon 驱动程序。
选择 BIOS 实现。
指定来宾引导顺序。使用 order= 子属性,是因为对无按键或 legacy= 的用法是不推荐的。
启用从指定磁盘引导。不推荐:使用 boot: order=foo;bar 代替。
这是选项 -ide2 的别名
cloud-init:指定自定义文件以替换启动时自动生成的文件。
cloud-init:分配用户的密码。通常不推荐使用它,请改用 ssh 密钥。另请注意,较旧版本的 Cloud-Init 不支持哈希的密码。
指定 cloud-init 配置格式。默认取决于配置的操作系统类型(ostype)。我们对于 Linux 使用 nocloud 格式,对于 Windows 使用 configdrive2 。
cloud-init:更改 ssh 密钥和密码的用户名,而不是映像的配置的默认用户。
每个插槽的核心数。
模拟 CPU 类型。
CPU 使用限制。
VM 的 CPU 权重在 cgroup v2 中将被限制为 [1, 10000]。
要删除的设置列表。
VM 备注。显示在 Web 界面中的 VM 的摘要中。这被保存为配置文件中的备注。
当前配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
配置一个磁盘用于存储 EFI 变量。使用特殊的语法 STORAGE_ID:SIZE_IN_GiB 分配新卷,请注意,此处忽略 SIZE_IN_GiB ,而是将默认 EFI 变量复制到卷中。
强制物理移除。如果没有这个,我们只需从配置文件中删除磁盘并创建一个名为 unused[n] 的附加配置条目,其中包含卷 ID 。取消 unused[n] 的链接总是会导致物理删除。
|
|
需要选项:delete |
启动时冻结 CPU(使用 c monitor 命令开始执行)。
将在 vms(虚拟内存系统) 生命周期的各个步骤中执行的挂钩脚本。
将主机 PCI 设备映射到来宾。
有选择地启用热插拔功能。这是逗号分隔的热插拔功能的列表:network, disk, cpu, memory 和 usb。使用 0 完全禁用热插拔。使用 1 作为值等于是默认的 network,disk,usb 。
启用/禁用大页面内存。
将卷用作 IDE 硬盘或 CD-ROM(n 是 0 到 3)。使用特殊语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。
cloud-init:为相应的接口指定 IP 地址和网关。
IP 地址使用 CIDR 表示法,网关为可选的,但需要指定相同类型的 IP 。
特殊字符串 dhcp 可用于使用 DHCP 获取 IP 地址,在这种情况下不提供显式网关。对于 IPv6 ,特殊字符串 auto 可用于无状态自动配置。这需要 cloud-init 19.4 或更高版本。
如果启用了 cloud-init 且同时未指定 IPv4 和 IPv6 地址,它默认在 IPv4 上使用 dhcp 。
虚拟机间(Inter-VM)共享内存。用于 VM 之间或与主机的直接通信。
与 hugepages 一起使用。如果启用,VM 关机后大页面将不会被删除,可用于后续启动。
用于 VNC 服务器的键盘布局。默认值是从配置文件 '/etc/pve/datacenter.cfg' 读取。它不是必要设置。
启用/禁用 KVM 硬件虚拟化。
将实时时钟 (RTC) 设置为本地时间。如果 ostype 指示 Microsoft Windows 操作系统,则默认启用此功能。
锁定/解锁 VM 。
指定 Qemu 机器类型。
VM 的内存量(以 MB 为单位)。这是您使用 balloon 设备时的最大可用内存。
设置迁移的最大允许停机时间(以秒为单位)。
设置迁移的最大速度(以 MB/s 为单位)。值为 0 表示没有限制。
设置 VM 的名称。仅在 Web 界面上的配置中使用。
cloud-init:为容器设置 DNS 服务器 IP 地址。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
指定网络设备。
启用/禁用 NUMA 。
NUMA 拓扑。
指定是否在系统启动期间启动 VM 。
指定来宾操作系统。
映射主机并行设备(n 是 0 到 2)。
设置 VM 的保护标志。这将禁用移除 VM 和移除磁盘操作。
允许重启。如果设置为 0,VM 会在重启时退出。
还原挂起的更改。
配置基于 VirtIO 的随机数生成器(VirtIO RNG)。
将卷用作 SATA 硬盘或 CD-ROM(n 为 0 到 5)。使用特殊语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。
将卷用作 SCSI 硬盘或 CD-ROM(n 为 0 到 30)。使用特殊语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。
SCSI 控制器型号
cloud-init:为容器设置 DNS 服务器 IP 地址。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
在 VM 内部创建一个串口设备(n 是 0 到 3)
用于 Auto-ballooning(自动增长)的内存共享量。数字越大,VM 获得的内存越多。数字与所有其他正在运行 VM 的权重有关。使用 0 禁用 Auto-ballooning(自动增长),Auto-ballooning(自动增长)通过 pvestatd 完成的。
忽略锁定 - 只允许 root 使用此选项。
指定 SMBIOS 类型 1 字段。
CPU 数量。请改用 -sockets 选项。
CPU 插槽的数量。
为 SPICE 配置其他增强功能。
cloud-init:设置公共 SSH 密钥(每行一个密钥,OpenSSH 格式)。
设置实时时钟的初始日期。日期的有效格式是:'now' 或 2006-06-17T16:01:21 或 2006-06-17 。
启动和关机行为。Order 是一个定义常规启动顺序的正整数。关机执行相反的顺序。此外,您可以以秒为单位设置 up(增加)或 down(减少)的延迟,它指定在启动或停止下一个 VM 之前的延迟等待。
启用/禁用 USB 平板设备。
VM 的标签。这只是元信息。
启用/禁用时间漂移修复。
启用/禁用模板。
配置一个用于存储 TPM 状态的磁盘。使用特定语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。请注意,此处忽略 SIZE_IN_GiB,并且将始终使用默认大小 4 MB。格式也固定为 raw 。
引用未使用的卷。这是内部使用的,不应手动修改。
配置一个 USB 设备(n 是 0 到 4)。
热插拔 vcpus 的数量。
配置 VGA 硬件。
使用卷作为 VIRTIO 硬盘(n 为 0 到 15)。使用特殊语法 STORAGE_ID:SIZE_IN_GiB 分配新卷。
设置 VM Generation ID 。使用 1 在创建或更新时自动生成,传递 0 以显式禁用。
VM 状态卷/文件的默认存储。
创建一个虚拟硬件监控设备(watchdog)。
qm showcmd <vmid> [OPTIONS]
显示用于启动 VM 的命令行(调试信息)。
VM 的(唯一)ID 。
将每个选项放在一个新行上,用来增强人类可读性。
从给定的快照中获取配置值。
qm shutdown <vmid> [OPTIONS]
关闭虚拟机。这类似于按下物理机上的电源按钮。这将为来宾操作系统发送 ACPI 事件,然后应该继续彻底地关闭。
VM 的(唯一)ID 。
确保 VM 停止。
不要停用存储卷。
忽略锁定 - 只允许 root 使用此选项。
等待最大超时秒数。
qm snapshot <vmid> <snapname> [OPTIONS]
生成 VM 快照。
VM 的(唯一)ID 。
快照的名称。
文字描述或备注。
保存 vmstate( VM 状态卷/文件)
qm start <vmid> [OPTIONS]
启动虚拟机。
VM 的(唯一)ID 。
用给定的字符串覆盖 QEMU 的 -cpu 参数。
指定 Qemu 机器类型。
集群节点的名称。
用于迁移的(子)网络的 CIDR。
默认情况下,迁移的流量使用 SSH 隧道加密。可以在安全、完全私有的网络上禁用此功能以提高性能。
忽略锁定 - 只允许 root 使用此选项。
某些命令从此位置保存/恢复状态。
从源存储映射到目标存储。仅提供一个存储 ID 会将所有源存储映射到该存储。提供特殊值 1 会将每个源存储映射到自身。
等待最大超时秒数。
qm status <vmid> [OPTIONS]
显示 VM 状态。
VM 的(唯一)ID 。
详细的输出格式
qm stop <vmid> [OPTIONS]
停止虚拟机。qemu 进程将立即退出。这类似于拔掉正在运行的计算机的电源插头,可能会损坏 VM 数据。
VM 的(唯一)ID 。
不要停用存储卷。
集群节点的名称。
忽略锁定 - 只允许 root 使用此选项。
等待最大超时秒数。
qm suspend <vmid> [OPTIONS]
挂起虚拟机。
VM 的(唯一)ID 。
忽略锁定 - 只允许 root 使用此选项。
VM 状态的存储
|
|
需要选项:todisk |
如果设置,则将 VM 挂起到磁盘。将在下次 VM 启动时恢复。
qm template <vmid> [OPTIONS]
创建一个模板。
VM 的(唯一)ID 。
如果您只想将 1 个磁盘转换为基本映像。
qm terminal <vmid> [OPTIONS]
使用串口设备打开终端( VM 需要配置串口设备,例如 serial0: socket 。)
VM 的(唯一)ID 。
转义字符。
选择串行设备。默认情况下,我们只使用第一个合适的设备。
qm unlink <vmid> --idlist <string> [OPTIONS]
取消链接/删除磁盘映像。
VM 的(唯一)ID 。
强制物理移除。如果没有这个,我们只需从配置文件中删除磁盘并创建一个名为 unused[n] 的附加配置条目,其中包含卷 ID 。取消 unused[n] 的链接总是会导致物理删除。
要删除的磁盘 ID 列表。
qm unlock <vmid>
解锁 VM 。
VM 的(唯一)ID 。
qm vncproxy <vmid>
代理 VM 的 VNC 流量到标准输入/标准输出(stdin/stdout)
VM 的(唯一)ID 。
qm wait <vmid> [OPTIONS]
等到 VM 停止。
VM 的(唯一)ID 。
超时(以秒为单位)。默认是永远等待。
qmrestore help
qmrestore <archive> <vmid> [OPTIONS]
恢复 QemuServer vzdump 备份。
备份文件。您可以通过 - 从标准输入中读取。
VM 的(唯一)ID 。
覆盖 I/O 带宽限制(以 KB/s 为单位)。
允许覆盖现有 VM。
立即从备份启动虚拟机并在后台恢复。仅限 PBS。
将 VM 添加到指定的池。
默认存储。
分配一个唯一的随机以太网地址。
pct <COMMAND> [ARGS] [OPTIONS]
pct clone <vmid> <newid> [OPTIONS]
创建一个容器的克隆/副本
VM 的(唯一)ID 。
克隆(副本)的 VMID 。
覆盖 I/O 带宽限制(以 KB/s 为单位)。
新的 CT 的说明。
创建所有磁盘的完整副本。当您克隆正常 CT 时,总是会这样做。对于 CT 模板,我们默认尝试创建链接克隆。
为新的 CT 设置主机名。
将新的 CT 添加到指定的池中。
快照的名称。
用于完全克隆的目标存储。
目标节点。仅当原始 VM 位于共享存储上时才允许。
pct config <vmid> [OPTIONS]
获取容器配置。
VM 的(唯一)ID 。
获取当前值(而不是挂起的值)。
从给定的快照中获取配置值。
pct console <vmid> [OPTIONS]
启动指定容器的控制台。
VM 的(唯一)ID 。
转义序列前缀。例如,使用 <Ctrl+b q> 作为转义序列传递 ^b 。
pct cpusets
打印分配的 CPU 集合的列表。
pct create <vmid> <ostemplate> [OPTIONS]
创建或恢复容器。
VM 的(唯一)ID 。
操作系统模板或备份文件。
操作系统架构类型。
覆盖 I/O 带宽限制(以 KB/s 为单位)。
控制台模式。默认情况下,控制台命令尝试打开一个与可用 tty 设备的连接。通过将 cmode 设置为 console ,它会尝试附加到 /dev/console 。如果将 cmode 设置为 shell ,它只会调用容器内的 shell(无需登录)。
将控制台设备(/dev/console)附加到容器。
分配给容器的核心数。默认情况下,容器可以使用所有可用的核心。
CPU 使用限制。
|
|
如果计算机有 2 个 CPU,那么它总共有 2 个 CPU 时间。值 0 表示没有 CPU 限制。 |
VM 的 CPU 权重。参数是用于内核公平调试程序,这个数字越大,这个 VM 获得的 CPU 时间越多。该数字与所有其它正在运行的 VM 的权重相关。
|
|
您可以通过将此设置为 0 来禁用公平调度程序配置。 |
尝试获得更详细的调试日志。目前这仅在启动时启用调试日志级别。
容器的描述。显示在 Web 界面的 CT 的摘要中。这在配置文件中保存为备注。
允许容器访问高级功能。
允许覆盖现有容器。
将在容器生命周期的各个步骤中执行的挂钩脚本。
设置容器的主机名。
提取模板时忽略错误。
锁定/解锁 VM 。
VM 的内存量(以 MB 为单位)。
使用卷作为容器挂载点,要对分配的新卷使用特殊的语法 STORAGE_ID:SIZE_IN_GiB 。
为容器设置 DNS 服务器 IP 地址。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
指定容器的网络接口。
指定是否在系统启动期间启动 VM 。
操作系统类型。这是用于设置容器内的配置,对应 /usr/share/lxc/config/<ostype>.common.conf 中的 lxc 设置脚本。值 unmanaged 可用于跳过特定的操作系统设置。
设置容器内 root 密码。
将 VM 添加到指定的池。
设置容器的保护标志。这将阻止 CT 或 CT 的磁盘删除/更新操作。
将此标记为恢复任务。
使用卷作为容器根(root)。
为容器设置 DNS 服务器 IP 地址。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
设置公共 SSH 密钥(每行一个密钥,OpenSSH 格式)。
创建成功后启动 CT 。
启动和关机行为。Order 是一个定义常规启动顺序的正整数。关机执行相反的顺序。此外,您可以以秒为单位设置 up(增加)或 down(减少)的延迟,它指定在启动或停止下一个 VM 之前的延迟等待。
默认存储。
VM 的交换分区(SWAP)容量(以 MB 为单位)。
容器的标签。这只是元信息。
启用/禁用模板。
要在容器中使用的时区。如果没有设置选项,则不会执行任何操作。可以设置为 host(主机)以匹配主机时区,或来自 /usr/share/zoneinfo/zone.tab 的任意时区选项。
指定容器可用的 tty 数量
分配一个唯一的随机以太网地址。
|
|
需要选项:restore |
以非特权用户身份运行容器。(不应手动修改。)
引用未使用的卷。这是内部使用的,不应手动修改。
pct delsnapshot <vmid> <snapname> [OPTIONS]
删除 LXC 快照。
VM 的(唯一)ID 。
快照的名称。
从配置文件中删除,即使删除磁盘快照失败。
pct destroy <vmid> [OPTIONS]
销毁容器(同时删除所有使用文件)。
VM 的(唯一)ID 。
如果设置,则额外销毁所有在配置中未引用的但与所有已启用存储中匹配 VMID 的磁盘。
强制销毁,即使虚拟机或容器正在运行。
从所有相关配置中删除容器。例如,备份作业、复制作业或 HA。将 始终 删除相关的 ACL 和防火墙条目。
pct df <vmid>
获取容器的当前磁盘使用情况。
VM 的(唯一)ID 。
pct enter <vmid>
启动指定容器的 shell 。
VM 的(唯一)ID 。
pct exec <vmid> [<extra-args>]
在指定的容器内启动命令。
VM 的(唯一)ID 。
额外的参数作为数组
pct fsck <vmid> [OPTIONS]
在容器卷上运行文件系统检查 (fsck)。
VM 的(唯一)ID 。
运行文件系统检查的卷
强制检查,即使文件系统看起来很干净。
pct fstrim <vmid> [OPTIONS]
在选定的 CT 及其挂载点上运行 fstrim。
VM 的(唯一)ID 。
跳过所有挂载点,仅在容器根目录上执行 fstrim 。
pct help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pct list
LXC 容器索引(每个节点)。
pct listsnapshot <vmid>
列出所有快照。
VM 的(唯一)ID 。
pct migrate <vmid> <target> [OPTIONS]
将容器迁移到另一个节点。创建一个新的迁移任务。
VM 的(唯一)ID 。
目标节点。
覆盖 I/O 带宽限制(以 KB/s 为单位)。
使用在线/实时迁移。
使用重启迁移
用于重启迁移的关机超时(以秒为单位)
pct mount <vmid>
在主机上挂载容器的文件系统。这将锁定容器,仅用于紧急维护,因为它将阻止容器上的进一步操作,而不是启动和停止。
VM 的(唯一)ID 。
pct move-volume <vmid> <volume> [<storage>] [<target-vmid>] [<target-volume>] [OPTIONS]
将 rootfs-/mp-volume 移动到不同的存储或不同的容器。
VM 的(唯一)ID 。
将被移动的卷。
目标存储。
VM 的(唯一)ID 。
卷将移动到的配置密钥。默认为源磁盘密钥。
覆盖 I/O 带宽限制(以 KB/s 为单位)。
复制成功后删除原卷。默认情况下,将原文件保留为未使用的卷条目。
当前配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
当前目标容器的配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
pct move_volume
用于 pct move-volume 的别名。
pct pending <vmid>
获取容器的配置,包括挂起的更改。
VM 的(唯一)ID 。
pct pull <vmid> <path> <destination> [OPTIONS]
将文件从容器复制到本地系统。
VM 的(唯一)ID 。
要拉取的容器内文件的路径。
目标
所有者组名称或 ID 。
要使用的文件权限(默认为八进制,前缀为 0x 用于十六进制)。
所有者用户名称或 ID 。
pct push <vmid> <file> <destination> [OPTIONS]
将本地文件复制到容器中。
VM 的(唯一)ID 。
本地文件的路径。
容器内要写入的目标。
所有者组名称或 ID 。要使用的名称必须存在于容器中。
要使用的文件权限(默认为八进制,前缀为 0x 用于十六进制)。
所有者用户名称或 ID 。要使用的名称必须存在于容器中。
pct reboot <vmid> [OPTIONS]
通过关闭容器来重启容器,然后再次重启它来应用挂起的更改。
VM 的(唯一)ID 。
等待关机的最大超时秒数。
pct rescan [OPTIONS]
重新扫描所有存储并更新磁盘大小和未使用的磁盘映像。
不要实际将更改写入配置。
VM 的(唯一)ID 。
pct resize <vmid> <disk> <size> [OPTIONS]
调整容器挂载点的大小。
VM 的(唯一)ID 。
要调整大小的磁盘。
新的大小。带有 + 号的值被添加到卷的实际大小,没有它,该值被视为绝对值。不支持缩小磁盘大小。
当前配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
pct restore <vmid> <ostemplate> [OPTIONS]
创建或恢复容器。
VM 的(唯一)ID 。
操作系统模板或备份文件。
操作系统架构类型。
覆盖 I/O 带宽限制(以 KB/s 为单位)。
控制台模式。默认情况下,控制台命令尝试打开一个与可用 tty 设备的连接。通过将 cmode 设置为 console ,它会尝试附加到 /dev/console 。如果将 cmode 设置为 shell ,它只会调用容器内的 shell(无需登录)。
将控制台设备(/dev/console)附加到容器。
分配给容器的核心数。默认情况下,容器可以使用所有可用的核心。
CPU 使用限制。
|
|
如果计算机有 2 个 CPU,那么它总共有 2 个 CPU 时间。值 0 表示没有 CPU 限制。 |
VM 的 CPU 权重。参数是用于内核公平调试程序,这个数字越大,这个 VM 获得的 CPU 时间越多。该数字与所有其它正在运行的 VM 的权重相关。
|
|
您可以通过将此设置为 0 来禁用公平调度程序配置。 |
尝试获得更详细的调试日志。目前这仅在启动时启用调试日志级别。
容器的描述。显示在 Web 界面的 CT 的摘要中。这在配置文件中保存为备注。
允许容器访问高级功能。
允许覆盖现有容器。
将在容器生命周期的各个步骤中执行的挂钩脚本。
设置容器的主机名。
提取模板时忽略错误。
锁定/解锁 VM 。
VM 的内存量(以 MB 为单位)。
使用卷作为容器挂载点,要对分配的新卷使用特殊的语法 STORAGE_ID:SIZE_IN_GiB 。
为容器设置 DNS 服务器 IP 地址。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
指定容器的网络接口。
指定是否在系统启动期间启动 VM 。
操作系统类型。这是用于设置容器内的配置,对应 /usr/share/lxc/config/<ostype>.common.conf 中的 lxc 设置脚本。值 unmanaged 可用于跳过特定的操作系统设置。
设置容器内 root 密码。
将 VM 添加到指定的池。
设置容器的保护标志。这将阻止 CT 或 CT 的磁盘删除/更新操作。
使用卷作为容器根(root)。
为容器设置 DNS 服务器 IP 地址。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
设置公共 SSH 密钥(每行一个密钥,OpenSSH 格式)。
创建成功后启动 CT 。
启动和关机行为。Order 是一个定义常规启动顺序的正整数。关机执行相反的顺序。此外,您可以以秒为单位设置 up(增加)或 down(减少)的延迟,它指定在启动或停止下一个 VM 之前的延迟等待。
默认存储。
VM 的交换分区(SWAP)容量(以 MB 为单位)。
容器的标签。这只是元信息。
启用/禁用模板。
要在容器中使用的时区。如果没有设置选项,则不会执行任何操作。可以设置为 host(主机)以匹配主机时区,或来自 /usr/share/zoneinfo/zone.tab 的任意时区选项。
指定容器可用的 tty 数量
分配一个唯一的随机以太网地址。
|
|
需要选项:restore |
以非特权用户身份运行容器。(不应手动修改。)
引用未使用的卷。这是内部使用的,不应手动修改。
pct resume <vmid>
恢复容器。
VM 的(唯一)ID 。
pct rollback <vmid> <snapname>
将 LXC 状态回滚到指定的快照。
VM 的(唯一)ID 。
快照的名称。
pct set <vmid> [OPTIONS]
设置容器选项。
VM 的(唯一)ID 。
操作系统架构类型。
控制台模式。默认情况下,控制台命令尝试打开一个与可用 tty 设备的连接。通过将 cmode 设置为 console ,它会尝试附加到 /dev/console 。如果将 cmode 设置为 shell ,它只会调用容器内的 shell(无需登录)。
将控制台设备(/dev/console)附加到容器。
分配给容器的核心数。默认情况下,容器可以使用所有可用的核心。
CPU 使用限制。
|
|
如果计算机有 2 个 CPU,那么它总共有 2 个 CPU 时间。值 0 表示没有 CPU 限制。 |
VM 的 CPU 权重。参数是用于内核公平调试程序,这个数字越大,这个 VM 获得的 CPU 时间越多。该数字与所有其它正在运行的 VM 的权重相关。
|
|
您可以通过将此设置为 0 来禁用公平调度程序配置。 |
尝试获得更详细的调试日志。目前这仅在启动时启用调试日志级别。
要删除的设置列表。
容器的描述。显示在 Web 界面的 CT 的摘要中。这在配置文件中保存为备注。
当前配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
允许容器访问高级功能。
将在容器生命周期的各个步骤中执行的挂钩脚本。
设置容器的主机名。
锁定/解锁 VM 。
VM 的内存量(以 MB 为单位)。
使用卷作为容器挂载点,要对分配的新卷使用特殊的语法 STORAGE_ID:SIZE_IN_GiB 。
为容器设置 DNS 服务器 IP 地址。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
指定容器的网络接口。
指定是否在系统启动期间启动 VM 。
操作系统类型。这是用于设置容器内的配置,对应 /usr/share/lxc/config/<ostype>.common.conf 中的 lxc 设置脚本。值 unmanaged 可用于跳过特定的操作系统设置。
设置容器的保护标志。这将阻止 CT 或 CT 的磁盘删除/更新操作。
还原挂起的更改。
使用卷作为容器根(root)。
为容器设置 DNS 服务器 IP 地址。如果未设置搜索域也未设置域名服务器,则自动使用主机的设置生成。
启动和关机行为。Order 是一个定义常规启动顺序的正整数。关机执行相反的顺序。此外,您可以以秒为单位设置 up(增加)或 down(减少)的延迟,它指定在启动或停止下一个 VM 之前的延迟等待。
VM 的交换分区(SWAP)容量(以 MB 为单位)。
容器的标签。这只是元信息。
启用/禁用模板。
要在容器中使用的时区。如果没有设置选项,则不会执行任何操作。可以设置为 host(主机)以匹配主机时区,或来自 /usr/share/zoneinfo/zone.tab 的任意时区选项。
指定容器可用的 tty 数量
以非特权用户身份运行容器。(不应手动修改。)
引用未使用的卷。这是内部使用的,不应手动修改。
pct shutdown <vmid> [OPTIONS]
关闭容器。这将触发容器的完全关闭,有关详细信息,请参阅 lxc-stop(1)。
VM 的(唯一)ID 。
确保容器停止。
等待最大超时秒数。
pct snapshot <vmid> <snapname> [OPTIONS]
给容器生成快照。
VM 的(唯一)ID 。
快照的名称。
文字描述或备注。
pct start <vmid> [OPTIONS]
启动容器。
VM 的(唯一)ID 。
如果设置,则在启动时启用非常详细的调试日志级别。
忽略锁定 - 只允许 root 使用此选项。
pct status <vmid> [OPTIONS]
显示 CT 状态。
VM 的(唯一)ID 。
详细的输出格式
pct stop <vmid> [OPTIONS]
停止容器。这将突然停止容器中运行的所有进程。
VM 的(唯一)ID 。
忽略锁定 - 只允许 root 使用此选项。
pct suspend <vmid>
挂起容器。这是实验性的。
VM 的(唯一)ID 。
pct template <vmid>
创建模板。
VM 的(唯一)ID 。
pct unlock <vmid>
解锁 VM 。
VM 的(唯一)ID 。
pct unmount <vmid>
卸载容器的文件系统。
VM 的(唯一)ID 。
pveam <COMMAND> [ARGS] [OPTIONS]
pveam available [OPTIONS]
列出可用的模板。
将列表限制为指定部分。
pveam download <storage> <template>
下载设备模板。
用于存储模板的存储空间
将下载的模板
pveam help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pveam list <storage>
获取存储中所有模板的列表
仅列出指定存储上的模板
pveam remove <template_path>
删除模板。
要删除的模板。
pveam update
更新容器模板的数据库。
pvecm <COMMAND> [ARGS] [OPTIONS]
pvecm add <hostname> [OPTIONS]
将当前节点添加到现有集群。
现有集群成员的主机名(或 IP)。
证书的 SHA 256 指纹。
如果节点已经存在,不要抛出错误。
单个 corosync 链路的地址和优先级信息。(最多支持 8 个链接;link0..link7)
此节点的节点 ID 。
始终使用 SSH 加入,即使 peer 可能通过 API 加入。
该节点的投票数
pvecm addnode <node> [OPTIONS]
将节点添加到集群配置。此调用仅供内部使用。
集群节点的名称。
新节点的 JOIN_API_VERSION。
如果节点已经存在,不要抛出错误。
单个 corosync 链路的地址和优先级信息。(最多支持 8 个链接;link0..link7)
要添加的节点的 IP 地址。如果没有给出链接,则用作后备。
此节点的节点 ID 。
该节点的投票数。
pvecm apiver
返回此节点上可用的集群加入 API 的版本。
pvecm create <clustername> [OPTIONS]
生成新的集群配置。如果没有给出链接,则默认本地 IP 地址为 link0 。
集群的名称。
单个 corosync 链路的地址和优先级信息。(最多支持 8 个链接;link0..link7)
此节点的节点 ID 。
该节点的投票数。
pvecm delnode <node>
从集群配置中删除一个节点。
集群节点的名称。
pvecm expected <expected>
告诉 corosync 预期投票的新值。
预期投票数
pvecm help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pvecm keygen <filename>
为 corosync 生成新的加密密钥。
输出文件名
pvecm mtunnel [<extra-args>] [OPTIONS]
由 VM / CT 迁移使用 - 请勿手动使用。
额外的参数作为数组
返回迁移 IP(如果已配置)
用于检测本地迁移IP的迁移网络
使用 tcp 套接字作为标准输入运行命令。IP 地址和端口首先通过此命令的标准输出打印,每个都在单独的行上。
pvecm nodes
显示集群节点的本地视图。
pvecm qdevice remove
移除已配置的 QDevice
pvecm qdevice setup <address> [OPTIONS]
设置 QDevice 的使用
指定外部 corosync QDevice 的网络地址
不在可能的危险操作上抛出错误。
用于连接外部 QDevice 的网络
pvecm status
显示集群状态的本地视图。
pvecm updatecerts [OPTIONS]
更新节点证书(并生成所有需要的文件/目录)。
强制生成新的 SSL 证书。
忽略错误(即当集群没有仲裁时)。
pvesr <COMMAND> [ARGS] [OPTIONS]
pvesr create-local-job <id> <target> [OPTIONS]
创建一个新的复制作业。
复制作业 ID 。ID 由来宾 ID 和作业编号组成,用连字符分隔,即 <GUEST>-<JOBNUM> 。
目标节点。
备注。
标志以禁用/停用该条目。
以 MBps(MB/s)为单位的浮点数的速率限制。
标记要删除的复制作业。该作业将删除所有本地复制快照。当设置为 full 时,它还会尝试删除目标上的复制卷。然后该作业会从配置文件中删除自己。
存储复制计划。该格式是 systemd 日历事件的子集。
供内部使用,用于检测来宾是否被盗。
pvesr delete <id> [OPTIONS]
将复制作业标记为删除。
复制作业 ID 。ID 由来宾 ID 和作业编号组成,用连字符分隔,即 <GUEST>-<JOBNUM> 。
将删除作业配置条目,但不会清理。
将复制的数据保留在目标位置(不要删除)。
pvesr disable <id>
禁用复制作业。
复制作业 ID 。ID 由来宾 ID 和作业编号组成,用连字符分隔,即 <GUEST>-<JOBNUM> 。
pvesr enable <id>
启用一个复制作业。
复制作业 ID 。ID 由来宾 ID 和作业编号组成,用连字符分隔,即 <GUEST>-<JOBNUM> 。
pvesr finalize-local-job <id> [<extra-args>] [OPTIONS]
完成复制作业。这将删除不同于 <last_sync> 的时间戳的所有复制快照。
复制作业 ID 。ID 由来宾 ID 和作业编号组成,用连字符分隔,即 <GUEST>-<JOBNUM>.
要考虑的卷 ID 列表。
上次成功同步的时间(UNIX 纪元)。如果未指定,则删除所有复制快照。
pvesr help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pvesr list
列出复制作业。
pvesr prepare-local-job <id> [<extra-args>] [OPTIONS]
准备开始复制作业。这是在复制开始之前在目标节点上调用的。此调用供内部使用,并在标准输出上返回一个 JSON 对象。该方法首先测试 VM 的<vmid> 是否驻留在本地节点上。如果是这样,则立即停止。之后,该方法扫描所有卷 ID 的快照,并删除所有带有不同于 <last_sync>的时间截的复制快照。它还会删除任何未使用的卷。为具有现有复制快照的所有卷返回一个带有布尔标记的哈希。
复制作业 ID 。ID 由来宾 ID 和作业编号组成,用连字符分隔,即 <GUEST>-<JOBNUM>.
要考虑的卷 ID 列表。
允许删除所有现有卷(空卷列表)。
上次成功同步的时间(UNIX 纪元)。如果未指定,则删除所有复制快照。
快照的名称。
要扫描过时卷的存储 ID 列表。
pvesr read <id>
读取复制作业配置。
复制作业 ID 。ID 由来宾 ID 和作业编号组成,用连字符分隔,即 <GUEST>-<JOBNUM> 。
pvesr run [OPTIONS]
此方法由 systemd-timer 调用并执行所有(或特定)同步作业。
复制作业 ID 。ID 由来宾 ID 和作业编号组成,用连字符分隔,即 <GUEST>-<JOBNUM> 。
在失败的情况下发送电子邮件通知。
将更详细的日志打印到标准输出。
pvesr schedule-now <id>
安排复制作业尽快开始。
复制作业 ID 。ID 由来宾 ID 和作业编号组成,用连字符分隔,即 <GUEST>-<JOBNUM> 。
pvesr set-state <vmid> <state>
设置在迁移时的作业复制状态。该调用供内部使用。它将接受作为 JSON 对象的作业状态。
VM 的(唯一)ID 。
作业状态为 JSON 解码的字符串。
pvesr status [OPTIONS]
列出此节点上所有复制作业的状态。
仅列出此来宾的复制作业。
pvesr update <id> [OPTIONS]
更新复制作业配置。
复制作业 ID 。ID 由来宾 ID 和作业编号组成,用连字符分隔,即 <GUEST>-<JOBNUM> 。
备注。
要删除的设置列表。
当前配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
标志以禁用/停用该条目。
以 MBps(MB/s)为单位的浮点数的速率限制。
标记要删除的复制作业。该作业将删除所有本地复制快照。当设置为 full 时,它还会尝试删除目标上的复制卷。然后该作业会从配置文件中删除自己。
存储复制计划。该格式是 systemd 日历事件的子集。
供内部使用,用于检测来宾是否被盗。
pveum <COMMAND> [ARGS] [OPTIONS]
pveum acl delete <path> --roles <string> [OPTIONS]
更新访问控制列表(添加或删除权限)。
访问控制路径
组列表。
允许传播(继承)权限。
角色列表。
API 令牌列表。
用户列表。
pveum acl list [FORMAT_OPTIONS]
获取访问控制列表(ACL)。
pveum acl modify <path> --roles <string> [OPTIONS]
更新访问控制列表(添加或删除权限)。
访问控制路径
组列表。
允许传播(继承)权限。
角色列表。
API 令牌列表。
用户列表。
pveum acldel
用于 pveum acl delete 的别名。
pveum aclmod
用于 pveum acl modify 的别名。
pveum group add <groupid> [OPTIONS]
创建新组。
没有可用的描述
没有可用的描述
pveum group delete <groupid>
删除组。
没有可用的描述
pveum group list [FORMAT_OPTIONS]
组索引。
pveum group modify <groupid> [OPTIONS]
更新组数据。
没有可用的描述
没有可用的描述
pveum groupadd
用于 pveum group add 的别名。
pveum groupdel
用于 pveum group delete 的别名。
pveum groupmod
用于 pveum group modify 的别名。
pveum help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pveum passwd <userid>
更改用户密码。
用户 ID
pveum pool add <poolid> [OPTIONS]
创建新池(pool,或资源池)。
没有可用的描述
没有可用的描述
pveum pool delete <poolid>
删除池。
没有可用的描述
pveum pool list [FORMAT_OPTIONS]
池索引。
pveum pool modify <poolid> [OPTIONS]
更新池数据。
没有可用的描述
没有可用的描述
删除 vms 或存储(而不是添加它)。
存储 ID 的列表。
虚拟机的列表。
pveum realm add <realm> --type <string> [OPTIONS]
增加身份验证服务器。
身份验证域 ID
自动创建用户(如果它们不存在)。
LDAP 基础域名
LDAP 绑定域名
CA 证书存储的路径
用户名区分大小写
客户端证书的路径
客户端证书密钥的路径
OpenID 客户端 ID
OpenID 客户端密钥
描述。
将此作为默认领域
AD 域名
用于用户同步的 LDAP 过滤器。
组的对象类。
用于组同步的 LDAP 基本域名。如果未设置,将使用 base_dn。
用于组同步的 LDAP 过滤器。
代表组名称的 LDAP 属性。如果未设置或找到,则 DN 的第一个值将用作名称。
OpenID 发行者的 URL
LDAP 协议模式。
LDAP 绑定密码。将存储在 /etc/pve/priv/realm/<REALM>.pw 。
服务器端口。
使用安全的 LDAPS 协议。已弃用:改用 mode 。
服务器 IP 地址(或 DNS 名称)
服务器 IP 地址(或 DNS 名称)
LDAPS TLS/SSL 版本。不推荐使用早于 1.2 的版本!
同步行为的默认选项。
逗号分隔的"键=值"对列表,用于指定哪个 LDAP 属性映射到哪个 PVE 用户字段。例如,要将 LDAP 属性 mail 映射到 PVE 的 email,请编写email=mail 。默认情况下,每个 PVE 用户字段由同名的 LDAP 属性表示。
使用二次验证。
领域类型。
LDAP 用户属性名称
用户的对象类。
用于生成唯一用户名的 OpenID 声明。
验证服务器的 SSL 证书
pveum realm delete <realm>
删除身份验证服务器。
身份验证域 ID
pveum realm list [FORMAT_OPTIONS]
身份验证域索引。
pveum realm modify <realm> [OPTIONS]
更新身份验证服务器设置。
身份验证域 ID
自动创建用户(如果它们不存在)。
LDAP 基础域名
LDAP 绑定域名
CA 证书存储的路径
用户名区分大小写
客户端证书的路径
客户端证书密钥的路径
OpenID 客户端 ID
OpenID 客户端密钥
描述。
将此作为默认领域
要删除的设置列表。
当前配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
AD 域名
用于用户同步的 LDAP 过滤器。
组的对象类。
用于组同步的 LDAP 基本域名。如果未设置,将使用 base_dn。
用于组同步的 LDAP 过滤器。
代表组名称的 LDAP 属性。如果未设置或找到,则 DN 的第一个值将用作名称。
OpenID 发行者的 URL
LDAP 协议模式。
LDAP 绑定密码。将存储在 /etc/pve/priv/realm/<REALM>.pw 。
服务器端口。
使用安全的 LDAPS 协议。已弃用:改用 mode 。
服务器 IP 地址(或 DNS 名称)
备用服务器 IP 地址(或 DNS 名称)
LDAPS TLS/SSL 版本。不推荐使用早于 1.2 的版本!
同步行为的默认选项。
逗号分隔的"键=值"对列表,用于指定哪个 LDAP 属性映射到哪个 PVE 用户字段。例如,要将 LDAP 属性 mail 映射到 PVE 的 email,请编写email=mail 。默认情况下,每个 PVE 用户字段由同名的 LDAP 属性表示。
使用二次验证。
LDAP 用户属性名称
用户的对象类。
验证服务器的 SSL 证书
pveum realm sync <realm> [OPTIONS]
将用户和(或)组从配置的 LDAP 同步到 user.cfg。注意:同步组的名称为 name-$realm ,因此请确保这些组不存在以防止覆盖。
身份验证域 ID
如果设置,则不写入任何内容。
立即启用新近同步的用户。
如果设置,则使用 LDAP 目录作为事实来源,删除未从同步中返回的用户或组。否则只会同步不存在的信息,不会删除或修改其他任何内容。
在删除配置中的用户或组的期间同步删除 ACL 。
选择要同步的内容。
pveum role add <roleid> [OPTIONS]
创建新的角色。
没有可用的描述
没有可用的描述
pveum role delete <roleid>
删除角色。
没有可用的描述
pveum role list [FORMAT_OPTIONS]
角色索引。
pveum role modify <roleid> [OPTIONS]
更新现有的角色。
没有可用的描述
没有可用的描述
|
|
需要选项:privs |
没有可用的描述
pveum roleadd
用于 pveum role add 的别名。
pveum roledel
用于 pveum role delete 的别名。
pveum rolemod
用于 pveum role modify 的别名。
pveum ticket <username> [OPTIONS]
创建或校验身份验证的票证。
用户名
使用 webauthn,半验证票证的格式发生了变化。新的客户端应该在这里传递 1 而不必担心旧格式。旧格式已弃用,并且将在 PVE-8.0 中停用。
用于二次验证的一次性密码。
验证票证,并检查是否用户有该 path(路径) 的访问 权限 。
|
|
需要选项:privs |
验证票证,并检查是否用户有该 path(路径) 的访问 权限 。
|
|
需要选项:path |
您可以选择使用该参数来传递领域。通常只将领域添加到用户名 <username>@<relam> 。
用户用于响应的已签署的 TFA 质询字符串。
pveum user add <userid> [OPTIONS]
创建新用户。
用户 ID
没有可用的描述
没有可用的描述
启用帐户(默认)。您可以将其设置为 0 以禁用该帐户。
帐户到期日期(自纪元以来的秒数)。0 意味着没有到期日期。
没有可用的描述
没有可用的描述
用于二次验证(yubico)的密钥。
没有可用的描述
初始密码。
pveum user delete <userid>
删除用户。
用户 ID
pveum user list [OPTIONS] [FORMAT_OPTIONS]
用户索引。
启用属性的可选过滤器。
包括组和令牌信息。
pveum user modify <userid> [OPTIONS]
更新用户配置。
用户 ID
没有可用的描述
|
|
需要选项:groups |
没有可用的描述
没有可用的描述
启用帐户(默认)。您可以将其设置为 0 以禁用该帐户。
帐户到期日期(自纪元以来的秒数)。0 意味着没有到期日期。
没有可用的描述
没有可用的描述
用于二次验证(yubico)的密钥。
没有可用的描述
pveum user permissions [<userid>] [OPTIONS] [FORMAT_OPTIONS]
检索给定用户/令牌的有效权限。
用户 ID 或完整 API 令牌 ID
仅转储特定的路径,而不是整个目录树。
pveum user tfa delete <userid> [OPTIONS]
从用户中删除 TFA 条目。
用户 ID
如果未提供 TFA ID,则所有 TFA 条件都将删除。
pveum user token add <userid> <tokenid> [OPTIONS] [FORMAT_OPTIONS]
为特定用户生成新的 API 令牌。注意:需要存储返回的 API 令牌值,因为之后无法检索!
用户 ID
用户特定的令牌标识符。
没有可用的描述
API 令牌的到期日期(自纪元以来的秒数)。0 意味着没有到期日期。
使用单独的 ACL 限制 API 令牌权限(默认),或授予相应用户的完全权限。
pveum user token list <userid> [FORMAT_OPTIONS]
获取用户 API 令牌。
用户 ID
pveum user token modify <userid> <tokenid> [OPTIONS] [FORMAT_OPTIONS]
更新特定用户的 API 令牌。
用户 ID
用户特定的令牌标识符。
没有可用的描述
API 令牌的到期日期(自纪元以来的秒数)。0 意味着没有到期日期。
使用单独的 ACL 限制 API 令牌权限(默认),或授予相应用户的完全权限。
pveum user token permissions <userid> <tokenid> [OPTIONS] [FORMAT_OPTIONS]
检索给定用户/令牌的有效权限。
用户 ID
用户特定的令牌标识符。
仅转储特定的路径,而不是整个目录树。
pveum user token remove <userid> <tokenid> [FORMAT_OPTIONS]
删除特定用户的 API 令牌。
用户 ID
用户特定的令牌标识符。
pveum useradd
用于 pveum user add 的别名。
pveum userdel
用于 pveum user delete 的别名。
pveum usermod
用于 pveum user modify 的别名。
vzdump help
vzdump {<vmid>} [OPTIONS]
创建备份。
您要备份的来宾系统的 ID 。
备份此主机上的所有已知来宾系统。
限制 I/O 带宽(KB/s)。
压缩转储文件。
将生成的文件存储到指定目录。
排除指定的来宾系统(假定 --all)
排除某些文件/目录(shell globs)。以 / 开头的路径锚定到容器的根目录,其他路径相对匹配到每个子目录。
设置 CFQ ionice 的优先级(CFQ ionice:I/O 调度器)
等待全局锁定的最长时间(分钟)。
指定何时发送电子邮件
应该接收电子邮件通知的电子邮件地址或用户的逗号分隔列表。
已弃用:使用 prune-backups 代替。每个来宾系统的最大备份文件数量。
备份模式。
仅在此节点上执行时运行。
当 N>0 时,使用 pigz 而不是 gzip。N=1 使用一半的核心,N>1 使用 N 作为线程数。
备份指定池中包含的所有已知来宾系统。
使用这些保留选项而不是存储配置中的保留选项。
静默。
根据 prune-backups 缩减较旧的备份。
使用指定的挂钩脚本。
排除临时文件和日志。
将 tar 写到标准输出,而不是文件。
停止该主机上正在运行的备份作业。
等待来宾系统停止的最长时间(分钟)。
将生成的文件存储到此存储中。
存储临时文件到指定目录。
Zstd 线程。N=0 使用一半的可用核心,N>0 使用 N 作为线程数。
ha-manager <COMMAND> [ARGS] [OPTIONS]
ha-manager add <sid> [OPTIONS]
创建新的 HA 资源。
HA 资源 ID 。这由资源类型以及资源指定的名称组成,用冒号分隔(例如:vm:100 / ct:100)。对于虚拟机和容器,您可以简单的使用 VM 或 CT 的 ID 作为快捷方式。
描述。
HA 组标识符。
当服务启动失败时,服务重定位尝试的最大次数。
启动失败后尝试在节点上重启服务的最大次数。
请求的资源状态。
资源类型。
ha-manager config [OPTIONS]
列出 HA 资源。
仅列出指定类型的资源
ha-manager crm-command migrate <sid> <node>
要求资源迁移(在线)到另一个节点。
HA 资源 ID 。这由资源类型以及资源指定的名称组成,用冒号分隔(例如:vm:100 / ct:100)。对于虚拟机和容器,您可以简单的使用 VM 或 CT 的 ID 作为快捷方式。
目标节点。
ha-manager crm-command relocate <sid> <node>
要求资源重定位到另一个节点。这会停止旧节点上的服务,并在目标节点上重启服务。
HA 资源 ID 。这由资源类型以及资源指定的名称组成,用冒号分隔(例如:vm:100 / ct:100)。对于虚拟机和容器,您可以简单的使用 VM 或 CT 的 ID 作为快捷方式。
目标节点。
ha-manager crm-command stop <sid> <timeout>
要求服务停止。
HA 资源 ID 。这由资源类型以及资源指定的名称组成,用冒号分隔(例如:vm:100 / ct:100)。对于虚拟机和容器,您可以简单的使用 VM 或 CT 的 ID 作为快捷方式。
超时(以秒为单位)。如果设置为 0 将会执行硬停止。
ha-manager groupadd <group> --nodes <string> [OPTIONS]
创建新的 HA 组。
HA 组标识符。
描述。
具有可选优先级的集群节点名称列表。
CRM 尝试在具有最高优先级的节点上运行服务。如果具有更高优先级的节点上线,CRM 会将服务迁移到该节点。启用 nofailback 可以防止这种行为。
绑定到受限组的资源只能在该组定义的节点上运行。
组类型。
ha-manager groupconfig
获取 HA 组。
ha-manager groupremove <group>
删除 HA 组配置。
HA 组标识符。
ha-manager groupset <group> [OPTIONS]
更新 HA 组配置。
HA 组标识符。
描述。
要删除的设置列表。
当前配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
具有可选优先级的集群节点名称列表。
CRM 尝试在具有最高优先级的节点上运行服务。如果具有更高优先级的节点上线,CRM 会将服务迁移到该节点。启用 nofailback 可以防止这种行为。
绑定到受限组的资源只能在该组定义的节点上运行。
ha-manager help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
ha-manager migrate
用于 ha-manager crm-command migrate 的别名。
ha-manager relocate
用于 ha-manager crm-command relocate 的别名。
ha-manager remove <sid>
删除资源配置。
HA 资源 ID 。这由资源类型以及资源指定的名称组成,用冒号分隔(例如:vm:100 / ct:100)。对于虚拟机和容器,您可以简单的使用 VM 或 CT 的 ID 作为快捷方式。
ha-manager set <sid> [OPTIONS]
更新资源配置。
HA 资源 ID 。这由资源类型以及资源指定的名称组成,用冒号分隔(例如:vm:100 / ct:100)。对于虚拟机和容器,您可以简单的使用 VM 或 CT 的 ID 作为快捷方式。
描述。
要删除的设置列表。
当前配置文件具有不同的 SHA1 摘要可用于防止更改。还可用于防止并发修改。
HA 组标识符。
当服务启动失败时,服务重定位尝试的最大次数。
启动失败后尝试在节点上重启服务的最大次数。
请求的资源状态。
ha-manager status [OPTIONS]
显示 HA 管理器状态。
详细输出。包括完整的 CRM 和 LRM 状态 (JSON)。
pve-firewall <COMMAND> [ARGS] [OPTIONS]
pve-firewall compile
编译和打印防火墙规则。这有助于测试。
pve-firewall help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pve-firewall localnet
打印有关本地网络的信息。
pve-firewall restart
重启 Proxmox VE 防火墙服务。
pve-firewall simulate [OPTIONS]
模拟防火墙规则。这不会模拟内核路由 表。相反,这只是假设从源区域到目标区域的路由是可能的。
目标 IP 地址。
目标端口。
源区域。
协议。
源 IP 地址。
源端口。
目标区域。
详细的输出。
pve-firewall start [OPTIONS]
启动 Proxmox VE 防火墙服务。
调试模式 - 置于前台
pve-firewall status
获取防火墙状态。
pve-firewall stop
停止防火墙。这将删除所有 Proxmox VE 相关的 iptable 规则。之后主机不受保护。
pvedaemon <COMMAND> [ARGS] [OPTIONS]
pvedaemon help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pvedaemon restart
重启守护进程(或在未运行时启动) 。
pvedaemon start [OPTIONS]
启动守护进程。
调试模式 - 置于前台
pvedaemon status
获取守护进程状态。
pvedaemon stop
停止守护进程。
pveproxy <COMMAND> [ARGS] [OPTIONS]
pveproxy help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pveproxy restart
重启守护进程(或在未运行时启动) 。
pveproxy start [OPTIONS]
启动守护进程。
调试模式 - 置于前台
pveproxy status
获取守护进程状态。
pveproxy stop
停止守护进程。
pvestatd <COMMAND> [ARGS] [OPTIONS]
pvestatd help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pvestatd restart
重启守护进程(或在未运行时启动) 。
pvestatd start [OPTIONS]
启动守护进程。
调试模式 - 置于前台
pvestatd status
获取守护进程状态。
pvestatd stop
停止守护进程。
spiceproxy <COMMAND> [ARGS] [OPTIONS]
spiceproxy help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
spiceproxy restart
重启守护进程(或在未运行时启动) 。
spiceproxy start [OPTIONS]
启动守护进程。
调试模式 - 置于前台
spiceproxy status
获取守护进程状态。
spiceproxy stop
停止守护进程。
pmxcfs [OPTIONS]
帮助选项:
显示帮助选项
应用选项:
打开调试消息。
不在后台守护服务器
强制本地模式(忽略 corosync.conf,强制仲裁)
该服务通常使用 systemd 工具集启动和管理。该服务称为 pve-cluster 。
systemctl start pve-cluster
systemctl stop pve-cluster
systemctl status pve-cluster
pve-ha-crm <COMMAND> [ARGS] [OPTIONS]
pve-ha-crm help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pve-ha-crm start [OPTIONS]
启动守护进程。
调试模式 - 置于前台
pve-ha-crm status
获取守护进程状态。
pve-ha-crm stop
停止守护进程。
pve-ha-lrm <COMMAND> [ARGS] [OPTIONS]
pve-ha-lrm help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pve-ha-lrm start [OPTIONS]
启动守护进程。
调试模式 - 置于前台
pve-ha-lrm status
获取守护进程状态。
pve-ha-lrm stop
停止守护进程。
pvescheduler <COMMAND> [ARGS] [OPTIONS]
pvescheduler help [OPTIONS]
获取指定命令的有关帮助。
显示一个指定命令的帮助
详细的输出格式。
pvescheduler start [OPTIONS]
启动守护进程。
调试模式 - 置于前台
pvescheduler status
获取守护进程状态。
pvescheduler stop
停止守护进程。
文件 /etc/pve/datacenter.cfg 是 Proxmox VE 的配置文件。它包含所有节点使用的集群范围内的默认值。
该文件使用简单的冒号分隔键/值格式。每行具有以下格式:
OPTION: value
文件中的空白行被忽略,以 # 字符开头的行被视为注释,也同样被忽略。
设置带宽 / IO 限制的各种操作。
克隆磁盘的带宽限制(以 KB/s 为单位)
默认带宽限制(以 KB/s 为单位)
迁移来宾的带宽限制(以 KB/s 为单位)(包括移动本地磁盘)
移动磁盘的带宽限制(以 KB/s 为单位)
从备份恢复来宾的带宽限制(以 KB/s 为单位)
选择默认的控制台查看器。您可以使用内置的 java 小程序(VNC;已弃用并映射到 HTML5)、外部的 virt-viewer 兼容的应用程序(SPICE)、基于 HTML5 的 VNC 查看器(noVNC)或基于 HTML5 的控制台客户端(xtermjs)。如果所选择查看器不可用(例如,用于 VM 的 SPICE 未激活),则回退为 noVNC 。
数据中心描述。显示在 Web 界面的数据中心的备注面板中。这在配置文件中保存为备注。
指定用于发送通知的电子邮件地址(默认为 root@$hostname)
设置 HA 集群的隔离模式。硬件模式需要在 /etc/pve/ha/fence.cfg 中配置有效的隔离设备。这两种模式同时使用。
|
|
hardware 和 both 是实验性质的半成品。 |
集群范围的 HA 设置。
描述了节点在断开或重启时处理 HA 服务的策略。Freeze 将始终冻结在关闭时仍位于节点上的服务,这些服务不会被 HA 管理器恢复。如果关闭的节点没有快速恢复(小于 1 分钟),故障转移不会将服务标记为已冻结,因此服务将被恢复到其他节点。conditional 根据关闭的类型自动选择,即在重启时冻结服务,但在断电时服务将保持原样,因此在大约 2 分钟之后恢复。当触发重启或关机时,迁移将尝试将所有正在运行的服务移动到另一个节点。只有在节点上不再有正在运行的服务时,断电过程才会继续。如果节点再次启动,服务将移回之前关闭的节点,至少要在没有发生其他迁移、重定位或恢复的情况下。
指定用于下载的外部 http 代理(例如: http://username:password@host:port/)
用于 vnc 服务器的默认键盘布局。
默认 GUI 语言。
用于自动生成 MAC 地址的前缀。
定义从 ha-manager 停止所有 VM 或任务等操作时最多启动多少个工作程序(每个节点)。
对于集群范围的迁移设置。
用于迁移的(子)网络的 CIDR。
默认情况下,迁移的流量使用 SSH 隧道加密。可以在安全、完全私有的网络上禁用此功能以提高性能。
默认情况下,使用 SSH 隧道进行迁移是安全的。对于安全的私有网络,您可以禁用它来加速迁移。已弃用,请改用 migration 属性!
u2f
覆盖 U2F AppId URL 。默认为 origin 。
覆盖 U2F Origin 。对于使用单个 URL 的单节点最有用。
webauthn 配置
依赖方 ID 。必须是没有协议、端口或位置的域名。更改此设置 将会 断开现有凭据。
Origin 网站。必须是一个 https:// URL(或 http://localhost)。应包含用户在浏览器中键入以访问 Web 界面的地址。更改此设置 可能 断开现有凭据。
依赖方名称。任何文本标识符。更改此设置 可能 断开现有凭据。
Proxmox VE 具有非常灵活的调度配置。它基于 systemd 时间日历事件格式
[更多信息请参阅 man 7 systemd.time]
。日历事件可用于引用单个表达式中的一个或多个时间点。
此类日历事件使用以下格式:
[day(s)] [[start-time(s)][/repetition-time(s)]] [日期] [[开始时间][/重复时间]]
此格式允许您配置一个作业应当运行的一组日期。您还可以设置一个或多个开始时间。它告诉复制调度程序,作业应该在什么时候开始运行。通过这些信息,我们可以创建一个在每个工作日晚上 10 点的作业:'mon,tue,wed,thu,fri 22' 可以缩写为:'mon..fri 22' ,最合理的日程安排可以通过这种方式非常直观地编写。
|
|
小时格式为 24 小时格式。 |
为了方便快捷的配置,可以为每个来宾设置一个或多个重复时间。它们表明复制是在开始时间本身和开始时间加上重复值的所有倍数上完成的。如果您想在上午 8 点开始复制并每 15 分钟重复一次,直到上午 9 点,您可以使用:'8:00/15'
在这里您可以看到,如果没有使用冒号(:)分隔小时,则该值将被解释为分钟。如果使用这种分隔方式,左边的值表示小时,右边的值表示分钟。此外,您可以使用 *(星号)匹配所有可能的值。
要获得更多想法,请查看 下面的更多范例 。
天使用缩写的英文版本指定:sun、mon、tue、wed、thu、fri 和 sat(周日、周一、周二、周三、周四、周五和周六)。您可以使用逗号分隔的列表代表多个日期。还可以通过指定以“..”分隔的开始和结束日期来设置一个日期范围,例如 mon..fri(周一到周五)。可以混合使用这些格式。如果省略,则假定为 '*'(星号)。
时间格式由小时和分钟间隔列表组成。小时和分钟通过冒号 ':' 进行分隔。小时和分钟都可以为一个值的列表和范围,使用与日期相同的格式。首先是小时,然后是分钟。小时不是必须的可以省略。在这个情况下,假定小时的值为 '*'(星号)。值的有效范围是 0-23(小时)和 0-59(分钟)。
| 日程安排字符串 | 替代 | 含义 |
|---|---|---|
mon,tue,wed,thu,fri |
mon..fri |
每个工作日的 0:00 |
sat,sun |
sat..sun |
仅在周末的 0:00 |
mon,wed,fri |
— |
仅在周一、周三和周五的 0:00 |
12:05 |
12:05 |
每天中午的 12:05 |
*/5 |
0/5 |
每五分钟 |
mon..wed 30/10 |
mon,tue,wed 30/10 |
周一、周二、周三的 30、40 和 50 分钟后每个整点 |
mon..fri 8..17,22:0/15 |
— |
每个工作日上午 8 点至下午 6 点之间以及晚上 10 点至晚上 11 点之间的每 15 分钟 |
fri 12..13:5/20 |
fri 12,13:5/20 |
周五的 12:05、12:25、12:45、13:05、13:25 和 13:45 |
12,14,16,18,20,22:5 |
12/2:5 |
每天 12:05 至 22:05,每 2 小时 |
* |
*/1 |
每分钟(最小间隔) |
| Amanda |
Amanda 备份 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
10080 |
|
PARAM |
tcp |
10080 |
| Auth |
Auth (identd) 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
113 |
| BGP |
边界网关协议(BGP)流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
179 |
|
BitTorrent
|
BitTorrent 3.1 及更高版本的 BitTorrent 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
6881:6889 |
|
PARAM |
udp |
6881 |
|
BitTorrent32
|
BitTorrent 3.2 及更高版本的 BitTorrent 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
6881:6999 |
|
PARAM |
udp |
6881 |
| CVS |
版本控制系统 pserver 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
2401 |
| Ceph |
Ceph 存储集群流量(Ceph 监视器、OSD & MDS 守护进程) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
6789 |
|
PARAM |
tcp |
3300 |
|
PARAM |
tcp |
6800:7300 |
|
Citrix
|
Citrix/ICA 流量 (ICA, ICA Browser, CGP) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
1494 |
|
PARAM |
udp |
1604 |
|
PARAM |
tcp |
2598 |
|
DAAP
|
数字音频存取协议流量 (iTunes, Rythmbox daemons) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
3689 |
|
PARAM |
udp |
3689 |
| DCC |
分布式校验和票据交换所垃圾邮件过滤机制 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
6277 |
|
DHCPfwd
|
转发的 DHCP 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
67:68 |
67:68 |
|
DHCPv6
|
DHCPv6 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
546:547 |
546:547 |
|
DNS
|
域名解析系统流量 (upd 和 tcp) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
53 |
|
PARAM |
tcp |
53 |
|
Distcc
|
分布式编译器服务 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
3632 |
| FTP |
文件传输协议(FTP) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
21 |
|
Finger
|
Finger 协议 (RFC 742) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
79 |
|
GNUnet
|
GNUnet 安全对等网络流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
2086 |
|
PARAM |
udp |
2086 |
|
PARAM |
tcp |
1080 |
|
PARAM |
udp |
1080 |
| GRE |
通用路由封装隧道协议 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
47 |
| Git |
Git 分布式修订控制流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
9418 |
| HKP |
OpenPGP HTTP 密钥服务器协议流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
11371 |
| HTTP |
超文本传输协议 HTTP (WWW) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
80 |
| HTTPS |
基于 SSL 的超文本传输协议 HTTPS(WWW) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
443 |
| ICPV2 | Internet 缓存协议 V2 (Squid) 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
3130 |
| ICQ |
AOL 即时消息流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
5190 |
| IMAP |
Internet 邮件存取协议(或称作:交互式邮件存取协议) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
143 |
| IMAPS |
基于 SSL 的 Internet 邮件存取协议(或称作:交互式邮件存取协议) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
993 |
| IPIP |
IPIP 封装流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
94 |
| IPsec |
IPsec 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
500 |
500 |
PARAM |
50 |
| IPsecah |
IPsec 身份验证 (AH) 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
500 |
500 |
PARAM |
51 |
| IPsecnat |
IPsec 流量和 NAT 遍历 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
500 |
|
PARAM |
udp |
4500 |
|
PARAM |
50 |
| IRC |
因特网中继聊天(IRC)流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
6667 |
| Jetdirect |
HP Jetdirect 打印 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
9100 |
| L2TP |
二层隧道协议流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
1701 |
| LDAP |
轻型目录访问协议流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
389 |
| LDAPS |
安全轻型目录访问协议流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
636 |
| MDNS |
多播 DNS |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
5353 |
| MSNP |
微软通知协议 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
1863 |
| MSSQL |
Microsoft SQL Server |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
1433 |
| Mail |
邮件流量(SMTP、SMTPS、Submission) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
25 |
|
PARAM |
tcp |
465 |
|
PARAM |
tcp |
587 |
| Munin |
Munin 联网资源监控流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
4949 |
| MySQL |
MySQL 服务器 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
3306 |
| NNTP |
NNTP 流量 (Usenet). |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
119 |
| NNTPS |
已加密 NNTP 流量 (Usenet) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
563 |
| NTP |
网络时间协议 (ntpd) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
123 |
| NeighborDiscovery
| IPv6 邻居请求、邻居和路由器通告 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
icmpv6 |
router-solicitation |
|
PARAM |
icmpv6 |
router-advertisement |
|
PARAM |
icmpv6 |
neighbor-solicitation |
|
PARAM |
icmpv6 |
neighbor-advertisement |
| OSPF |
OSPF 多播流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
89 |
| OpenVPN |
OpenVPN 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
1194 |
| PCA |
Symantec PCAnywere (tm) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
5632 |
|
PARAM |
tcp |
5631 |
| PMG |
Proxmox 邮件网关 Web 界面 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
8006 |
| POP3 |
POP3 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
110 |
| POP3S |
加密的 POP3 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
995 |
| PPTP |
点对点隧道协议 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
47 |
||
PARAM |
tcp |
1723 |
| Ping |
ICMP 回显请求 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
icmp |
echo-request |
|
PostgreSQL
|
PostgreSQL 服务器 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
5432 |
| Printer |
行式打印机协议打印 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
515 |
| RDP |
Microsoft 远程桌面协议流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
3389 |
| RIP |
路由信息协议(双向) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
520 |
| RNDC |
BIND 远程管理协议 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
953 |
| Razor |
Razor 反垃圾邮件系统 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
2703 |
| Rdate |
远程时间检索 (rdate) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
37 |
| Rsync |
Rsync 服务器 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
873 |
| SANE |
SANE 网络扫描 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
6566 |
| SMB |
Microsoft SMB 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
135,445 |
|
PARAM |
udp |
137:139 |
|
PARAM |
udp |
1024:65535 |
137 |
PARAM |
tcp |
135,139,445 |
| SMBswat |
Samba Web 管理工具 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
901 |
| SMTP |
简单邮件传输协议 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
25 |
| SMTPS |
加密的简单邮件传输协议 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
465 |
| SNMP |
简单网络管理协议 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
161:162 |
|
PARAM |
tcp |
161 |
| SPAMD |
Spam Assassin SPAMD 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
783 |
| SSH |
安全 shell 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
22 |
| SVN |
版本控制服务器 (svnserve) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
3690 |
| SixXS |
SixXS IPv6 部署和隧道代理 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
3874 |
|
PARAM |
udp |
3740 |
|
PARAM |
41 |
||
PARAM |
udp |
5072,8374 |
| Squid |
Squid Web 代理流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
3128 |
| Submission |
邮件信息提交流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
587 |
| Syslog |
Syslog 协议 (RFC 5424) 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
514 |
|
PARAM |
tcp |
514 |
| TFTP |
TFTP 协议流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
69 |
| Telnet |
Telnet 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
23 |
| Telnets |
基于 SSL 的 Telnet |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
992 |
| Time |
RFC 868 时间协议 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
37 |
| Trcrt |
Traceroute 路由追踪(最多 30 跳)流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
udp |
33434:33524 |
|
PARAM |
icmp |
echo-request |
| VNC |
用于 VNC 显示(0 - 99)的 VNC 流量。 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
5900:5999 |
| VNCL |
在监听模式下从 VNC 服务器到 VNC 查看器的 VNC 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
5500 |
| Web |
WWW 流量 (HTTP 和 HTTPS) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
80 |
|
PARAM |
tcp |
443 |
| Webcache |
Web 缓存/代理流量(端口 8080) |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
8080 |
| Webmin |
Webmin 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
10000 |
| Whois |
Whois (昵称,RFC 3912) 流量 |
| Action | 协议(proto) | 目标端口(dport) | 源端口(sport) |
|---|---|---|---|
PARAM |
tcp |
43 |
Markdown 是一个用于 Web 撰写人的文本到 HTML 转换工具。Markdown 允许您使用易于阅读、易于编写的纯文本格式进行编写,然后将其转换为结构上有效的 XHTML(或 HTML)。
Proxmox VE 的 Web 界面支持使用 Markdown 在节点和虚拟来宾备注中呈现富文本格式。
Proxmox VE 支持带有大多数 GFM 扩展(GitHub Flavored Markdown)的 CommonMark,例如表格或任务列表。
请注意,我们仅在此处描述基础知识,请在网络上搜索更广泛的资源,例如 https://www.markdownguide.org/
# 这是一个标题 h1 ## 这是一个标题 h2 ##### 这是一个标题 h5
使用 *text* 或 _text_ 表示 重点
使用 **text** 或 __text__ 表示 粗体、重量级的文本
组合也是可以的,例如:
_You **can** combine them_
您可以使用链接的自动检测,例如,https://forum.proxmox.com/ 会将其转换为可点击的链接。
您还可以控制链接的文本,例如:
Now, [括号中的部分是将作为链接的文本](https://forum.proxmox.com/).
使用 * 或 - 表示无序列表,例如:
* Item 1 * Item 2 * Item 2a * Item 2b
添加缩进可用于创建嵌套列表。
1. Item 1 1. Item 2 1. Item 3 1. Item 3a 1. Item 3b
|
|
有序列表的整数不需要正确,它们会自动编号。 |
任务列表使用空白的框 [ ] 表示未完成的任务,使用带有 X 的框表示已完成的任务。
例如:
- [X] First task already done! - [X] Second one too - [ ] This one is still to-do - [ ] So is this one
表格使用管道符号 | 分隔列,以及 - 将表格标题与表格主体分开,在这种分隔中,还可以设置文本对齐方式、使一列左对齐、居中对齐或右对齐。
| Left columns | Right columns | Some | More | Cols.| Centering Works Too | ------------- |--------------:|--------|------|------|:------------------:| | left foo | right foo | First | Row | Here | >center< | | left bar | right bar | Second | Row | Here | 12345 | | left baz | right baz | Third | Row | Here | Test | | left zab | right zab | Fourth | Row | Here | ☁️☁️☁️ | | left rab | right rab | And | Last | Here | The End |
请注意,您不需要将列与空格很好地对齐,但这会使编辑表格更容易。
您可以通过在行前加 > 来输入块引用,类似于纯文本的电子邮件。
> Markdown is a lightweight markup language with plain-text-formatting syntax, > created in 2004 by John Gruber with Aaron Swartz. > >> Markdown is often used to format readme files, for writing messages in online discussion forums, >> and to create rich text using a plain text editor.
您可以使用反引号来避免处理几个单词或段落。这对于避免代码或配置块被错误地解释为 markdown 很有用。
用单个反引号包围行的一部分允许编写行内代码,例如:
This hosts IP address is `10.0.0.1`.
对于跨越多行的代码块,您可以使用三个反引号来开始和结束这样的块,例如:
```
# This is the network config I want to remember here
auto vmbr2
iface vmbr2 inet static
address 10.0.0.1/24
bridge-ports ens20
bridge-stp off
bridge-fd 0
bridge-vlan-aware yes
bridge-vids 2-4094
```Version 1.3, 3 November 2008
Copyright © 2000, 2001, 2002, 2007, 2008 Free Software Foundation, Inc. http://fsf.org/
Everyone is permitted to copy and distribute verbatim copies of this license document, but changing it is not allowed.
The purpose of this License is to make a manual, textbook, or other functional and useful document "free" in the sense of freedom: to assure everyone the effective freedom to copy and redistribute it, with or without modifying it, either commercially or noncommercially. Secondarily, this License preserves for the author and publisher a way to get credit for their work, while not being considered responsible for modifications made by others.
This License is a kind of "copyleft", which means that derivative works of the document must themselves be free in the same sense. It complements the GNU General Public License, which is a copyleft license designed for free software.
We have designed this License in order to use it for manuals for free software, because free software needs free documentation: a free program should come with manuals providing the same freedoms that the software does. But this License is not limited to software manuals; it can be used for any textual work, regardless of subject matter or whether it is published as a printed book. We recommend this License principally for works whose purpose is instruction or reference.
This License applies to any manual or other work, in any medium, that contains a notice placed by the copyright holder saying it can be distributed under the terms of this License. Such a notice grants a world-wide, royalty-free license, unlimited in duration, to use that work under the conditions stated herein. The "Document", below, refers to any such manual or work. Any member of the public is a licensee, and is addressed as "you". You accept the license if you copy, modify or distribute the work in a way requiring permission under copyright law.
A "Modified Version" of the Document means any work containing the Document or a portion of it, either copied verbatim, or with modifications and/or translated into another language.
A "Secondary Section" is a named appendix or a front-matter section of the Document that deals exclusively with the relationship of the publishers or authors of the Document to the Document’s overall subject (or to related matters) and contains nothing that could fall directly within that overall subject. (Thus, if the Document is in part a textbook of mathematics, a Secondary Section may not explain any mathematics.) The relationship could be a matter of historical connection with the subject or with related matters, or of legal, commercial, philosophical, ethical or political position regarding them.
The "Invariant Sections" are certain Secondary Sections whose titles are designated, as being those of Invariant Sections, in the notice that says that the Document is released under this License. If a section does not fit the above definition of Secondary then it is not allowed to be designated as Invariant. The Document may contain zero Invariant Sections. If the Document does not identify any Invariant Sections then there are none.
The "Cover Texts" are certain short passages of text that are listed, as Front-Cover Texts or Back-Cover Texts, in the notice that says that the Document is released under this License. A Front-Cover Text may be at most 5 words, and a Back-Cover Text may be at most 25 words.
A "Transparent" copy of the Document means a machine-readable copy, represented in a format whose specification is available to the general public, that is suitable for revising the document straightforwardly with generic text editors or (for images composed of pixels) generic paint programs or (for drawings) some widely available drawing editor, and that is suitable for input to text formatters or for automatic translation to a variety of formats suitable for input to text formatters. A copy made in an otherwise Transparent file format whose markup, or absence of markup, has been arranged to thwart or discourage subsequent modification by readers is not Transparent. An image format is not Transparent if used for any substantial amount of text. A copy that is not "Transparent" is called "Opaque".
Examples of suitable formats for Transparent copies include plain ASCII without markup, Texinfo input format, LaTeX input format, SGML or XML using a publicly available DTD, and standard-conforming simple HTML, PostScript or PDF designed for human modification. Examples of transparent image formats include PNG, XCF and JPG. Opaque formats include proprietary formats that can be read and edited only by proprietary word processors, SGML or XML for which the DTD and/or processing tools are not generally available, and the machine-generated HTML, PostScript or PDF produced by some word processors for output purposes only.
The "Title Page" means, for a printed book, the title page itself, plus such following pages as are needed to hold, legibly, the material this License requires to appear in the title page. For works in formats which do not have any title page as such, "Title Page" means the text near the most prominent appearance of the work’s title, preceding the beginning of the body of the text.
The "publisher" means any person or entity that distributes copies of the Document to the public.
A section "Entitled XYZ" means a named subunit of the Document whose title either is precisely XYZ or contains XYZ in parentheses following text that translates XYZ in another language. (Here XYZ stands for a specific section name mentioned below, such as "Acknowledgements", "Dedications", "Endorsements", or "History".) To "Preserve the Title" of such a section when you modify the Document means that it remains a section "Entitled XYZ" according to this definition.
The Document may include Warranty Disclaimers next to the notice which states that this License applies to the Document. These Warranty Disclaimers are considered to be included by reference in this License, but only as regards disclaiming warranties: any other implication that these Warranty Disclaimers may have is void and has no effect on the meaning of this License.
You may copy and distribute the Document in any medium, either commercially or noncommercially, provided that this License, the copyright notices, and the license notice saying this License applies to the Document are reproduced in all copies, and that you add no other conditions whatsoever to those of this License. You may not use technical measures to obstruct or control the reading or further copying of the copies you make or distribute. However, you may accept compensation in exchange for copies. If you distribute a large enough number of copies you must also follow the conditions in section 3.
You may also lend copies, under the same conditions stated above, and you may publicly display copies.
If you publish printed copies (or copies in media that commonly have printed covers) of the Document, numbering more than 100, and the Document’s license notice requires Cover Texts, you must enclose the copies in covers that carry, clearly and legibly, all these Cover Texts: Front-Cover Texts on the front cover, and Back-Cover Texts on the back cover. Both covers must also clearly and legibly identify you as the publisher of these copies. The front cover must present the full title with all words of the title equally prominent and visible. You may add other material on the covers in addition. Copying with changes limited to the covers, as long as they preserve the title of the Document and satisfy these conditions, can be treated as verbatim copying in other respects.
If the required texts for either cover are too voluminous to fit legibly, you should put the first ones listed (as many as fit reasonably) on the actual cover, and continue the rest onto adjacent pages.
If you publish or distribute Opaque copies of the Document numbering more than 100, you must either include a machine-readable Transparent copy along with each Opaque copy, or state in or with each Opaque copy a computer-network location from which the general network-using public has access to download using public-standard network protocols a complete Transparent copy of the Document, free of added material. If you use the latter option, you must take reasonably prudent steps, when you begin distribution of Opaque copies in quantity, to ensure that this Transparent copy will remain thus accessible at the stated location until at least one year after the last time you distribute an Opaque copy (directly or through your agents or retailers) of that edition to the public.
It is requested, but not required, that you contact the authors of the Document well before redistributing any large number of copies, to give them a chance to provide you with an updated version of the Document.
You may copy and distribute a Modified Version of the Document under the conditions of sections 2 and 3 above, provided that you release the Modified Version under precisely this License, with the Modified Version filling the role of the Document, thus licensing distribution and modification of the Modified Version to whoever possesses a copy of it. In addition, you must do these things in the Modified Version:
Use in the Title Page (and on the covers, if any) a title distinct from that of the Document, and from those of previous versions (which should, if there were any, be listed in the History section of the Document). You may use the same title as a previous version if the original publisher of that version gives permission.
List on the Title Page, as authors, one or more persons or entities responsible for authorship of the modifications in the Modified Version, together with at least five of the principal authors of the Document (all of its principal authors, if it has fewer than five), unless they release you from this requirement.
State on the Title page the name of the publisher of the Modified Version, as the publisher.
Preserve all the copyright notices of the Document.
Add an appropriate copyright notice for your modifications adjacent to the other copyright notices.
Include, immediately after the copyright notices, a license notice giving the public permission to use the Modified Version under the terms of this License, in the form shown in the Addendum below.
Preserve in that license notice the full lists of Invariant Sections and required Cover Texts given in the Document’s license notice.
Include an unaltered copy of this License.
Preserve the section Entitled "History", Preserve its Title, and add to it an item stating at least the title, year, new authors, and publisher of the Modified Version as given on the Title Page. If there is no section Entitled "History" in the Document, create one stating the title, year, authors, and publisher of the Document as given on its Title Page, then add an item describing the Modified Version as stated in the previous sentence.
Preserve the network location, if any, given in the Document for public access to a Transparent copy of the Document, and likewise the network locations given in the Document for previous versions it was based on. These may be placed in the "History" section. You may omit a network location for a work that was published at least four years before the Document itself, or if the original publisher of the version it refers to gives permission.
For any section Entitled "Acknowledgements" or "Dedications", Preserve the Title of the section, and preserve in the section all the substance and tone of each of the contributor acknowledgements and/or dedications given therein.
Preserve all the Invariant Sections of the Document, unaltered in their text and in their titles. Section numbers or the equivalent are not considered part of the section titles.
Delete any section Entitled "Endorsements". Such a section may not be included in the Modified Version.
Do not retitle any existing section to be Entitled "Endorsements" or to conflict in title with any Invariant Section.
Preserve any Warranty Disclaimers.
If the Modified Version includes new front-matter sections or appendices that qualify as Secondary Sections and contain no material copied from the Document, you may at your option designate some or all of these sections as invariant. To do this, add their titles to the list of Invariant Sections in the Modified Version’s license notice. These titles must be distinct from any other section titles.
You may add a section Entitled "Endorsements", provided it contains nothing but endorsements of your Modified Version by various parties—for example, statements of peer review or that the text has been approved by an organization as the authoritative definition of a standard.
You may add a passage of up to five words as a Front-Cover Text, and a passage of up to 25 words as a Back-Cover Text, to the end of the list of Cover Texts in the Modified Version. Only one passage of Front-Cover Text and one of Back-Cover Text may be added by (or through arrangements made by) any one entity. If the Document already includes a cover text for the same cover, previously added by you or by arrangement made by the same entity you are acting on behalf of, you may not add another; but you may replace the old one, on explicit permission from the previous publisher that added the old one.
The author(s) and publisher(s) of the Document do not by this License give permission to use their names for publicity for or to assert or imply endorsement of any Modified Version.
You may combine the Document with other documents released under this License, under the terms defined in section 4 above for modified versions, provided that you include in the combination all of the Invariant Sections of all of the original documents, unmodified, and list them all as Invariant Sections of your combined work in its license notice, and that you preserve all their Warranty Disclaimers.
The combined work need only contain one copy of this License, and multiple identical Invariant Sections may be replaced with a single copy. If there are multiple Invariant Sections with the same name but different contents, make the title of each such section unique by adding at the end of it, in parentheses, the name of the original author or publisher of that section if known, or else a unique number. Make the same adjustment to the section titles in the list of Invariant Sections in the license notice of the combined work.
In the combination, you must combine any sections Entitled "History" in the various original documents, forming one section Entitled "History"; likewise combine any sections Entitled "Acknowledgements", and any sections Entitled "Dedications". You must delete all sections Entitled "Endorsements".
You may make a collection consisting of the Document and other documents released under this License, and replace the individual copies of this License in the various documents with a single copy that is included in the collection, provided that you follow the rules of this License for verbatim copying of each of the documents in all other respects.
You may extract a single document from such a collection, and distribute it individually under this License, provided you insert a copy of this License into the extracted document, and follow this License in all other respects regarding verbatim copying of that document.
A compilation of the Document or its derivatives with other separate and independent documents or works, in or on a volume of a storage or distribution medium, is called an "aggregate" if the copyright resulting from the compilation is not used to limit the legal rights of the compilation’s users beyond what the individual works permit. When the Document is included in an aggregate, this License does not apply to the other works in the aggregate which are not themselves derivative works of the Document.
If the Cover Text requirement of section 3 is applicable to these copies of the Document, then if the Document is less than one half of the entire aggregate, the Document’s Cover Texts may be placed on covers that bracket the Document within the aggregate, or the electronic equivalent of covers if the Document is in electronic form. Otherwise they must appear on printed covers that bracket the whole aggregate.
Translation is considered a kind of modification, so you may distribute translations of the Document under the terms of section 4. Replacing Invariant Sections with translations requires special permission from their copyright holders, but you may include translations of some or all Invariant Sections in addition to the original versions of these Invariant Sections. You may include a translation of this License, and all the license notices in the Document, and any Warranty Disclaimers, provided that you also include the original English version of this License and the original versions of those notices and disclaimers. In case of a disagreement between the translation and the original version of this License or a notice or disclaimer, the original version will prevail.
If a section in the Document is Entitled "Acknowledgements", "Dedications", or "History", the requirement (section 4) to Preserve its Title (section 1) will typically require changing the actual title.
You may not copy, modify, sublicense, or distribute the Document except as expressly provided under this License. Any attempt otherwise to copy, modify, sublicense, or distribute it is void, and will automatically terminate your rights under this License.
However, if you cease all violation of this License, then your license from a particular copyright holder is reinstated (a) provisionally, unless and until the copyright holder explicitly and finally terminates your license, and (b) permanently, if the copyright holder fails to notify you of the violation by some reasonable means prior to 60 days after the cessation.
Moreover, your license from a particular copyright holder is reinstated permanently if the copyright holder notifies you of the violation by some reasonable means, this is the first time you have received notice of violation of this License (for any work) from that copyright holder, and you cure the violation prior to 30 days after your receipt of the notice.
Termination of your rights under this section does not terminate the licenses of parties who have received copies or rights from you under this License. If your rights have been terminated and not permanently reinstated, receipt of a copy of some or all of the same material does not give you any rights to use it.
The Free Software Foundation may publish new, revised versions of the GNU Free Documentation License from time to time. Such new versions will be similar in spirit to the present version, but may differ in detail to address new problems or concerns. See http://www.gnu.org/copyleft/.
Each version of the License is given a distinguishing version number. If the Document specifies that a particular numbered version of this License "or any later version" applies to it, you have the option of following the terms and conditions either of that specified version or of any later version that has been published (not as a draft) by the Free Software Foundation. If the Document does not specify a version number of this License, you may choose any version ever published (not as a draft) by the Free Software Foundation. If the Document specifies that a proxy can decide which future versions of this License can be used, that proxy’s public statement of acceptance of a version permanently authorizes you to choose that version for the Document.
"Massive Multiauthor Collaboration Site" (or "MMC Site") means any World Wide Web server that publishes copyrightable works and also provides prominent facilities for anybody to edit those works. A public wiki that anybody can edit is an example of such a server. A "Massive Multiauthor Collaboration" (or "MMC") contained in the site means any set of copyrightable works thus published on the MMC site.
"CC-BY-SA" means the Creative Commons Attribution-Share Alike 3.0 license published by Creative Commons Corporation, a not-for-profit corporation with a principal place of business in San Francisco, California, as well as future copyleft versions of that license published by that same organization.
"Incorporate" means to publish or republish a Document, in whole or in part, as part of another Document.
An MMC is "eligible for relicensing" if it is licensed under this License, and if all works that were first published under this License somewhere other than this MMC, and subsequently incorporated in whole or in part into the MMC, (1) had no cover texts or invariant sections, and (2) were thus incorporated prior to November 1, 2008.
The operator of an MMC Site may republish an MMC contained in the site under CC-BY-SA on the same site at any time before August 1, 2009, provided the MMC is eligible for relicensing.
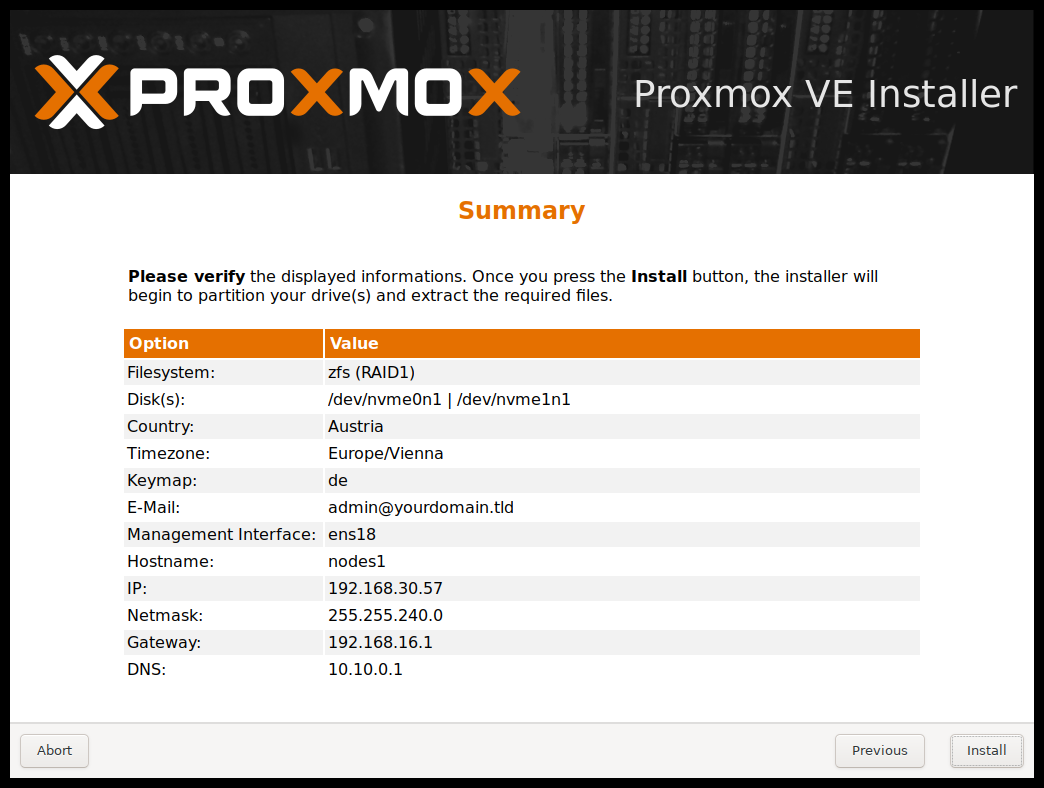
{kind=link}